
My name is Luca Milanesio, and I work for GerritForge. My talk today is about plugins and how to create them using scripting languages.
Gerrit plugins, where it all began
My contribution to the Gerrit Code Review project started in 2011 with the introduction of plugins. To understand where we are coming from we need to back to those times when the project was just born a year earlier. Gerrit was mighty since its very beginning, and different companies that used and contributed to the tool had tailored the code base to their specific needs. When I joined the GitTogether conference in 2011, almost every user was talking about their fork of Gerrit. Forking is excellent especially in OpenSource because you can customise a project as much as you want and, we were all excited about the growing popularity of GitHub and forking was a popular concept. However, keeping a fork up-to-date is not as easy as you may initially envision. Moving on with the upstream releases is hard when you are working on a fork.
Back in 2011 when I was at the conference, I thought: “how can the Gerrit project evolve and grow if we are all working on forks?”. My way to convince the Gerrit Community to change that status quo was inviting Kohsuke Kawaguchi, the Jenkins CI project founder, to the summit. Jenkins CI is wholly based on plugins while the core does not do much: the plugins are making the whole thing work as a CI.

That was enough to convince the community that a change was needed and, during the next Hackathon in 2012, I wrote the initial version of the Gerrit plugin loader and the first “Hello world” Gerrit plugin was born.
The introduction of scripting languages
After two years, Gerrit had only 50 plugins. If you had looked at Jenkins, at that time they had over 600 plugins, ten times as many plugins compared to Gerrit. Writing a new plugin for Gerrit was still too hard for most developers and administrators.
To develop a new Gerrit plugin you needed to know way too many things and have many skills: a different build system (Buck and now Bazel), having a full development environment and all the required dependent packages.
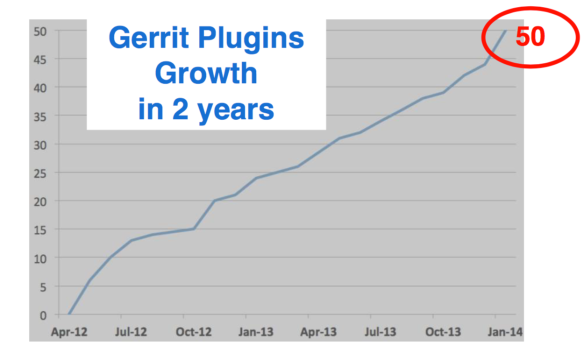
We still had new plugins because some people went through the initial pain of setting up the environment. However, for a project to thrive, you need to get people together and embrace a diversity of skills to allow people to give the best of their knowledge.
Maybe the typical Gerrit admin is not a Java Developer, possibly could be more familiar with Groovy because the Ruby syntax is used a lot of DevOps tools. Others are more familiar with Python, and if you accept what they can contribute, the project can benefit from many more experiences from different people and backgrounds.
What does the community think about it?
Once I shared my ideas with the community, the feedback was great. However, different people with different backgrounds started asking to use very different languages, ranging from Scala to Groovy and Python. Then I realized that supporting one scripting language would not have been good enough for most of the people.
“Hello world” in Groovy
To give you an idea of how easy is to write a new plugin in Groovy, see the following example.
import com.google.gerrit.sshd.*
import com.google.gerrit.extensions.annotations.*
@Export("groovy")
class GroovyCommand extends SshCommand {
public void run() { stdout.println "Hi from Groovy" }
}
It is straightforward to write scripting plugins: put the above content in a hello-1.0.groovy file in the Gerrit’s /plugins directory and as soon as the file is saved the plugin is there and will be loaded in Gerrit within a few seconds.
The way that Gerrit recognize this file being a plugin is through its .groovy extension. The file name denotes both the plugin name and its version, delimited by the ‘hyphen’ on the filename. In this example the file hello-1.0.groovy identify a plugin called ‘hello’ with a ‘1.0’ version.
One warning about Groovy: it is a language that relies on Java Reflection for method invocation. Reflection is a capability of the Java Runtime and enables methods discovery which is handy to use but is slower than a native Java language.
The drawback of the ease of use of the Groovy language is the CPU cycles at runtime.
The beauty of using a scripting language for plugins is the speedup of the development cycle: as soon as you edit the Groovy file on the file system, the old plugin is unloaded and the new one loaded in Gerrit. The plugin development lifecycle becomes so much faster compared to the traditional Java application development.
Develop Scripting plugins using Docker

Gerrit is provided as a Docker image on DockerHub. The ‘gerritcodereview’ organization has an image name called ‘gerrit’ with all the versions available denoted as tags since Ver. 2.14. Earlier versions of Gerrit docker images are available on the ‘gerritforge’ DockerHub organization.
In the following example I am running Gerrit 2.14.4 on Docker fetching the image directly from DockerHub:
docker run -ti -p 8080:8080 -p 29418:29418 gerritcodereview/gerrit:2.14.4
In the above example, Gerrit is exposed through HTTP on port 8080 and exposes its SSH interface at port 29418.
Docker is a system that allows running containers, which are application “packaged” with everything needed, including other components of libraries of the underlying operating system. The only requirement on your physical host is the Docker engine, which exists nowadays for MacOS and Windows other than Linux where it was originally designed. Whatever operating system you are running on your laptop, Docker is there.
Docker can be handy for all the contributors that are not familiar with Gerrit Development Environment. There is no need to know or install anything on the local box, other than running the Gerrit Docker container. When I am running Gerrit in this way in this example, it starts straight away, with zero installation steps or configuration.
Gerrit out-of-the-box experience
The second significant value of the Gerrit Docker container is that includes an out-of-the-box configuration, a welcome screen, and the plugin manager. It consists already a set of components that, if you are not familiar with Gerrit, will help you a lot to understand what is Gerrit and how to use it.
As you can see from this screen, Gerrit has started, and if you navigate to http://localhost:8080, it shows you an initial welcome screen.
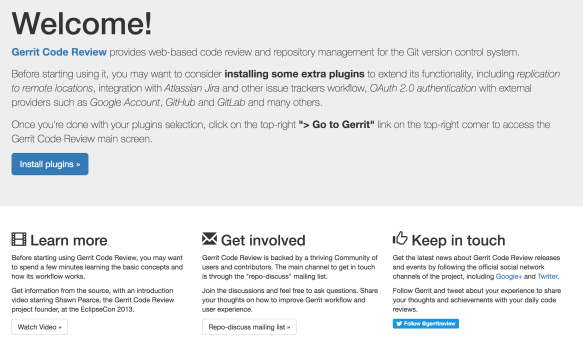
Historically the very first screen, once you have installed Gerrit, was a blank screen. I remember a few years ago people coming to me saying that as new Gerrit users they were quite confused: they just did not know what to do with the initial blank screen. In Gerrit Docker, the initial screen is a “Welcome” which is a beautiful thing to say to people that you did not know that came to your house. Additionally, it provides some useful links and information to install plugins, which is very important because Gerrit without plugins is missing some fundamental parts of its functionality.
Playing with Gerrit Plugin Manager
By clicking the “Install plugins” button, you reach the Gerrit Plugin Manager screen. For all of those who are familiar with Jenkins, it provides precisely the same functionality as in Jenkins. If you type ‘groovy’ in the search bar, you can easily find where the Groovy scripting provider is, and you can install it with a simple click. That is the plugin you need to tell Gerrit that from now on, every file in the /plugins directory with a .groovy extension is a plugin that needs to be parsed and loaded at runtime.

You can discover and install other plugins as well. For instance, typing ‘github’ would list the integration of Gerrit with GitHub authentication and pull requests, or typing ‘jira’ would return the association and workflow integration with Jira Tickets.
The plugin manager is a fantastic discovery mechanism to understand what are the integrations available for Gerrit Code Review.
The plugin manager automatically discovers the versions of the plugins that are compatible with the Gerrit you are currently running and, when you click ‘Install’, it downloads them and installs them locally. When you are done, just click on the top-right link “Go To Gerrit” and you are straight into Gerrit UX.
How we have a running Gerrit instance that has installed all the plugins I need, including the support for Groovy plugins.
Writing plugins in Scala
If you need want to leverage the Gerrit scripting plugins, but you need optimal performance at runtime, you can use a different scripting language such as Scala.

The Scala language allows compiling into the native Java bytecode; it does not use reflection for method calls and, for some operations could be even faster than the Java language itself. See the same hello world example but rewritten in Scala.
import com.google.gerrit.sshd._
import com.google.gerrit.extensions.annotations._
@Export("scala")
class ScalaCommand extends SshCommand {
override def run = stdout println "Hi from Scala"
}
When I showed this to the community people got so excited and started writing tons of scripting plugins.
What scripting plugins do in Gerrit?
Admin tasks as SSH commands
Sometimes Gerrit admins need to automate specific tasks, however, coding an external script could be slower and difficult to implement. Inside Gerrit, there are already a lot of objects which represent pre-processed in-memory entities ready to be used. It makes sense to leverage all the information that is in-memory already and write new SSH commands like Scripting plugins to control admin tasks remotely.
Scripted REST API
At times you need as well to tailor existing Gerrit REST API to your needs. For instance, imagine that your company has specific policies for requesting new repositories: why not then creating a new ‘Create Project’ REST API tailored for your needs using the Scripting plugins and expose it through a company HTML form? You can do it without the need to be an experienced Java or Gerrit contributor and using a simple Groovy script for the new REST API.
Low-footprint hooks events
A third option is fascinating because, before the introduction of Gerrit plugins, the only way to react to Gerrit events was through hooks or stream events. Hooks are a traditional Git mechanism and, in Gerrit, have a scalability problem: they are invoked for every project and every event that happens anywhere and spawn a different asynchronous process. Over time the extra processes created can cause a significant overhead for your super-busy Gerrit server.
When a hook script needs to read from the Git repository, it would then need to process from scratch the packfiles from the local filesystem, uncompress and parse them in memory over and over again, which could slow down your server significantly.
If you are implementing Gerrit events using plugins, the same processing could be ten or even hundreds times faster.

