My name is Martin Fick and I work at Qualcomm as Gerrit Administrator and I have one of the key historical Gerrit Maintainers since its very beginning.
I am going to talk about my experience in introducing a truly Multi-Master Gerrit setup at Qualcomm and learn about the findings and the experiences we made to make that happen.
Let’s start with a question so that we can make this session very interactive from the start.
Q: Who would like to have multi-master in Gerrit Code Review? Why would you need it on your server? Failover? High-availability? Both?
A: All of that but also latency. We have developers all around the world, and we would have at least two datacentres, one in the States and another one in Europe, we were looking for a multi-site multi-master to descreen latency between the sites.
A: (Luca Milanesio – GerritForge). Scalability and elasticity that allows to grow and shrink the instances based on the incoming traffic. Additionally, we would like to have zero downtime and rolling upgrades without stopping the services when moving between minor versions of Gerrit.
Q: (Han-Wen Nienhuys – Google) Let me reverse the question: who is running multi-master and would like to have a single master?
A: (Dave Borowitz – Google) I would love if we had a single server that was powerful enough to serve all our traffic and no latency and we had not had to deal with slow database backends and replication lags between sites.
Q: Does anybody need multi-master? How are you surviving today if you needed it?
A: Right now we maintain a second master server for DR purposes, is a passive standby backup server. If our master went down, we would have to failover to it.
A: We would need multi-master soon. Currently, we are experimenting the HA-plugin as a fallback solution, but we are working towards achieving multi-master so that we can scale up, which is mainly our primary concern here.
Gerrit Multi-Master requirements
There are needs that I hear from the audience, high-availability, scalability. Not necessarily the same requirements and I believe that multi-master would address some of those. What’s important is that everyone is focussing on their needs and think about how they can approach those first instead of going to the “big everything” solution.
We have high-availability as an issue somewhere, so we want better availability. We have some scalability issues as well. We do have some site issue at times but we most generally deal with those through slaves all over the world, between 50 and 100 and we primarily have one data-center in San Diego USA. If that goes down, nobody is getting anything done even if Gerrit is up, that makes failing over to other sites not particularly useful right now.
Our current focus is on better availability and better scalability at one site.
Scalability problems at Qualcomm
We have a pretty hefty load, we have around 6k projects, but our load is enormous on a few large projects. They are not massive projects but they are significant from the standpoint of having many changes on them, and there are a lot of users using those projects. Mainly a few kernel projects are used, and even if there are many other little projects, most of the users are pushing to those single projects.

We are a single tenant server, so we are primarily dealing with that. Other people need other Gerrit servers, and they manage their own, but at the moment we don’t have to deal with those. However, if we had a more scalable system, then I believe multi-tenancy would become the next problem on the horizon. If I had a great scalable system why am I creating this instances here and there I would instead put all of them on the central system so that I can manage one system. But then I would have the problem that Gerrit doesn’t currently handle multi-tenancy well. Maybe is because we don’t have a multi-master system and then we are not ready to put everything on one server anyway. If we are starting having a multi-master solution, then multi-tenancy is then something that would become more interesting.
On one server we have around 6k projects, the main project has about 1/2M refs, and we have in total 2.3M changes on the entire server.
I like to break down the scaling topic into two different ideas: horizontal scaling and vertical scaling. In our area, we need to scale vertically more, while horizontally is where you have lots of projects and users and vertical they are more concentrated on a few projects.
Stairway to Gerrit Multi-Master
Here is what we decided to do and we decided to build it incrementally. These are the four phases in which we have approached it.

Step #1: Active/Passive
We have an active/passive standby, and we started doing regular failover. Let’s face it, if you have a failover machine that you probably have never failed over to, it would probably not work.
We have so much software around the Gerrit ecosystem, we have a lot of scripts, cronjobs and things that run on our server, and they use a lot of software, there are a lot of Python hooks and stuff like that.
All that software gets updated. If the failover machine is not updated through the same process and tested, there could be missing dependencies, wrong package versions, etc. Maybe some hacks or links on the filesystem that is pointing over here and not over there or maybe filesystem positions are different and things like that.
Before even dreaming about multi-master you need to have a system to have your server systems consistent. If you don’t think that your organization can do that and make two systems precisely the same, you are not going to be anywhere near ready to start doing multi-master. If you are a large organization that has a lot of history, it’s a more significant challenge. If you are starting from scratch it is a lot easier, think about that from the start: how can I focus on repeatability and deploying the same stack of software to multiple servers, and then concentrate on failing over.
Sometimes this year around February/March, we started failing over, and now we are trying to fail over weekly. We have been doing that for getting the Team used to it, to ensure that our processes work.
Step #2: Active/Hot Standby
Then we moved to hot-standby. The difference here is that the passive node had all the software in place but was not necessarily running. So now we just started the other server, but only nobody was pointing to it. The active standby gives you the opportunity to test the software you have around your Gerrit master. If you have hooks or cronjobs, try to run them on the failover server, even if it is not the active master. Do you have the coordination needed? Do you have locks in place? If you are doing repository repacking, can you do it on both servers at the same time? Do they conflict with each other?
The assumption is that you have a shared repository on the backend such as an NFS and thus activities like repacking need that coordination. And you need that stuff to work before you can go to multi-master.
Step #3: Active/Active with Round-Robin DNS (low tech)
The third step which is where we are at is active-active. We chose this as a simple low-tech and easy to backup solution: round-robin DNS. It sucks from a load-balancing standpoint and for the failover recovery, but it gets us having traffic going to two servers. We have been running that for quite some time now, 15h!
Step #4: Active/Active with Load Balancer(s)
And the next step is of course to have a load balancer. We have a load-balancer setup that we use for slaves. It is much harder to back out because you have to set IPs to have DNS in place pointing to them, but we plan to transition to that.
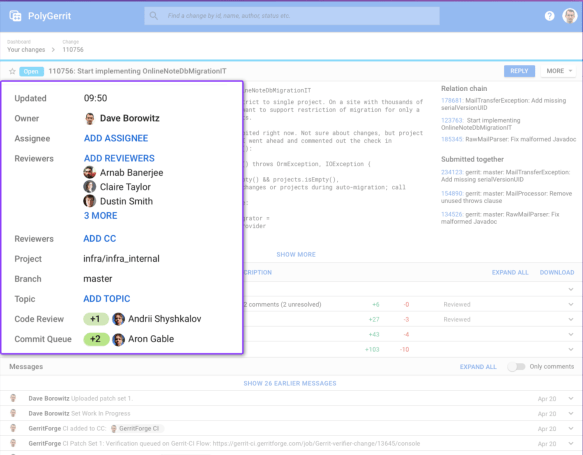
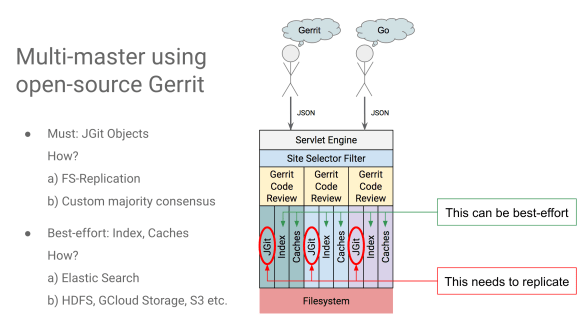
What Gerrit data to share in a multi-master setup?
In a single-site Gerrit multi-master setup, you necessarily need to have shared Git repositories, you don’t have to share your H2 caches because you need them on each of them and then the ReviewDb needs to be shared until it goes away with Gerrit Ver. 2.15.

Sharing sessions
There is other stuff you need to share, like web sessions.
When you log in on with your web-browser, and you hit one machine, your browser keeps track that you are logged in with a cookie on your browser while the server keeps track of it on a shared persisted session. If your next hit goes to the other server, you don’t want that user to be kicked out, so you need to share the server session data across nodes.
In 2014 we developed the websession-flatfile plugin, and that helps taking care of sharing web sessions, and I know that a lot of people used that already for HA solutions. It is straightforward, just stores the sessions on the filesystem and if you are using Git repositories on NFS, just put them there also and share them.
Sharing events
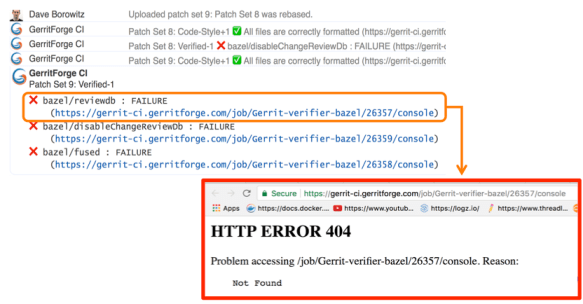
The other thing that you require to share is the events data. Our events need persistence on the server side, and we share them on the filesystem too. That allows to share them across masters also. If you connect to one of our masters through SSH, you get events from both of the masters. It’s a poor man’s sharing, and it is a simple set of files that is there and is shared. One thing that we realized using multi-master is that possibly your events are going to be disrupted much more. Even if you think you have high-availability, the client can only connect to one server. So it doesn’t matter if the cluster has even ten servers, the client is still attached to just one of them.
Generally speaking, most of us want to do rolling upgrades, and that would bring one server down, and that is one of the reasons we want to go to multi-master. If you are doing that frequently, you are disrupting your SSH clients and for those who are permanently connected such as the stream events even more.
I have contributed a new stream events plugin, and I merged it upstream during the last hackathon so you can download it if you want to look at it that helps you to store stuff. You get the added benefit to add some flags to get IDs on your events, and then replay IDs. Since they are stored on the filesystem, when you connect you can tell what the last ID was you connected to, and you can start receiving all the events after that. It does it through the same interface of the old stream events: you drop it in, and it works. It respects Gerrit permissions, just like the core plugin does so that the user that is connecting will see only the events of the projects and branches he has access to.
Coordinating other processes on the Gerrit nodes
As processes on our Servers, we have the Gerrit JVM, but also we have a lot of hooks, some of them run for a very long time. You need to get those to run on both servers. We have a few cronjobs that do repack, we have others that are checking if users are active or inactive on LDAP and update their status on Gerrit and check their e-mails to make sure that they are really what they are saying. And last we have some various maintenance cronjobs.
We focussed on the background stuff first because you need to get that done anyway and you can use it as a peace mill, and we tried to coordinate those first.
We went for the low-tech solution, sharing as much as possible via the filesystem.
Years ago I created a lock implementation based on the filesystem. It is similar to an echo PID to a file but is a lot more robust and can recover deadlocks as long as he can contact the other server using SSH and does all of that automatically.
We use that as a primary method to coordinate things, so on top of that, I have built a scripting queue executor for hooks. Years ago before multi-master, we had issues with hooks that were running for too long. If you remember how Gerrit manages hooks, runs from the Java process with a queue that runs only one at a time. If your hooks take for instance three minutes, you may build up a backlog on your server. If your node goes down, you lose that backlog. What we decided years ago is to have the java process just to write the hook onto a file, and then we have a schedule that runs them in the background. The queue in Gerrit is then always at zero, it takes less than a second to write to the file and then it is done.
We made that multi-master friendly, but because that queue uses the locks, it just worked when we run them on more than one master. One server can write the hooks to a file, and the other could be the one that runs it, and thus it distributes the load in that way.
Gerrit cluster events
If you think about it, there are a lot of things that are hooked into the startup, so I just put a little hook framework that checks if the servers are running and check if the other nodes are running by ssh-ing into them. That allows identifying that if the two servers are down and one goes up, then your node is starting, but also your cluster is starting. And if the other just comes up you are not starting the cluster, but you are starting the node. Then if one node goes down, you haven’t stopped the cluster but you’ve stopped only the node, and if the other goes down you have now stopped the cluster.
I have created a little hooks framework so that you can plug into those events, and then you can do things based on that. For example, at the startup of any node, we are going to start the hooks just to make sure that they are running. But then when you stop a node we disable them only when all the cluster goes down. If one node goes down, the hooks need to be still running because they can contact the other server because they go to the domain name and not to the local server.
We plan to use the hooks framework for replication too. Currently, if you are familiar with the replication plugin, at startup try to replicate all the project to all the slaves to see if they are up to date. The theory behind it is that data could have been modified behind Gerrit back and possibly because when the server was shut down, it was in the middle of doing something and never finished it. In a cluster situation, if at any time something goes down, it could have been in the middle of replicating, and the other node won’t know. When any server goes down, you don’t want to replication, but there is no need to do replication at startup when any node starts but only when the cluster starts.
If there is at least one node up, when the other comes up you don’t want to do global replication. You could replicate it, but it would be a just extra load.
Caching across the cluster nodes
You can do some coordination better than the simple filesystem, for instance, the high-availability plugin does one to one connection, you need to configure the IP of the one master to connect to the other and they connect between each other. That works for two, but it is not a super-scalable system, it is an N-squared problem. Eventually, you want to move to a pub/sub system for things like that.
Something I haven’t mentioned yet it is what we had to do coordination wise it is caching. The high-availability plugin evicts caches, but we don’t do that yet, we consider it an optimization. The primary remedy is just to reduce the time on the caches, mainly decreasing to the values that we had on our slaves. Mostly you probably have lower cache time on your slaves, to make sure that you are checking your projects’ ACLs and your group memberships a little more often than your master. The Gerrit master knows when things get changed without the need to evict any cache, but the slaves do not know when they changed. We made the masters a little bit dumber like the slaves because they know when they changed something but they don’t know when the other masters did. As long as you are fine with the delay, let’s say 5 minutes, then it means that when you change an ACL, it may take up to 5 minutes to be seen by the other masters.
Demo: make your laptop a multi-master Gerrit server
As anybody tried to run two Gerrit instances on the same laptop?
The first problem that you will see is that if you point them to the same H2 caches it will just not start. But if you run init on two different directories and you don’t share any data on the two masters, then you need to go and modify your gerrit.config file to say to start sharing something.
Out of the box sharing abilities
You need to reconfigure the Database to be the same, and you should use a PostgreSQL or MySQL because the default H2 won’t allow any sharing. I am running 2.14 here, and I did not share the indexes, so they are going to be out of date for this demo. The user’s sessions are not going to be shared, so you need to configure them manually to make them shared.
If you use the websession-flatfile plugin, it will put the sessions on the filesystem and then you can share them on the filesystem.
Lastly, the stream events won’t be shared, but most of the rest will just work.
I am about to run stream events on both masters, on the left screen I am connecting to port 29418 and on the right screen on port 29419.
Now if I go to the WebUI, on port 8080 I have the same master of the one on the left, and on port 8081 I have the one on the right.
I am going to create a project using the master on the left: I hit create and you can see that the events appear on the stream events on 29418 but not on 29419.
Now let’s try to go to port 8081, and I have to log in again because the websessions are not shared yet. I am showing to you what it does out of the box. The events now came on the right screen but not on the left one.
The two masters are just pointing to the same Git data: I am trying to make them multi-master, but so far it is not working very well.
Adding plugins to share events and sessions
So, let’s step in and start deploying some new plugins. What we did with the plugins is to create a new one called “events” so that when you want to get the distributed events, you just call “events stream” where “events” is the name of the plugin and stream is the command.
What we did in the core is to remap the actual “gerrit stream-events” to “gerrit stream-events-core” so that you can still get to it if you want and this helps for debugging. And then we pointed the “gerrit stream-events” to “events stream” so that users will automatically get the new plugin events so that to them in invisible.
I am now on 8081 on the browser over here, create a new project called ‘Luca’ and here we go, events are generated on both 29418 and 29419 ports. You may have noticed that showed up on the right first and then to the left.

The events are on the filesystem, so the server just have to pull and here I am pulling every one second, but if something happened on this server, it will automatically catch-up on all the events generated on the other server as well.
The pulling is a backup: the events should come up even without a pulling mechanism. If we eventually had a pub/sub mechanism, I would still suggest keeping the pulling. Events are inherently unreliable and will get lost: you need a pulling mechanism in place if you want true reliability. Pulling is not great, but it is reliable. Events are effectively an optimisation for speed.
Let’s go back now to the other server at port 8080, and I did not have to login because the sessions are now shared and kept across masters. I create a ‘hugo’ project, and it came up pretty quick on both stream events on both masters.
So we have now shared web sessions and shared events. That’s in 2.14 but to make it a true multi-master you would need to share your indexes as well but as we are still on Gerrit v2.7 at Qualcomm, we don’t have an index and we don’t have to share it.
More exciting features in the events plugin
We’ve been using the events plugin in a single-master scenario since early this year, and it has been pretty reliable. I can show some other exciting features are in there. There are some new options here, IDs and resume after. If I give –ids and –resume-after 0, then it returns all the events since I started the instance, and I initialized it. Even if the server started and stopped a bunch of times, I still have all those events recorded. The IDs of the event have two parts of it: the left part is a UUID, and a right portion is a number. The idea being that this is your file store and this is your event store, a unique id associated with it. If someone deleted it on disk, it would create a new one. The idea is that if you had event 1M and someone has removed the file store, and you ask after event 1M, the new event store will restart at zero, and you get nothing. By having different Ids if you ask “give me all the events after ID 1M” then the UUID changed, and it realizes that you need everything. That allows giving some little extra safety. The plugin works on Gerrit v2.14, and I made some changes to make it work on v2.15 as well.

Q: If you use Hugo’s high-availability plugin for the index, you basically can probably do multi-master right now. Why then are you guys not running multi-master? Are you guys concerned about NFS and ref-updates?
A: (Hugo Ares – Gerrit Maintainer) We use it in failover mode for the only reason that if you just have a little bit of load, you are safe and consistency will be kept. But if you push it a bit more then sharing Git repositories from different machines in write mode doesn’t work. If you have two computers writing precisely to the same Git repository to the same branch to the same file at the same time, you are going to lose history, and we know because it happened for us. That’s why we don’t do multi-master right now.
We have been writing for several years to the same repositories from different machines using NFS and we haven’t found any issues because we do repack all over. Perhaps we have different NFS settings or just a different implementation.
A: It did not happen that often, but at least a couple of times and that’s why we don’t do it. We mainly use the high-availability plugin for evicting the caches so that we don’t need to lower the cache settings because they are removed automatically and takes care of the events in a slightly different way and trigger the reindex of the other copies. We can keep nodes down during the day, and the people would not notice any difference at all, no deal. We are just a little bit reluctant to write from both nodes, but that’s the plan.
So here you are already on a “multi-master ready” setup. We hear about your reports of the JGit problems, and we will be keeping an eye on it. I am confident we can fix any issues that could show up over here, understanding how Git works on NFS. There are some tricks that we can pull from our code base.
The (in)famous NFS stale file handle bug
I know we fixed in the past a bug on JGit to handle NFS: when you delete a file, and someone else tries to access it from a different node gets a stale file handle error. That’s the main problem you are running into and we encountered and fixed some of those issues on JGit, and there are possibly a few more left here and there probably. The workaround to the stale file handle problem is just to make a copy or a hard link to it and keep it for a bit more time and remove it later, and then you are fine. Generally speaking is just the brief moment after the operation that would be a problem. It is what it would happen on a local file system anyway: if you delete a file that was still opened by other processes, the inode will stay there for a while until it gets unreferenced. That is the main issue we have been running into, and most of the other problems have been already fixed on JGit.
Distributed GC on a multi-master setup
We have a distributed Git GC and repacking relying on the SSH filesystem lock mechanism that I talked before. We basically have a list of repos to be GCed on the filesystem. All the nodes are saying: “I am going to this,” and another node says “Oh, good, then I am going to do this other one” and in this way, the GC load gets fairly well distributed and you get only a few hours to get through the whole thing. The lock allows preventing to step on each other toes when doing repacking. As far as the backup is concerned, we do a rsync and take database dumps, so that we don’t get inconsistent snapshots. You need to get your Database backup first and then the repositories next. If you are running an older version of the DataBase backup, you are generally safe because you don’t risk to have references to inexistent objects.
Questions
Q: I may have missed one point: the shared filesystem approach is assuming you are not doing multi-site, right? If you were doing multi-site, it would add extra latency that would introduce more problems and add more latency which was the problem you were trying to solve.
A: Yes, that’s correct. We are not interested in multi-site because there are a lot of downsides to it: it is a lot more complicated and makes your writes a lot slower while the reads would be faster. When you are pushing to gerrit-review.googlesource.com you realize that is not the best experience. You need to go to a quorum to the majority of the people around the world to get the agreement of the majority of them to finalize a git push operation.
Single-site is the first initial step for us, multi-site requires a very different approach. You need to get the Git objects to be replicated and then having somewhere to store the refs that have to be shared without a system like Google’s database that assures that the refs are replicated around the world.
It is not impossible; we made some experiments on it. A few years ago Dave Borowitz uploaded a ZooKeeper implementation that does the refs sharing, but that only does the refs. Then you need to do something for the Git objects replication. You could use the regular Git replication to do that, but you need to come up with a bit of magical ref scheme that does the job behind the scene.
A: (Luca Milanesio – GerritForge) Last year at the Gerrit Hackathon in Mountain View, we presented a new implementation of the “missing bit” you were talking about. It an OpenSource project based on JGit and leverages Apache Cassandra for the Git objects, while uses the ZooKeeper implementation for the refs you mentioned. We are making a lot of progress on the project and it will soon be possibly THE solution for Gerrit Multi-Site.
Q: (Luca Milanesio – GerritForge) We found out and fixed recently in JGit a problem with the cache consistency: it was reported on NFS but had nothing to do with it. When JGit was not able to open a file for whatever reason, NFS latency, maximum opened files, whatever, then the packfile was removed from the list of packs because it was considered missing. Then JGit started to failing fetching objects from the repository, and the people were panicking thinking that their Git repository got corrupted. But then, why the other nodes accessing the same repository did not have the same problem? Then “magically” the problem disappeared when you restarted Gerrit. The problem has been fixed in recent versions of JGit but is still there for the version you are currently using as the basis of Gerrit v2.7. Did you find the same problem? How do you manage to keep up with the recent releases of JGit but staying on Gerrity v2.7?
A: We have an old version of JGit, but we have put our patches on it. I believe we discovered and fixed a bug like that years ago. We ported a series of patches upstream and we a set of performance improvements on our branch. However, it is hard sometimes to get stuff merged on JGit; there are not enough maintainers to even look at the thing.