
Starting from this week, we are going to share one video per week of the amazing talks that were presented at the Gerrit User Summit 2017 in London.
In addition to the YouTube recording, we are during the extraction of the text and publishing it together with the relevant pictures taken from the presenter’s slides, so that people can start digesting the content at small bites.
This week talk is Patrick Hiesel’s presentation on how Gerrit multi-tenant and multi-master setup has been implemented in Google.
Gerrit@Google – Patrick Hiesel, Google
My name is Patrick, and I am going to talk about the setup of Gerrit we are running at Google. I wanted to take you on a journey starting with Gerrit that you all know and making it the system we run at Google, step-by-step; and at the end will have a multi-master and multi-tenant system.
Multi-what?
Multi-tenant is the ability to serve multiple hosts from the same single Java process. Imagine like the same JVM task serving gerrit-review.googlesource.com and gerrit-chromium.googlesource.com.
Multi-master is the ability to have multiple Gerrit servers all over the world. You can contact any one of them for reads and writes.
Most systems have read replicas, which is straightforward, but write replicas is where the juicy meat is.
Multi-tenant
We have gerrit-review.googlesource.com, based on OpenSource Gerrit that you can download right now and have it running hopefully under ten minutes. That is core-Gerrit, and it depends on three things:
- JGit: for all the Git stuff
- Multiple indexes for the accounts, changes, and other stuff
- Caches
All these three components are based on the filesystem in one way or the other.
Now you have a friend that is accessing go-review.googlesource.com, what are you going to do?
The most natural solution is to start another Gerrit instance for it. You can have all of them on one machine, you can give them different ports, very easy, and in the end, they’ll be all based on the filesystem.
All those Gerrit instances do not need to talk to each other; they can just be separate instances operating on separate ports. This is not a multi-tenant system, but only different Gerrit instances on the same host.

You can add another layer on top of it: a servlet engine which receives all the traffic, check which host the traffic is for, and just delegate to the individual host.
To take one step further, have that selection filter doing that for you. Gerrit has a daemon that runs all the functionalities. You can integrate that daemon into the incoming servlet filter. When you can get a request for go-review.googlesource.com and I do not have where to allocate it, you can just launch it, instantiate all the objects and then run the traffic from there. Also, unload instances would work in the same way.
The Gerrit server engine and the selection filter can run in a single JVM.
How Gerrit can conquer the world
So you have a master here in Europe, and you have got one friend on the west coast in the US. He says: “Oh your Gerrit is so slow I have no idea why and I wish I could move to GitHub.” You say: “Hold on, I can do better than that!” and so you put a new master for the person on West coast.
So the key to that is the replication and comes in two sets:
- Objects that you have to replicate related to all the Git data. JGit is putting objects into the disk, and these are the data you need to replicate correctly and fast.
- Other stuff that should replicate and fast to provide a pleasant user experience but it really can be best-effort. That is the indexes and the caches.
If it is okay for your master having a 200/600 msec additional latency, then do not replicate the caches. You can have a cold cache in Singapore or the US, and you can reread them without problems.
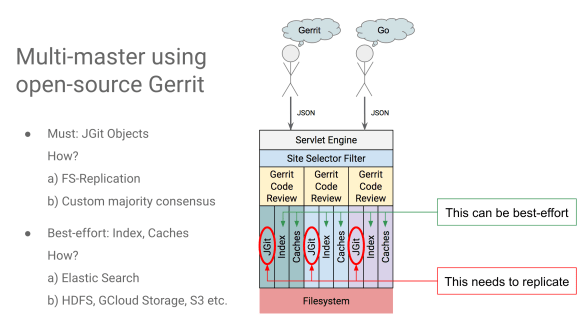
For the index, replication can be best-effort, but you should make an effort to replicate them. It is still nonetheless a mandatory requirement. One way to achieve that is to use ElasticSearch, but other index implementations that give indexes replication can be used as well.
Multi-tenant and Multi-master together
We talked about a multi-tenant system and then replicate them globally, so we have now a multi-tenant and multi-master system, actually pretty close to what we run at Google.
That is the stack that we run in total. We have a selection filter and two other filters to decide what the traffic is directed. We are also based on JGit, no magic there, we have index and caches we replicate, all our systems are based on filesystem and BigTable.
Some “magic” happens at the Git layer at Google because that is where all the majority consensus across all the cells. When you are pushing anything that is Git and, with NoteDb, anything that is a review is in the repository as well, the system tries to reach the majority of the cells and write the objects to them. When that is acknowledged, you get a green light on the push.
Majority consensus also means that you have it only in so many cells, but don’t have it on all the cells all the times. Some of the replication is happening in the long tail, by replication events eventually get acknowledged by the cells, and then they get written to all the masters.
Our indexes and caches are also replicated, but some of them are just in-memory and a component that gets replicated on top of BigTable.
Redundancy everywhere.
We run five data-centers across three continents (Americas, Europe, Asia-Pacific), with precisely the stack we just saw which gives us a good latency for most of our users worldwide.
Let’s talk about load balancing. We have a system that is multi-master and multi-tenant, and any of the tasks can serve any requests, but just because it can, doesn’t mean that it should.
Maybe it has in cold memory caches, or it is in Singapore, and you are in the US; so the question is what if the biggest machine is not big enough and we want to optimize it?

The idea is that we want to reduce latency that comes out of cold caches and minimize the time the site takes to load.
So you have a request for gerrit-review.googlesource.com, and your instance has a cold cache, and you need to read from disk to memory to serve the request.
You have a fleet of 300 tasks available but you want to serve gerrit-review.googlesource.com from only just five of them. If you serve 300 requests from 300 tasks in a round-robin manner, you pay the latency to load data from disk to memory for every single request. And the second motivation is that you want to distribute the load.
We want a system that can dynamically scale with changing load patterns. We want a system that can optimise the caches, to send a request for a site/repo to the few number of servers and tasks based on two conditions:
- serve from one machine as long as it fits on it
- server from more machines if you really have to
Level-1 load balancer
In the stack at Google, you saw two load balancing levels. What you see down in the picture is the Gerrit tasks, that contains all the software layers we talked about. We have a user that triggers JSON calls from the browser, with PolyGerrit. The first thing that the JSON request is hitting is the L1 load balancer. The primary routing of your request is by geographic proximity. We have five datacentres at Google; the L1 load balancer picks the one with the lowest latency. When the request goes into the data-center, we have another load balancer which is the one I’ll talk about more, because this is the one where the Gerrit specifics happen.
One thing that L1 is doing as well is managing the spillover of traffic. When a datacentre says “I can handle up to 100 QPS” the L1 load balancer starts redirecting traffic to other datacentres should that threshold be reached.
Level 2 load balancer
Let’s dive into L2 load balancer, we want to know how much traffic we are getting into each Gerrit task, and we want to know in the load balancer where the single request should go, and we want to know that fast!
We added three new components to the architecture:
- An element to redirect tasks and provide functionality and can report the load we are handling right now. When I mean load it can be anything: QPS (Queries Per Second), metrics, we just want to know from the tasks: what is your current load? We have a system called slicer, which I am going to talk about in a second and it’s added there in the picture.
- A second component we are adding to the load balancer, with a query interface that responds to the following question: “we have a request for gerrit-googlesource.com, where should it go?”. All of that should be done in memory and should be regularly updated with the new elements in the background so that we don’t add another component of latency by having another RPC.
- A third part is coordinating everything and is called the assigner, and it takes all the load metrics that we reported generates new assignments and gives them to the query interface.
Introducing the slicer
We have a system that is called slicer. There is a very nice paper that I can recommend, published last fall, that talks about that. It is a load balancer that works on custom keys and can do automatic re-sharding based on new traffic patterns. When your nodes receive more traffic, the slicer will automatically distribute the load or re-shard the whole system. That is a suitable method for local sharding that happens within the data center; we do not use it for inter-datacentre because that is all done via geographic proximity.

The system works with 64-bit keys and gives you a lot of combinations. You can slice the keyspace, for instance, in 400 slices. That gives you 400 ranges, and you can take any of them and assign to one or more tasks. The hostname is my key for instance, and then you hash it, and you end up in the first slice that gets assigned to a single task with an index zero.
What can we do if the load changes? Let’s say that you have key zero that gets assigned to the first range and then the traffic changes. We have two options.
- The first option is to assign more tasks, let’s say task 6, and then you round-robin between task 0 and task 6.
- The second option is splitting into 600 or 800 slides to get a better grip on each of the keys.

We can also do that, and then we factor our the load for gerrit-review.googlesource.com and go-review.googlesource.com, and we put them into different hosts.
We do that for Gerrit, and one of the things we want for Gerrit is when we have to split per-host traffic with the affinity on the repository. Caches are based on the project, and because gerrit-android.googlesource.com is a massive host served from a lot of tasks, we don’t want all these tasks just to serve all general traffic for android. We want tasks serving android/project1 from here and android/project2 from there so that we optimise the second layer of caches.
What we do is to mangle these keys together based on both host and project. Before, all these chromium keyspace was served from a single host; when the load increases we just split the keys into Chromium source and the rest of metadata. This is the graph that we obtained after we implemented the load balancer. The load we have on each of the tasks in a single data center is represented by a line with a different color. What you can see is that are all nicely aligned, so that each task is serving precisely the same amount of traffic which is what you want.

What if one project is 100 times the size of the others and we are optimizing on queries per second? The system will just burn resources fast. We had that situation in May, we saw the graphs, and we said “all good, looks nice”; however, people were sending e-mails and raising bugs wondering if the system were serving any traffic at all or if it were down completely.
It turned out that Android had a lot of large repositories, regarding the number of references, and the objects. We were just optimizing the queries per second, but some of the tasks were doing just CPU intensive work, where others were happy with it. Some of them were burning CPU in flames, and others were fine.
So we moved out of the per-request affinity, and we modified the per-repository sharding to optimise all of this.
Warm vs. Cold Cache
There is an extra in the system that is pre-warming caches. What the load balancer can do for you is to tell you that traffic is changing and I need to reconsider how to split the load on the system. For each of the tasks is going to tell “I’m going to give you traffic for gerrit-review.googlesource.com” with a notice of 30 seconds. That time you can use for pre-warm caches.
That is especially nice if you restart your tasks because all the associated in-memory cache gets flushed. The load balancer tells you “oh, this is the list of the tasks I need” and then you can get them all and pre-warm their caches. This graph shows the impact of the cache warmer on our system, on the 99.9% requests latency, really on the long tail of requests latency. That looks nice because we brought the latency down by a third.
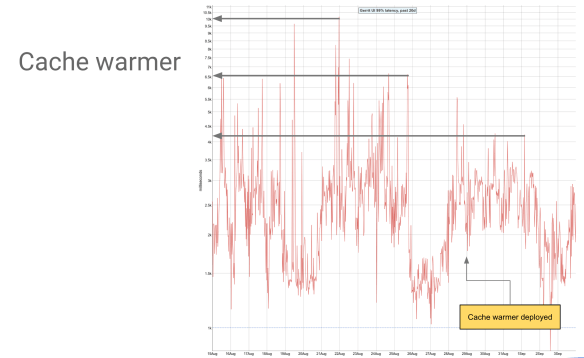
What is a task start dying during peak traffic? Imagine that the load balancer is saying “You’re going to handle this” and two seconds later says “I have to reconsider, you’re going to handle that instead”. Again you’re going to watch your system burning on fire, because you’re serving peak traffic and then you’re running close to 100% CPU. That situation causes the load balancer loading and unloading tasks all the time, which is inconvenient. The way we work around this is to make this cache warming a best-effort activity. You can do it if you’re below 50% CPU when you have time to do fancy things, but when you receive peak traffic, you just handle peak traffic without any optimisation made.
Multi-master and multi-tenant outside of Google
The question is: how do we do that in a non-Google setup?
There are plenty of options.
With the new Gerrit release in 2.15, we introduced to a new URL scheme, which includes the project name in the URL. Previously you had gerrit-review.googlesource.com/c/NNN and there was no way to directly know which project this is for and no way to do that load balancing that we just saw.
What we did in 2.15 is just add the project before that, so that extraction for both host and project can be made in a simpler way. You could do the same even before v2.15 but you needed a secondary index lookup, which most opensource load-balancers such as HAProxy or NGINX did not support. And of course, there are lots of products like Google Cloud load balancer, and others that you can use to achieve the same thing.
Wrap-up
We went through a journey where we took OpenSource Gerrit, we added sites selection and got a multi-tenant Gerrit.
Then we took this multi-tenant Gerrit, added replication and obtained multi-master Gerrit.
And then we took that with load balancing and lots of failures and lots of fixes, and we got pretty much the Gerrit that we run at Google, which brings me to the end of this talk 🙂
Q&A
Q: How strategic is Gerrit@Google? Do you have any other code-review systems? If yes, how is used Gerrit vs. the others?
We have another code-review system for internal use only, and Gerrit is used whenever we are doing OpenSource stuff, so for GoLang, Chromium, Android, Gerrit, and whenever the Google Team wants to collaborate with other OpenSource users, or in general with users that are not sitting at Google.
Historically the source at Google was developed in Perforce, and we ported from that to a home-based system called Piper. Around that, we have a tooling ecosystem which is internal. In parallel to that, Google started to do a lot of projects that have nothing to do with the internal search engine and available outside. What we see is that a lot of projects started at Google from scratch were thinking about “what system should we use?”. Many people said: “well, we’re going just to use Git because that’s what we know and we like, ” and when they needed code-review for Git they ended up with us. Gerrit and Git are very popular inside Google.
Q. You have two levels of load balancer. The first one is the location, and the second one is to decide what to do inside the data-center. What about if a location is off? Maybe is not fully off-line but has big problems, or has a very low-percentage of consensus, and some of the locations have not the “latest and greatest” of the repo. Possibly a location that should be “inconvenient for me” actually has the data I want.
You’re talking about replication layer where you have the objects in one location but not in the other. Our replication latency is in the order of seconds, but it may happen that one location is just really slow in getting the objects. That happens from time to time, and we have metrics that says what the replication lag is accounted for. When it exceeds a threshold we just shut the data-center off, which means cut-off the traffic, the data-center will not receive user-traffic anymore but it will still be able to get the replication done, and when the decrease the objects we need to replicate we can send the traffic again.
Cutting off the traffic is happing at the L1 load balancer where we said “don’t send anything there”.
Q. Do all the tasks have the same setup? Or do have a sort of micro-service architecture inside where some of the tasks are more dedicated to this type of operations and other for another type. Serving data from memory in one thing, but calculating diff change is a different type of task.
Not in general. All of our tasks are the same, except for checking access control permissions. We do not go through the whole Gerrit stack but we have only this little task that knows how the project config works and is going to tell us yes or no.

Interesting follow-up discussion on the Gerrit mailing list https://groups.google.com/forum/#!topic/repo-discuss/lwnP-abIhs0