First, a huge thank you to the OpenInfra Foundation for hosting this event in Paris. Their invitation to have the Gerrit User Summit join the rest of the community set the stage for a truly collaborative and impactful gathering.
Paris last weekend wasn’t just a conference; it was a reunion. Fourteen years after the last GitTogether at Google’s Mountain View HQ, the “Git and Gerrit, together again” spirit was electric.
On October 18-19, luminaries from the early days (Scott, Martin, Luca, and many others) reconvened, sharing the floor with the new generation of innovators. The atmosphere was intense, filled with the same collaborative energy of 2011, but focused on a new set of challenges. The core question: how to evolve Git and Gerrit for the next decade of software development, a future dominated by AI, massive scale, and an urgent demand for smarter workflows.
Here are the key dispatches from the summit floor.
A Historic Reunion, A Shared Future
This event was a powerful reminder that the open-source spirit of cross-pollination is alive and well. The discussions were invigorated by the “fresh air” from new-school tools like GitButler and Jujutsu (JJ), which are fundamentally rethinking the developer experience.
In a significant show of industry-wide collaboration, we were delighted to have GitLab actively participating. Patrick’s technical presentation on the status of reftable was a highlight, but his engagement in discussions on collaborative solutions moving forward with the Gerrit community truly set the tone. It’s clear that the challenges ahead are shared by all platforms, and the solutions will be too.
Scaling Git in the Age of AI
The central theme was scale. In this rapidly accelerating AI era, software repositories are growing at an unprecedented rate across all platforms—Gerrit, GitHub, and GitLab alike. This isn’t a linear increase; it’s an explosion, and it’s pushing SCM systems to their breaking point.
The consensus was clear: traditional vertical and horizontal scaling is no longer enough. The community is now in a race to explore new techniques—from the metal up—to improve performance, slash memory usage, and make core Git operations efficient at a scale we’ve never seen before. This summit was a rare chance for maintainers from different ecosystems to align on these shared problems and forge collaborative paths to solutions.
Dispatches from the Front Lines: NVIDIA and Qualcomm
This challenge isn’t theoretical. We heard powerful testimonials from industry giants NVIDIA and Qualcomm, who are on the front lines of the AI revolution.
They shared fascinating and sobering insights into the repository explosion they are actively managing. Their AI workflows—encompassing massive datasets, huge model binaries, and unprecedented CI/CD activity—are generating data on a scale that is stressing even the most robust SCM systems. Their presentations detailed the unique challenges and innovative approaches they are pioneering to tackle this data gravity, providing invaluable real-world context that fueled the summit’s technical deep dives.
Beyond the Pull Request: The Quest for a ‘Commit-First’ World
One of the most passionate debates centered on the developer workflow itself. The wider Git community increasingly recognizes that the traditional, monolithic “pull request” model is ill-suited to the “change-focused” code review that platforms like Gerrit have championed for years.
The benefits of a change-based workflow, cleaner history, better hygiene, and higher-quality atomic changes—are driving a growing interest in standardizing a persistent Change-ID for each commit. This would make structured, atomic reviews a first-class citizen in Git itself. The collaboration at the summit between the Gerrit community, GitButler, JJ, and other Git contributors on defining this standard was a major breakthrough.
This shift is being powered by tools like GitButler and JJ, which are built on a core philosophy: Workflow Over Plumbing. Modifying commits, rebasing, and resolving conflicts remain intimidating hurdles for many developers. The Git command line can be complex and unintuitive. These new tools abstract that complexity away, guiding users through commit management in a way that feels natural. The result is faster iteration, higher confidence, and a far better developer experience.
AI and the Evolving Craft of Code Review
Finally, no technical summit in 2025 would be complete without a deep dive into AI. The arrival of AI-assisted coding is fundamentally shifting the dynamic between author and reviewer.
Engineers at the summit expressed a cautious optimism. On one hand, AI is a powerful tool to accelerate reviews, improve consistency, and bolster safety. On the other, everyone is aware of the trade-offs. Carelessly used, AI-generated code can weaken knowledge sharing, blur IP boundaries, and erode a team’s deep, institutional understanding of its own codebase.
The challenge going forward is not to replace the human in the loop, but to strengthen the craft of collaborative review by integrating AI as a true co-pilot.
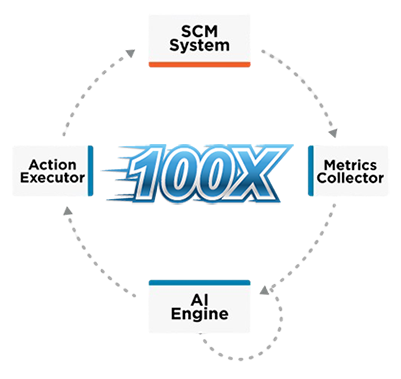
A Path to 100x Scale: The GHS Initiative
The most forward-looking discussions at the summit centered on how to achieve the massive scale required. One of the most promising solutions presented was GHS (Git-at-High-Speed). This innovative approach is not just an incremental improvement; it’s a strategic initiative designed to increase SCM throughput by as much as 100x.
The project’s vision is to enable platforms like Gerrit, GitLab, and GitHub Enterprise to handle the explosive repository growth and build traffic generated by modern AI workflows. By re-architecting key components for hyper-scalability, GHS represents a concrete path forward, ensuring that the industry’s most critical SCMs can meet the unprecedented demands of the AI-driven future.
The Road from Paris
The Gerrit User Summit 2025 was more than a look back at the “glorious days.” It was a statement. The Git and Gerrit communities are unified, energized, and actively building the next generation of SCM. The spirit of GItTogether 2011 is back, but this time it’s armed with 14 years of experience and a clear-eyed view of the challenges and opportunities ahead.
As 2024 draws to a close, it’s a great time to reflect on the milestones and achievements of the GerritForge team in innovating Git performance with the release of GHS, supporting and advancing the Gerrit Code Review project with 20 releases and over 1.5k commits. This year has been one of exciting developments and initiatives that have made Gerrit stronger, more accessible, and better equipped to meet the needs of modern software teams. Here’s what GerritForge accomplished for the Git and Gerrit Code Review ecosystem in 2024.
2024 in numbers
1,500 changes merged
40 repositories involved in the Gerrit and JGit projects
20 releases
5 conferences, 6 meetups
11 contributors, 4 maintainers
20k man/hours spent in open-source projects
Managing the Releases of Gerrit 3.10 and 3.11
As usual, we continue to ensure the regular releases of new Gerrit versions. This year was no exception with the releases of Gerrit 3.10 and 3.11. These releases introduced new features, performance optimisations, and bug fixes to further solidify Gerrit as the leading code review tool for large-scale projects.
Our team cooperated with the Gerrit Code Review community to ensure these releases were stable, well-documented, and aligned with community needs. From coordinating release schedules to ensuring compatibility with plugins and integrations, GerritForge played a key role in making these versions a reality.
Key Highlights
Gerrit 3.10 brought major improvements in user experience, including refined UI capabilities and enhanced search functionality.
Gerrit 3.11 introduced critical updates to multi-site support, security enhancements, and significant performance boosts.
GerritMeets success in both the USA and Europe
The GerritMeets series has become a cornerstone of community engagement, and 2024 was no exception. GerritForge organised six GerritMeets across several locations, including California, Germany, and the UK, bringing together contributors, users, and maintainers to share knowledge, discuss trends, and explore use cases. Each session covered a diverse range of topics, including:
Best practices for multi-site setups.
Advanced plugin development.
Gerrit performance tuning for large repositories.
Innovations in CI/CD workflows with Gerrit.
These virtual meetups provided a platform for collaboration and learning, reinforcing Gerrit’s community spirit. All the recordings of the 2024 GerritMeets are available as a playlist on the GerritForge TV YouTube channel.
World-class Enterprise Gerrit-as-a-Service on Google Cloud Platform
In 2024, GerritForge expanded Gerrit’s capabilities by adding support for Gerrit-as-a-Service (GaaS) on the Google Cloud Platform (GCP). This initiative makes it easier than ever for organizations to adopt Gerrit without the operational overhead of managing infrastructure.
Benefits of Gerrit-as-a-Service on GCP
Scalability: Leveraging GCP’s powerful infrastructure to scale Gerrit deployments for enterprises of any size.
Simplicity: Reducing setup and maintenance complexity, allowing teams to focus on development and code reviews.
High Availability: Utilizing GCP’s advanced networking and storage capabilities for improved uptime and disaster recovery.
By enabling Gerrit on GCP, GerritForge is broadening the tool’s accessibility, particularly for teams looking for a cloud-native, fully managed solution.
Gerrit User Summit with Qualcomm
This year’s Gerrit User Summit, organized by Qualcomm in collaboration with GerritForge, was a highlight for the community. Held at the Qualcomm HQ in San Diego, CA (USA), the summit offered a chance for Gerrit enthusiasts worldwide to come together in person. The agenda featured:
Keynotes by Gerrit maintainers and industry leaders.
Hands-on hackathon for contributors and users.
Insightful panels on the future of Gerrit.
The collaboration with Qualcomm not only expanded the summit’s reach but also highlighted Gerrit’s growing importance in enterprise environments.
Showcasing GHS and Gerrit Code Review worldwide
This year, GerritForge actively participated in numerous conferences to showcase GHS and expand Gerrit’s visibility, and demonstrate its unique capabilities. These events were a fantastic opportunity to uncover GHS and showcase Gerrit to hundreds of developers who had never encountered it.
At these conferences, we showcased:
GHS: It demonstrates its seamless integration with Git and showcases a whopping 100x performance improvement over a vanilla setup thanks to the power of AI and reinforcement learning.
K8s-Gerrit: Highlighting how Gerrit deployed on Kubernetes provides unparalleled flexibility, performance, and multi-site support.
Through live demos, presentations, and Q&A sessions, we highlighted GHS and Gerrit’s ability to scale, its unique review model, and its role in making software delivery pipelines up to 100x times faster.
K8s-Gerrit Hackathon with SAP
Collaboration was at the forefront of the k8s-Gerrit Hackathon, co-hosted by GerritForge and SAP. The hackathon brought together developers from both SAP and GerritForge teams to tackle the challenges of Kubernetes-based Gerrit deployments and multi-site support.
Outcomes of the Hackathon
Enhanced scalability for k8s-Gerrit deployments.
Breakthroughs in multi-site replication and disaster recovery.
Valuable contributions to the Gerrit codebase and documentation.
The event exemplified the power of open collaboration, pushing Gerrit further into cloud-native development.
Looking Ahead to 2025
As we celebrate the progress made in 2024, we remain focused on the road ahead. GerritForge is committed to:
Public offering of GHS
Gerrit-as-a-Service in Google Cloud
Gerrit Code Review v3.12 and v3.13
More GerritMeets and Gerrit User Summit events
Our gratitude goes out to the Git and Gerrit Code Review communities, contributors, and partners who have made this year a success. Together, we’re building a tool that empowers teams to deliver high-quality code faster and more efficiently. Here’s to an even more impactful 2025!
TL;DR: GerritForge has been dedicating its efforts to organising and managing the Gerrit User Summit in London back in November 2022, in conjunction with the release of Gerrit v3.7. The event has been a great success, with a significant presence on-site and record-breaking attendees on the GerritForge TV youtube channel. It has also committed to its promises to research and improve the JGit and Gerrit scalability to large mono-repos, with tens of millions of objects and refs. 2023 will see the finalisation of these efforts with an increase in development efforts and a new JGit Committer for pushing the platform to a new level of performance and scalability and a new innovating system for collecting and optimising the repository metrics automatically. Stay tuned.
Read the full story here below (9 mins read).
2022 has been a critical year for turning the Gerrit Code Review community and development back on track after the COVID-19 pandemic. At GerritForge, we’ve been working hard to make sure that the development, support, and innovation of Gerrit Code Review continue on its main objectives.
Gerrit Code Review v3.6 and v3.7
We have continued to deliver on the development and release of Gerrit Code Review and its plugins, helping the testing and releasing of versions v3.6.0 (May) and v3.7.0 (November).
3,627 Changes have been merged on 76 projects related to the Gerrit Code Review platform, including JGit
113 committers from 42 different organisations
A special mention to the top #10 contributors: Google (Ben Rohlfs, Edwin Kempin, Chris Pouchet, Dhruv Srivastava, Frank Borden, Milutin Kristofic), GerritForge (Luca Milanesio), Wikimedia (Paladox) and SAP (Matthias Sohn and Thomas Dräbing).
In comparison with 2021, we had 25% fewer changes merged but with more contributors coming from more companies, which is a symptom to a very healthy and thriving ecosystem of maintainers.
GerritForge has committed to resuming the face-to-face user summits, which were suspended since 2020.
It was a glorious success, with record-breaking attendance from all around the globe:
50 people registered to attend on-site, 26 of them managed to arrive despite the London tube strike, whilst the others attended remotely
235 people viewed the summit on YouTube with an average view time of 40 mins (one talk)
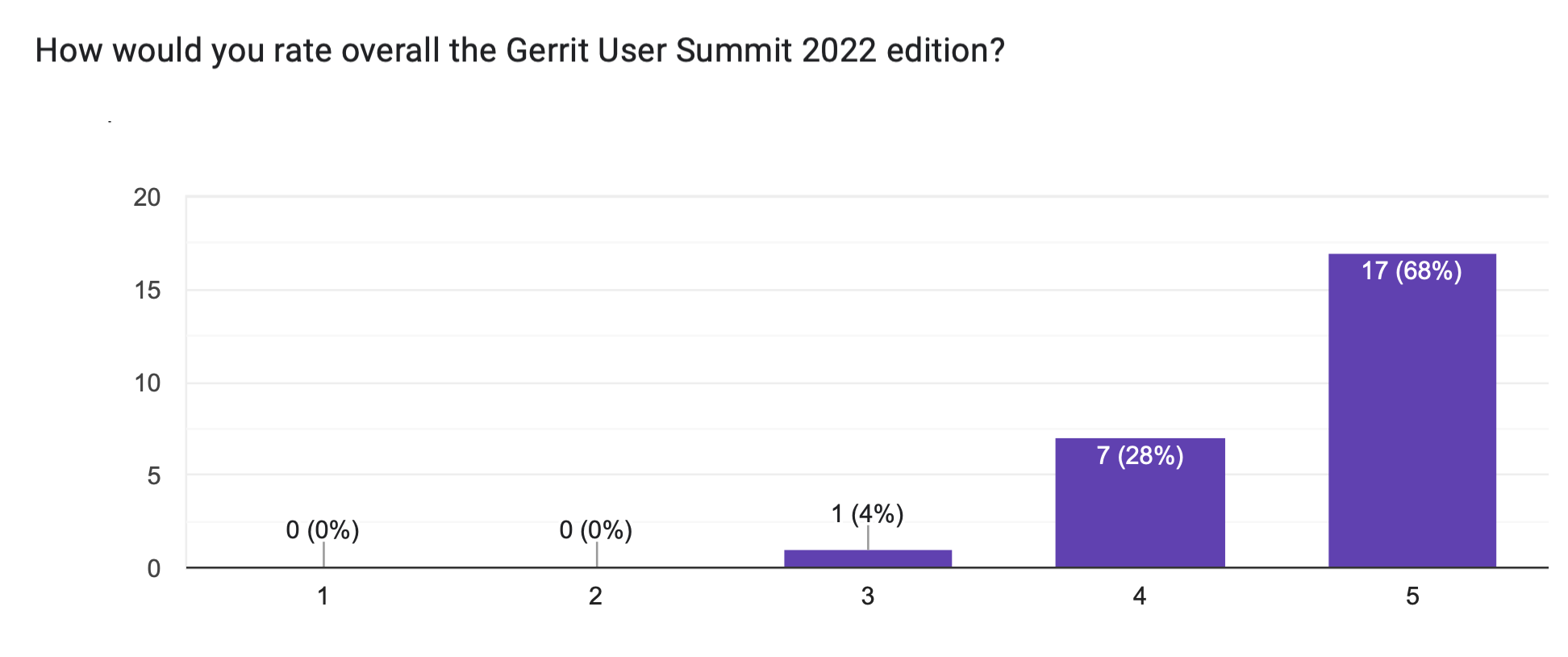
The summit survey had an outstanding report showing a huge acceptance and appreciation of the event:
82% rated the remote video streaming as “good” or “outstanding”
96% rated the quality of the summit as “good” or “outstanding.”
100% would recommend the summit to a colleague, with 83% strongly recommending it
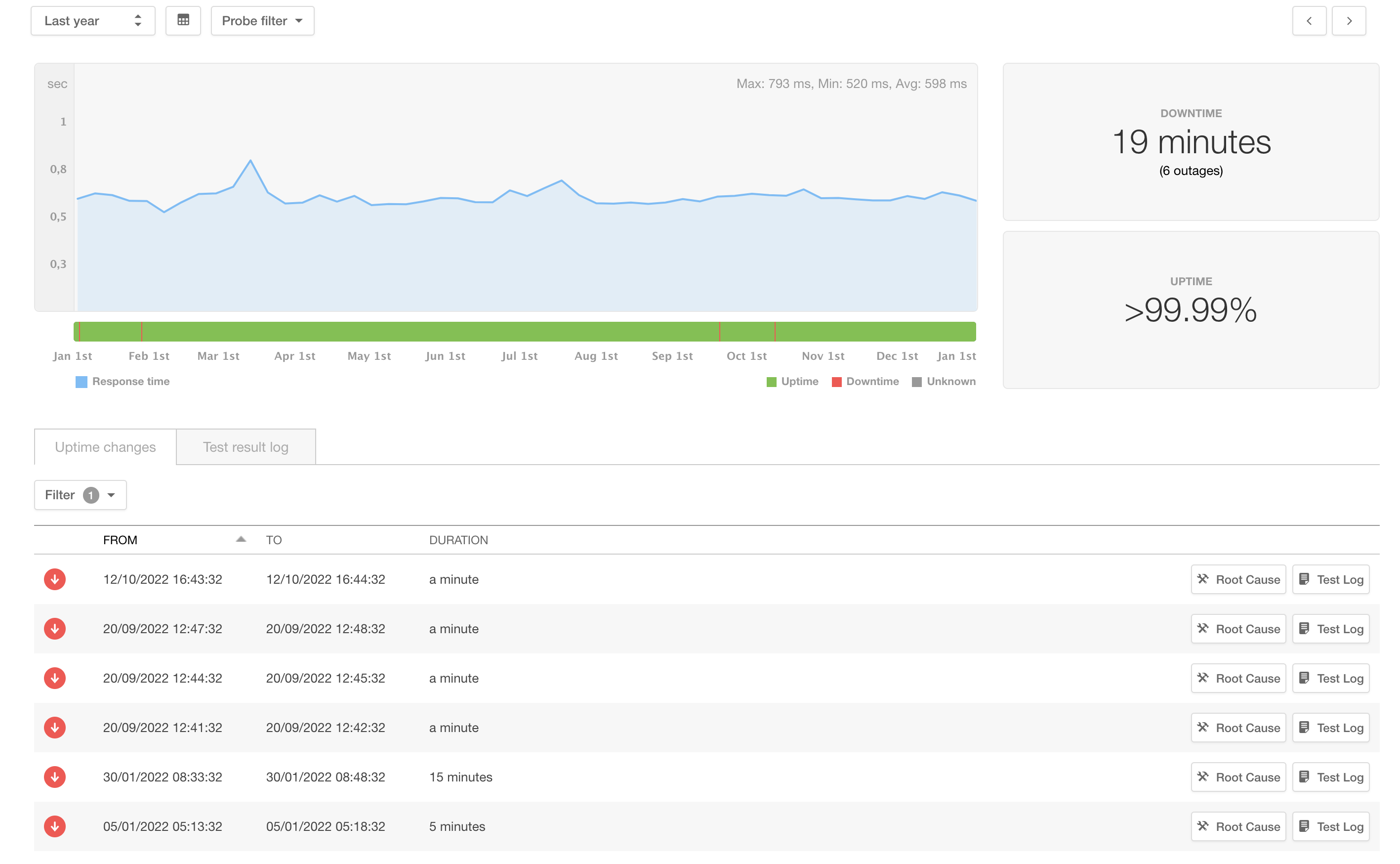
GerritHub.io SLA gets closer to five-nines.
We have been working hard to make Gerrit more stable and resilient throughout 2022, discovering and fixing many issues in the code base and on the multi-site software architecture. In 2022, GerritHub.io had only six small hiccups for a total of 19 mins of downtime (SLA = 99.997%) over a 12-month period, a 75% reliability improvement compared to 2021.
We have run extensive RCAs on the causes of the downtime and identified two leading issues, which are explained in the details below.
The “anonymous unlimited query” hole in Gerrit GerritHub.io has been subject to a 15 mins outage because of anonymous users being able to bring offline all the sites before the system could auto-recover. Gerrit allows bypassing of all limits set in the ACLs for running queries by simply adding the “no-limit” parameter. Returning an arbitrary payload without limits could allow a single user to generate a server-side workload for collecting and building a GBytes-sized JSON payload; unfortunately, that option was available to everyone, including anonymous users making any publicly faced Gerrit Code Review installation subject to deny-of-service attacks. We have identified the issue, reported and fixed it in Gerrit with Change 333304, which has been included in Gerrit v3.3.10, v3.4.4, v3.5.1, and all v3.6.0 or later releases.
More granular monitoring and alerting We have lowered the threshold of uptime checks on GerritHub.io to 1 minute, giving us the ability to detect and react immediately to 4 smaller hiccups. We have detected a lack of scalability for some specific higher-load projects. Those hiccups have been responsible for 2 mins of downtime over the 2nd part of 2022. Many more projects are also planning to be onboarded on GerritHub.io; hence we do need to address this project-specific capacity needs.
Scaling Gerrit Code Review and JGit beyond its limits
We have been investing a massive effort in building a test environment designed to stress Gerrit and JGit to its limits and identify all the limitations and bottlenecks that prevented us from scaling further.
Scaling the test repository We have created over the months some test repositories that increased in every dimension:
Tens of millions of refs as both refs/changes and refs/heads
Millions of delta-chains
Tens of millions of Git objects
Packfiles of tens of Giga-bytes and packed refs of hundreds of megabytes
For generating a significant load on both client and server side, we have invested more into the aws-gerrit cloud setups and gatling-git performance loading tool.
There were some “well-known” issues and additional surprising ones.
SHA1 complexity and CPU utilization for large entities JGit has been used SHA1 for identifying uniqueness not just for Git objects but also for other large entities. However, computing SHA1 has become increasingly CPU intensive because of the relatively recent findings about collisions on shattered.io. We have highlighted two major potential improvements in cooperation with Matthias Sohn (SAP) on the raw SHA1 performance and its application for detecting packed-refs changes on the filesystem.
Commit priority queues JGit has a custom implementation of priority queues which are intensively used in RevWalk, which has almost quadratic complexity. That isn’t a problem for small to medium chains of commits; however, when the number of commits reaches millions, the performance degradation becomes unbearable. We have replaced the JGit’s custom implementation with the one provided by the Java JVM library, which has a logarithmic complexity that massively improves its performance with large commit chains.
Unwanted reachability checks JGit needs to perform a full reachability check whenever a remote unknown client is advertising refs, which makes sense when serving a remote client. However, the cost of full reachability of millions of advertised refs can be a daunting task that may be alleviated if the remote end can be considered trusted.
Fixing JGit bitmaps Since the introduction of Git bitmap, the whole community has learned how key they are in speeding up the counting and selection during the clone phase. However, large and unoptimized bitmaps could be so unhelpful for Git that instead of speeding up, they could represent a massive overhead for the system, causing CPU spikes and, eventually, lowering the throughput of the server. Git bitmaps are compressed using the JavaEWAH library, which is good for memory consumption but evil for CPU utilization: that is the reason why the smaller is best for performance. We have discovered and fixed a critical issue with the JGit bitmap generation that was causing the inclusion of all commits and BLOBs pointed by annotated tags. Also, we have introduced the ability to inform JGit about the heads that can be excluded from the bitmap, allowing to shorten the creation tens of thousands times (5h generation time for a 2k refs to as little as 60s) and increase its effectiveness by 200%.
Millions of unneeded ref logs When performing a clone of a repository with millions of heads, JGit created one local reflog file for every remote ref, including the ones there were not actually cloned but just fetched as remote references. This was creating a significant performance gap between JGit and Git, which would instead lazily create the reflog files once they are effectively checked out the first time. Cloning a single branch of a repository with millions of remote refs took around 1h, compared to a few minutes of Git.
All of the findings were included in multiple updates on the following components:
aws-gerrit is going through upgrades for making use of pull-replication plugin, including the support for the bearer token which allows to replicate virtually any repository, including All-Users.git
gatling-git: we have upgraded the Gatling version and JGit to the latest stable-5.13 to include the latest performance improvements.
git-repo-metrics: we have introduced a brand-new plugin that allows us to keep under control the major dimensions of a repository and therefore graph their increase over time.
GerritForge goals for 2023
We are definitely not done yet with the performance improvements on Gerrit and JGit: there are still significant improvements to be made, and JGit changes to get merged into the mainstream branches. We believe we are on track to finalize the job and allow a stable and scalable platform for large Git repositories in 2023.
Finalise what we cooked in 2022 for JGit JGit has a new maintainer, David Ostrovsky, awarded in 2022 as Git committer of the project. GerritForge’s devs are focused to get more reviews and attention to the JGit performance improvements. We are committed to finalising all the open changes related to large repositories.
JGit multi-pack indexes support There is still a major gap between JGit and Git when dealing with very active repositories: multi-pack indexes. The proliferation of packfiles would eventually lead to a long and painful search-for-reuse phase for BLOBs which could be cut down 100s of times with a multi-pack index.
Git repository optimiser for Gerrit We have been working on tracking the live information on the Git repository, thanks to the git-repo-metrics plugin. Wouldn’t it be nice to have a tool that can do something with it and automatically? We would be doing R&D on how to correlate the repository metrics, the Git audit trail, and the performance data for making AI-based decisions on what needs to be improved on the repository. This work stream is going to be useful for any Git repository, not just the ones powered by Gerrit Code Review. The ‘git-repo-metrics’ and the repository optimiser would also apply to other products, including GitHub and GitLab.
Gerrit v3.8 and projects-specific change numbers We will finalise the design document for the transition to project-specific change numbers in Gerrit v3.8. That would allow the seamless migration of projects across Gerrit setups without having to worry about changes renumbering anymore.
Gerrit Code Review testing and GerritForge-certified binaries GerritForge is spending a tremendous amount of time developing test environments and tools for serving the Gerrit community with more stable releases and improving the quality of its code. We want to intensify the effort and also offer our platinum support customers a unique service that includes the GerritForge digital signature and rubber stamp on the binaries of Gerrit Code Review and its plugins that have been successfully tested and validated for being production-ready. Stay tuned; more details are coming soon …
GerritForge company forecast in 2023
GerritForge Inc. will finalise its roll-out to the USA, and all contracts and services will be run from Sunnyvale, CA and Europe. Over 2022, 60% of the customers and businesses have already been moved, and the operation will be completed over the course of 2023.
We are looking forward to doubling our revenue figures in 2023 and also our contributions to the open-source community, with a main focus on JGit as the driver of performance growth for Gerrit Code Review.
Yet another year has passed for the Gerrit Code Review project with many challenges posed by the COVID-19 pandemic, new exciting releases, and the most popular Gerrit User Summit with the largest audience ever in its 12 years of history.
2021 in numbers
93 registered attendees to the Gerrit Virtual User Summit 2021, connecting from 56 companies over 17 countries, 14 talks showcased by 15 presenters over 2 days
35 releases of which 2 major versions (v3.4.0 and v3.5.0.1) and 33 patches
107 contributors from 32 organizations, merging 4763 changes to 84 projects
The Gerrit Code Review community has shown resiliency during these difficult times, with outstanding participation in the events organized during the year, all remote and lacking the much-needed face-to-face interaction.
2021 vs. 2020 trends
Commits: -26%
Projects: -16%
Contributors: -30%
Companies: -41%
Average changes/contributor: +10%
The engagement has paid its toll after two years of pandemics with fewer organizations willing to invest time in contributing to Gerrit, possibly also impacted by the uncertainty of the future. 2021 has also been the first whole year of the project without David Pursehouse, one of the Gerrit project’s top #3 contributors. He was used to contributing 1.5k changes per year, which would alone easily justify the drop observed.
On the bright side, the contributors that continued over the year 2021 have shown an increased commitment as the number of active projects and commits has dropped less than the contributors, increasing the change/contributor rate compared to 2020.
Major organisations contributing to Gerrit in 2021
Google is confirmed to be the leading force of the Gerrit Code Review project, with over 62% of the changes merged, while GerritForge continues to be the #1 top contributor from the rest of the community. There are a couple of pleasant special surprises from the contributors.
Wikimedia Foundation confirmed to be the #2 top contributor from the community, all provided by Paladox who has been awarded Gerrit Maintainer in November.
SAP continues to be a strong contributor, just below Wikimedia Foundation, with Thomas being awarded Gerrit Maintainer in November.
Qualcomm is back on the shortlist of the top maintainers, with many new names in the list of contributors, well done!
The first surprise is that the code-owners, the emerging star of the Gerrit plugins, received a massive investment of effort from Edwin (Google), who contributed 89% of the changes to it. The code-owners plugin has also been presented at the Gerrit Virtual User Summit 2021 and attracted the community’s attention.
The second surprise is the decline in contributions in the jgit project during the past two years: from 820 changes/year is now down to 374 changes in 2021.
Task is now the #2 plugin project in terms of merged changes in 2021. Qualcomm keeps the project’s full ownership with 98.9% of changes in 2021.
GerritForge confirm their commitment to improving Gerrit Multi-Site, as its plugin is the #3 in terms of changes merged in 2021.
Aws-gerrit is a relatively new project, presented less than two years ago and contributed by GerritForge, who contributed over 99% of the changes. It confirms to be a very active project that has helped the Gerrit Code Review open-source project deploy and test well-known “recipes” of infrastructure setups and see how Gerrit performs and works on those. Many bugs have been detected before the release and identified by the aws-gerrit project and CI integration.
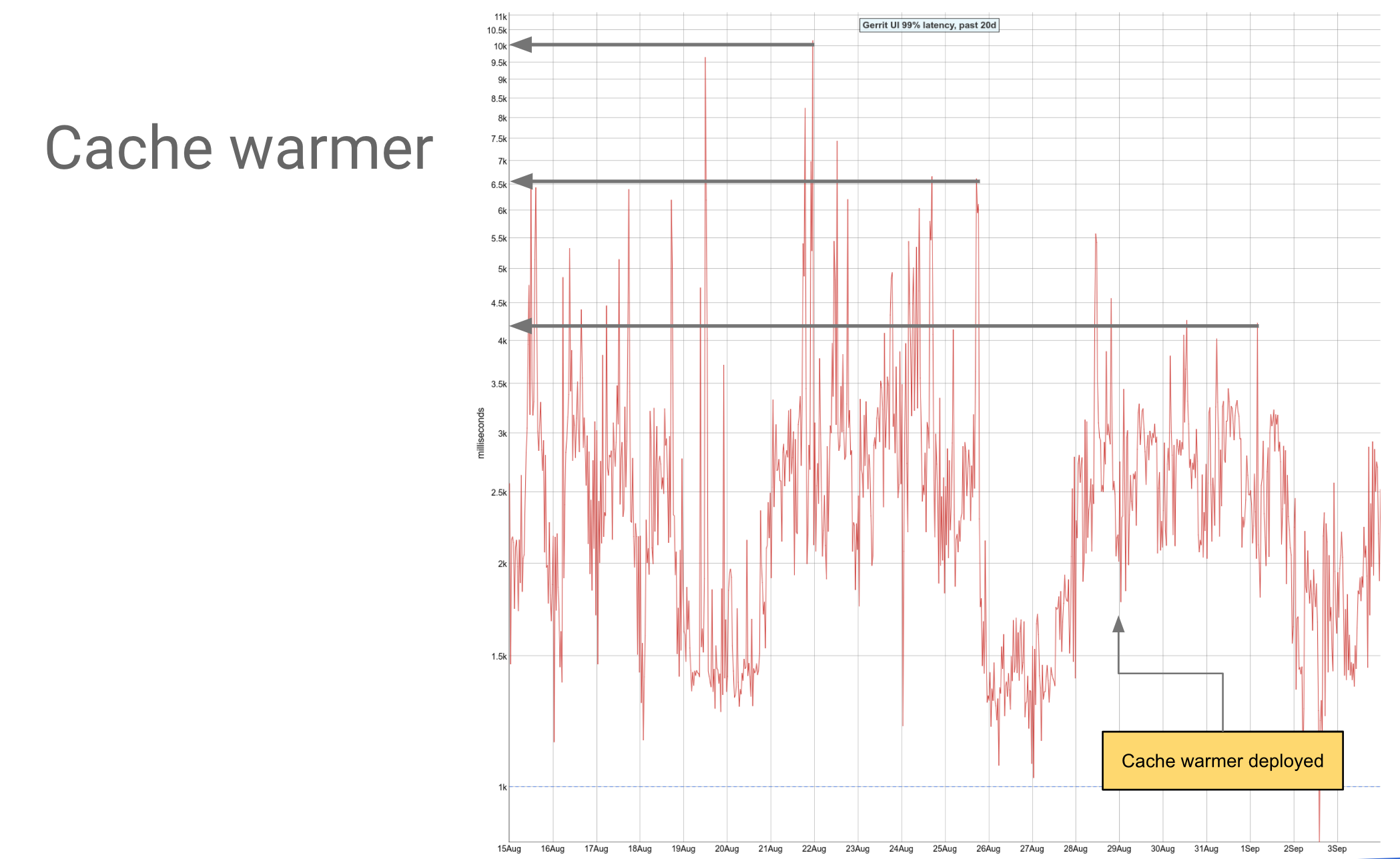
The cache-chroniclemap module confirms to be very active in 2021, with 40 changes all provided by GerritForge. This relatively new module allows existing Gerrit setups to increase the overall performance of all persistent caches, which are vital in reducing the REST-API latency across all Gerrit features.
The checks plugin was deprecated back in 2020. However, it still shows significant changes and investment from Google in supporting the new Gerrit checks-API and UI. However, the rate of contributions is in stiff decline, down from the 324 changes in 2019 when it was still an actively developed project.
The Gerrit Code Review community abandoned the idea of a face-to-face event in 2021 because of the continued global pandemic of COVID-19. Instead, there were two separate virtual events for sharing the news of what is happening on the platform and the expectations from the community.
Virtual Gerrit Contributors’ Summit – 9th of June
The summit was organized by the Gerrit Community Managers and had an amazing audience amongst the contributors. The presentations showed what different teams are working on and reported into the summit notes:
It was the first experiment of an entirely Virtual User Summit of the Gerrit Code Review project history. The challenges were multiple, including the limitations of allowing up to 100s of attendees, shortening the overall time to 3h x 2 days, and still allowing some interactions between the audience and the presenters. After two years of silence, we have finally received some user stories of using Gerrit in the wild.
The Summit has received vast overall positive feedback and rated 7.9/10, making it a fantastic achievement. The quality and interest of the talks were scored even higher, reaching 8.2/10.
Marcin (GerritForge) showed the work done in implementing a brand-new plugin that promises msec latencies for replicating repositories 1000x faster than the current replication plugin.
It was definitely a lot of information and sharing, which showed that the Gerrit Code Review open-source project is alive and active more than ever.
Gerrit features highlights in 2021
Gerrit Code Review has major innovations developed and decisions made over 2021. See below a short recap of the ones that represent a turning point in the evolution of the Gerrit open-source project. Some of them are considered breaking changes and, therefore, need careful analysis and a planned upgrade path.
Speed up of Gerrit upgrade from v2.7 to the latest version
2021 has seen a significant increase in the cooperation and contributions of Qualcomm to the rest of the Gerrit Code Review community, focussed on the speed-up of the Gerrit upgrade process from v2.7 to v3.5. The contributions and cooperation have brought many improvements to JGit and Gerrit and will allow many more companies to migrate faster and smoother than ever before.
JSch SSH library is completed removed from Gerrit Code Review
The quirks and obsolescence of the JSch library has cursed Gerrit’s destiny for years. Thanks to Thomas Wolf (Paranor) JGit moved away from it and rebuilt all its Git/SSH stack on top of Apache Mina. That has allowed to remove the JSch library from the Gerrit dependencies and used the Apache Mina SSHD client stack instead.
Gerrit cannot include or require any commercial product not released under one of the open-source licenses allowed by the project. The ElasticSearch backend has not been widely used in the community anyway, based on a recent survey sent to the community therefore the ESC decided on the 3rd of November that the ElasticSearch backend will be removed from Gerrit core and moved into a libModule.
Submit Requirements waving goodbye to Prolog
The Gerrit Code Review project does not use anymore Prolog rules for the submit rules of the project from the 16th of December. The support for Prolog-less submit rules is now mature and it will be part of the forthcoming v3.6 release in 2022.
What’s coming in 2022?
The future of Gerrit Code Review is bright and full of innovative ideas and improvements on the overall development and CI/CD lifecycle. With the forced remote working of millions of developers worldwide, more and more companies are looking on how to make remote interactions more useful and fruitful, reducing frictions and making the workflow smoother and faster more than ever.
Stay tuned and keep on using and contributing to Gerrit Code Review, one of the most innovative and productive platforms for code review and collaboration.
It is exciting times for the Gerrit Code Review project, which is approaching its 10th anniversary. The very first commit is dated 14th of November 2008, exactly ten years back from the official kick-off the 15th of November 2018 of the Gerrit User Summit 2018 in Palo Alto
commit 23571ab1fa7fedc262d6c21510614353e9d8a4dc
Author: Shawn O. Pearce <sop@google.com>
Date: Fri Nov 14 16:56:58 2008 -0800
Initial project setup of Gerrit 2
Gerrit 2 is a ground-up rewrite of Gerrit, using GWT (Google Web
Toolkit) for the client side user interface and a Java servlet
based backend.
Signed-off-by: Shawn O. Pearce <sop@google.com>
An exciting schedule with talks about new features
The program is now complete and includes a lot of interesting talks about what’s new and noteworthy in Gerrit:
The summit is kindly hosted by Cloudera, the world’s leader of the BigData OpenSource Platform. It is not a coincidence that there are talks about Gerrit and the DevOps Analytics:
Recordings of the Gerrit User Summit 2017 in London
The best way to get ready to the Summit this year is to watch what happened during the past 12 months, compared to what was announced at the Gerrit User Summit held at Skills Matter in Central London back in 2017, leveraging all the free content available on the GerritForge TV YouTube Channel. There is a lot to learn about Gerrit and its related technologies.
2018 is an exceptional year for the Gerrit Community, and this Summit will most likely be the largest ever in the history of the Git Together and Gerrit User Summits of the past ten years.
My name is Martin Fick and I work at Qualcomm as Gerrit Administrator and I have one of the key historical Gerrit Maintainers since its very beginning.
I am going to talk about my experience in introducing a truly Multi-Master Gerrit setup at Qualcomm and learn about the findings and the experiences we made to make that happen.
Let’s start with a question so that we can make this session very interactive from the start.
Q: Who would like to have multi-master in Gerrit Code Review? Why would you need it on your server? Failover? High-availability? Both?
A: All of that but also latency. We have developers all around the world, and we would have at least two datacentres, one in the States and another one in Europe, we were looking for a multi-site multi-master to descreen latency between the sites.
A: (Luca Milanesio – GerritForge). Scalability and elasticity that allows to grow and shrink the instances based on the incoming traffic. Additionally, we would like to have zero downtime and rolling upgrades without stopping the services when moving between minor versions of Gerrit.
Q: (Han-Wen Nienhuys – Google) Let me reverse the question: who is running multi-master and would like to have a single master?
A: (Dave Borowitz – Google) I would love if we had a single server that was powerful enough to serve all our traffic and no latency and we had not had to deal with slow database backends and replication lags between sites.
Q: Does anybody need multi-master? How are you surviving today if you needed it?
A: Right now we maintain a second master server for DR purposes, is a passive standby backup server. If our master went down, we would have to failover to it.
A: We would need multi-master soon. Currently, we are experimenting the HA-plugin as a fallback solution, but we are working towards achieving multi-master so that we can scale up, which is mainly our primary concern here.
Gerrit Multi-Master requirements
There are needs that I hear from the audience, high-availability, scalability. Not necessarily the same requirements and I believe that multi-master would address some of those. What’s important is that everyone is focussing on their needs and think about how they can approach those first instead of going to the “big everything” solution.
We have high-availability as an issue somewhere, so we want better availability. We have some scalability issues as well. We do have some site issue at times but we most generally deal with those through slaves all over the world, between 50 and 100 and we primarily have one data-center in San Diego USA. If that goes down, nobody is getting anything done even if Gerrit is up, that makes failing over to other sites not particularly useful right now.
Our current focus is on better availability and better scalability at one site.
Scalability problems at Qualcomm
We have a pretty hefty load, we have around 6k projects, but our load is enormous on a few large projects. They are not massive projects but they are significant from the standpoint of having many changes on them, and there are a lot of users using those projects. Mainly a few kernel projects are used, and even if there are many other little projects, most of the users are pushing to those single projects.
We are a single tenant server, so we are primarily dealing with that. Other people need other Gerrit servers, and they manage their own, but at the moment we don’t have to deal with those. However, if we had a more scalable system, then I believe multi-tenancy would become the next problem on the horizon. If I had a great scalable system why am I creating this instances here and there I would instead put all of them on the central system so that I can manage one system. But then I would have the problem that Gerrit doesn’t currently handle multi-tenancy well. Maybe is because we don’t have a multi-master system and then we are not ready to put everything on one server anyway. If we are starting having a multi-master solution, then multi-tenancy is then something that would become more interesting.
On one server we have around 6k projects, the main project has about 1/2M refs, and we have in total 2.3M changes on the entire server.
I like to break down the scaling topic into two different ideas: horizontal scaling and vertical scaling. In our area, we need to scale vertically more, while horizontally is where you have lots of projects and users and vertical they are more concentrated on a few projects.
Stairway to Gerrit Multi-Master
Here is what we decided to do and we decided to build it incrementally. These are the four phases in which we have approached it.
Step #1: Active/Passive
We have an active/passive standby, and we started doing regular failover. Let’s face it, if you have a failover machine that you probably have never failed over to, it would probably not work.
We have so much software around the Gerrit ecosystem, we have a lot of scripts, cronjobs and things that run on our server, and they use a lot of software, there are a lot of Python hooks and stuff like that.
All that software gets updated. If the failover machine is not updated through the same process and tested, there could be missing dependencies, wrong package versions, etc. Maybe some hacks or links on the filesystem that is pointing over here and not over there or maybe filesystem positions are different and things like that.
Before even dreaming about multi-master you need to have a system to have your server systems consistent. If you don’t think that your organization can do that and make two systems precisely the same, you are not going to be anywhere near ready to start doing multi-master. If you are a large organization that has a lot of history, it’s a more significant challenge. If you are starting from scratch it is a lot easier, think about that from the start: how can I focus on repeatability and deploying the same stack of software to multiple servers, and then concentrate on failing over.
Sometimes this year around February/March, we started failing over, and now we are trying to fail over weekly. We have been doing that for getting the Team used to it, to ensure that our processes work.
Step #2: Active/Hot Standby
Then we moved to hot-standby. The difference here is that the passive node had all the software in place but was not necessarily running. So now we just started the other server, but only nobody was pointing to it. The active standby gives you the opportunity to test the software you have around your Gerrit master. If you have hooks or cronjobs, try to run them on the failover server, even if it is not the active master. Do you have the coordination needed? Do you have locks in place? If you are doing repository repacking, can you do it on both servers at the same time? Do they conflict with each other?
The assumption is that you have a shared repository on the backend such as an NFS and thus activities like repacking need that coordination. And you need that stuff to work before you can go to multi-master.
Step #3: Active/Active with Round-Robin DNS (low tech)
The third step which is where we are at is active-active. We chose this as a simple low-tech and easy to backup solution: round-robin DNS. It sucks from a load-balancing standpoint and for the failover recovery, but it gets us having traffic going to two servers. We have been running that for quite some time now, 15h!
Step #4: Active/Active with Load Balancer(s)
And the next step is of course to have a load balancer. We have a load-balancer setup that we use for slaves. It is much harder to back out because you have to set IPs to have DNS in place pointing to them, but we plan to transition to that.
What Gerrit data to share in a multi-master setup?
In a single-site Gerrit multi-master setup, you necessarily need to have shared Git repositories, you don’t have to share your H2 caches because you need them on each of them and then the ReviewDb needs to be shared until it goes away with Gerrit Ver. 2.15.
Sharing sessions
There is other stuff you need to share, like web sessions.
When you log in on with your web-browser, and you hit one machine, your browser keeps track that you are logged in with a cookie on your browser while the server keeps track of it on a shared persisted session. If your next hit goes to the other server, you don’t want that user to be kicked out, so you need to share the server session data across nodes.
In 2014 we developed the websession-flatfile plugin, and that helps taking care of sharing web sessions, and I know that a lot of people used that already for HA solutions. It is straightforward, just stores the sessions on the filesystem and if you are using Git repositories on NFS, just put them there also and share them.
Sharing events
The other thing that you require to share is the events data. Our events need persistence on the server side, and we share them on the filesystem too. That allows to share them across masters also. If you connect to one of our masters through SSH, you get events from both of the masters. It’s a poor man’s sharing, and it is a simple set of files that is there and is shared. One thing that we realized using multi-master is that possibly your events are going to be disrupted much more. Even if you think you have high-availability, the client can only connect to one server. So it doesn’t matter if the cluster has even ten servers, the client is still attached to just one of them.
Generally speaking, most of us want to do rolling upgrades, and that would bring one server down, and that is one of the reasons we want to go to multi-master. If you are doing that frequently, you are disrupting your SSH clients and for those who are permanently connected such as the stream events even more.
I have contributed a new stream events plugin, and I merged it upstream during the last hackathon so you can download it if you want to look at it that helps you to store stuff. You get the added benefit to add some flags to get IDs on your events, and then replay IDs. Since they are stored on the filesystem, when you connect you can tell what the last ID was you connected to, and you can start receiving all the events after that. It does it through the same interface of the old stream events: you drop it in, and it works. It respects Gerrit permissions, just like the core plugin does so that the user that is connecting will see only the events of the projects and branches he has access to.
Coordinating other processes on the Gerrit nodes
As processes on our Servers, we have the Gerrit JVM, but also we have a lot of hooks, some of them run for a very long time. You need to get those to run on both servers. We have a few cronjobs that do repack, we have others that are checking if users are active or inactive on LDAP and update their status on Gerrit and check their e-mails to make sure that they are really what they are saying. And last we have some various maintenance cronjobs.
We focussed on the background stuff first because you need to get that done anyway and you can use it as a peace mill, and we tried to coordinate those first.
We went for the low-tech solution, sharing as much as possible via the filesystem.
Years ago I created a lock implementation based on the filesystem. It is similar to an echo PID to a file but is a lot more robust and can recover deadlocks as long as he can contact the other server using SSH and does all of that automatically.
We use that as a primary method to coordinate things, so on top of that, I have built a scripting queue executor for hooks. Years ago before multi-master, we had issues with hooks that were running for too long. If you remember how Gerrit manages hooks, runs from the Java process with a queue that runs only one at a time. If your hooks take for instance three minutes, you may build up a backlog on your server. If your node goes down, you lose that backlog. What we decided years ago is to have the java process just to write the hook onto a file, and then we have a schedule that runs them in the background. The queue in Gerrit is then always at zero, it takes less than a second to write to the file and then it is done.
We made that multi-master friendly, but because that queue uses the locks, it just worked when we run them on more than one master. One server can write the hooks to a file, and the other could be the one that runs it, and thus it distributes the load in that way.
Gerrit cluster events
If you think about it, there are a lot of things that are hooked into the startup, so I just put a little hook framework that checks if the servers are running and check if the other nodes are running by ssh-ing into them. That allows identifying that if the two servers are down and one goes up, then your node is starting, but also your cluster is starting. And if the other just comes up you are not starting the cluster, but you are starting the node. Then if one node goes down, you haven’t stopped the cluster but you’ve stopped only the node, and if the other goes down you have now stopped the cluster.
I have created a little hooks framework so that you can plug into those events, and then you can do things based on that. For example, at the startup of any node, we are going to start the hooks just to make sure that they are running. But then when you stop a node we disable them only when all the cluster goes down. If one node goes down, the hooks need to be still running because they can contact the other server because they go to the domain name and not to the local server.
We plan to use the hooks framework for replication too. Currently, if you are familiar with the replication plugin, at startup try to replicate all the project to all the slaves to see if they are up to date. The theory behind it is that data could have been modified behind Gerrit back and possibly because when the server was shut down, it was in the middle of doing something and never finished it. In a cluster situation, if at any time something goes down, it could have been in the middle of replicating, and the other node won’t know. When any server goes down, you don’t want to replication, but there is no need to do replication at startup when any node starts but only when the cluster starts.
If there is at least one node up, when the other comes up you don’t want to do global replication. You could replicate it, but it would be a just extra load.
Caching across the cluster nodes
You can do some coordination better than the simple filesystem, for instance, the high-availability plugin does one to one connection, you need to configure the IP of the one master to connect to the other and they connect between each other. That works for two, but it is not a super-scalable system, it is an N-squared problem. Eventually, you want to move to a pub/sub system for things like that.
Something I haven’t mentioned yet it is what we had to do coordination wise it is caching. The high-availability plugin evicts caches, but we don’t do that yet, we consider it an optimization. The primary remedy is just to reduce the time on the caches, mainly decreasing to the values that we had on our slaves. Mostly you probably have lower cache time on your slaves, to make sure that you are checking your projects’ ACLs and your group memberships a little more often than your master. The Gerrit master knows when things get changed without the need to evict any cache, but the slaves do not know when they changed. We made the masters a little bit dumber like the slaves because they know when they changed something but they don’t know when the other masters did. As long as you are fine with the delay, let’s say 5 minutes, then it means that when you change an ACL, it may take up to 5 minutes to be seen by the other masters.
Demo: make your laptop a multi-master Gerrit server
As anybody tried to run two Gerrit instances on the same laptop?
The first problem that you will see is that if you point them to the same H2 caches it will just not start. But if you run init on two different directories and you don’t share any data on the two masters, then you need to go and modify your gerrit.config file to say to start sharing something.
Out of the box sharing abilities
You need to reconfigure the Database to be the same, and you should use a PostgreSQL or MySQL because the default H2 won’t allow any sharing. I am running 2.14 here, and I did not share the indexes, so they are going to be out of date for this demo. The user’s sessions are not going to be shared, so you need to configure them manually to make them shared.
If you use the websession-flatfile plugin, it will put the sessions on the filesystem and then you can share them on the filesystem.
Lastly, the stream events won’t be shared, but most of the rest will just work.
I am about to run stream events on both masters, on the left screen I am connecting to port 29418 and on the right screen on port 29419.
Now if I go to the WebUI, on port 8080 I have the same master of the one on the left, and on port 8081 I have the one on the right.
I am going to create a project using the master on the left: I hit create and you can see that the events appear on the stream events on 29418 but not on 29419.
Now let’s try to go to port 8081, and I have to log in again because the websessions are not shared yet. I am showing to you what it does out of the box. The events now came on the right screen but not on the left one.
The two masters are just pointing to the same Git data: I am trying to make them multi-master, but so far it is not working very well.
Adding plugins to share events and sessions
So, let’s step in and start deploying some new plugins. What we did with the plugins is to create a new one called “events” so that when you want to get the distributed events, you just call “events stream” where “events” is the name of the plugin and stream is the command.
What we did in the core is to remap the actual “gerrit stream-events” to “gerrit stream-events-core” so that you can still get to it if you want and this helps for debugging. And then we pointed the “gerrit stream-events” to “events stream” so that users will automatically get the new plugin events so that to them in invisible.
I am now on 8081 on the browser over here, create a new project called ‘Luca’ and here we go, events are generated on both 29418 and 29419 ports. You may have noticed that showed up on the right first and then to the left.
The events are on the filesystem, so the server just have to pull and here I am pulling every one second, but if something happened on this server, it will automatically catch-up on all the events generated on the other server as well.
The pulling is a backup: the events should come up even without a pulling mechanism. If we eventually had a pub/sub mechanism, I would still suggest keeping the pulling. Events are inherently unreliable and will get lost: you need a pulling mechanism in place if you want true reliability. Pulling is not great, but it is reliable. Events are effectively an optimisation for speed.
Let’s go back now to the other server at port 8080, and I did not have to login because the sessions are now shared and kept across masters. I create a ‘hugo’ project, and it came up pretty quick on both stream events on both masters.
So we have now shared web sessions and shared events. That’s in 2.14 but to make it a true multi-master you would need to share your indexes as well but as we are still on Gerrit v2.7 at Qualcomm, we don’t have an index and we don’t have to share it.
More exciting features in the events plugin
We’ve been using the events plugin in a single-master scenario since early this year, and it has been pretty reliable. I can show some other exciting features are in there. There are some new options here, IDs and resume after. If I give –ids and –resume-after 0, then it returns all the events since I started the instance, and I initialized it. Even if the server started and stopped a bunch of times, I still have all those events recorded. The IDs of the event have two parts of it: the left part is a UUID, and a right portion is a number. The idea being that this is your file store and this is your event store, a unique id associated with it. If someone deleted it on disk, it would create a new one. The idea is that if you had event 1M and someone has removed the file store, and you ask after event 1M, the new event store will restart at zero, and you get nothing. By having different Ids if you ask “give me all the events after ID 1M” then the UUID changed, and it realizes that you need everything. That allows giving some little extra safety. The plugin works on Gerrit v2.14, and I made some changes to make it work on v2.15 as well.
Q: If you use Hugo’s high-availability plugin for the index, you basically can probably do multi-master right now. Why then are you guys not running multi-master? Are you guys concerned about NFS and ref-updates?
A: (Hugo Ares – Gerrit Maintainer) We use it in failover mode for the only reason that if you just have a little bit of load, you are safe and consistency will be kept. But if you push it a bit more then sharing Git repositories from different machines in write mode doesn’t work. If you have two computers writing precisely to the same Git repository to the same branch to the same file at the same time, you are going to lose history, and we know because it happened for us. That’s why we don’t do multi-master right now.
We have been writing for several years to the same repositories from different machines using NFS and we haven’t found any issues because we do repack all over. Perhaps we have different NFS settings or just a different implementation.
A: It did not happen that often, but at least a couple of times and that’s why we don’t do it. We mainly use the high-availability plugin for evicting the caches so that we don’t need to lower the cache settings because they are removed automatically and takes care of the events in a slightly different way and trigger the reindex of the other copies. We can keep nodes down during the day, and the people would not notice any difference at all, no deal. We are just a little bit reluctant to write from both nodes, but that’s the plan.
So here you are already on a “multi-master ready” setup. We hear about your reports of the JGit problems, and we will be keeping an eye on it. I am confident we can fix any issues that could show up over here, understanding how Git works on NFS. There are some tricks that we can pull from our code base.
The (in)famous NFS stale file handle bug
I know we fixed in the past a bug on JGit to handle NFS: when you delete a file, and someone else tries to access it from a different node gets a stale file handle error. That’s the main problem you are running into and we encountered and fixed some of those issues on JGit, and there are possibly a few more left here and there probably. The workaround to the stale file handle problem is just to make a copy or a hard link to it and keep it for a bit more time and remove it later, and then you are fine. Generally speaking is just the brief moment after the operation that would be a problem. It is what it would happen on a local file system anyway: if you delete a file that was still opened by other processes, the inode will stay there for a while until it gets unreferenced. That is the main issue we have been running into, and most of the other problems have been already fixed on JGit.
Distributed GC on a multi-master setup
We have a distributed Git GC and repacking relying on the SSH filesystem lock mechanism that I talked before. We basically have a list of repos to be GCed on the filesystem. All the nodes are saying: “I am going to this,” and another node says “Oh, good, then I am going to do this other one” and in this way, the GC load gets fairly well distributed and you get only a few hours to get through the whole thing. The lock allows preventing to step on each other toes when doing repacking. As far as the backup is concerned, we do a rsync and take database dumps, so that we don’t get inconsistent snapshots. You need to get your Database backup first and then the repositories next. If you are running an older version of the DataBase backup, you are generally safe because you don’t risk to have references to inexistent objects.
Questions
Q: I may have missed one point: the shared filesystem approach is assuming you are not doing multi-site, right? If you were doing multi-site, it would add extra latency that would introduce more problems and add more latency which was the problem you were trying to solve.
A: Yes, that’s correct. We are not interested in multi-site because there are a lot of downsides to it: it is a lot more complicated and makes your writes a lot slower while the reads would be faster. When you are pushing to gerrit-review.googlesource.com you realize that is not the best experience. You need to go to a quorum to the majority of the people around the world to get the agreement of the majority of them to finalize a git push operation. Single-site is the first initial step for us, multi-site requires a very different approach. You need to get the Git objects to be replicated and then having somewhere to store the refs that have to be shared without a system like Google’s database that assures that the refs are replicated around the world. It is not impossible; we made some experiments on it. A few years ago Dave Borowitz uploaded a ZooKeeper implementation that does the refs sharing, but that only does the refs. Then you need to do something for the Git objects replication. You could use the regular Git replication to do that, but you need to come up with a bit of magical ref scheme that does the job behind the scene.
A: (Luca Milanesio – GerritForge) Last year at the Gerrit Hackathon in Mountain View, we presented a new implementation of the “missing bit” you were talking about. It an OpenSource project based on JGit and leverages Apache Cassandra for the Git objects, while uses the ZooKeeper implementation for the refs you mentioned. We are making a lot of progress on the project and it will soon be possibly THE solution for Gerrit Multi-Site.
Q: (Luca Milanesio – GerritForge) We found out and fixed recently in JGit a problem with the cache consistency: it was reported on NFS but had nothing to do with it. When JGit was not able to open a file for whatever reason, NFS latency, maximum opened files, whatever, then the packfile was removed from the list of packs because it was considered missing. Then JGit started to failing fetching objects from the repository, and the people were panicking thinking that their Git repository got corrupted. But then, why the other nodes accessing the same repository did not have the same problem? Then “magically” the problem disappeared when you restarted Gerrit. The problem has been fixed in recent versions of JGit but is still there for the version you are currently using as the basis of Gerrit v2.7. Did you find the same problem? How do you manage to keep up with the recent releases of JGit but staying on Gerrity v2.7?
A: We have an old version of JGit, but we have put our patches on it. I believe we discovered and fixed a bug like that years ago. We ported a series of patches upstream and we a set of performance improvements on our branch. However, it is hard sometimes to get stuff merged on JGit; there are not enough maintainers to even look at the thing.
My name is Luca Milanesio, and I work for GerritForge. My talk today is about plugins and how to create them using scripting languages.
Gerrit plugins, where it all began
My contribution to the Gerrit Code Review project started in 2011 with the introduction of plugins. To understand where we are coming from we need to back to those times when the project was just born a year earlier. Gerrit was mighty since its very beginning, and different companies that used and contributed to the tool had tailored the code base to their specific needs. When I joined the GitTogether conference in 2011, almost every user was talking about their fork of Gerrit. Forking is excellent especially in OpenSource because you can customise a project as much as you want and, we were all excited about the growing popularity of GitHub and forking was a popular concept. However, keeping a fork up-to-date is not as easy as you may initially envision. Moving on with the upstream releases is hard when you are working on a fork.
Back in 2011 when I was at the conference, I thought: “how can the Gerrit project evolve and grow if we are all working on forks?”. My way to convince the Gerrit Community to change that status quo was inviting Kohsuke Kawaguchi, the Jenkins CI project founder, to the summit. Jenkins CI is wholly based on plugins while the core does not do much: the plugins are making the whole thing work as a CI.
That was enough to convince the community that a change was needed and, during the next Hackathon in 2012, I wrote the initial version of the Gerrit plugin loader and the first “Hello world” Gerrit plugin was born.
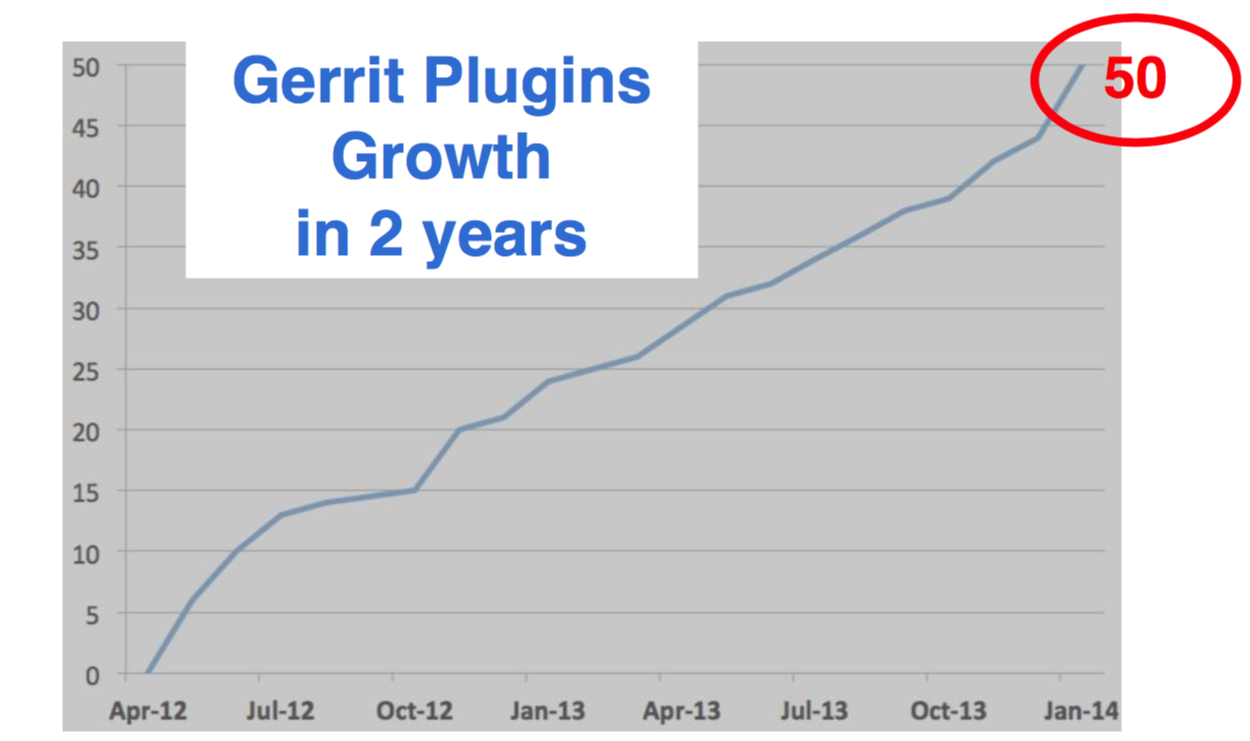
The introduction of scripting languages
After two years, Gerrit had only 50 plugins. If you had looked at Jenkins, at that time they had over 600 plugins, ten times as many plugins compared to Gerrit. Writing a new plugin for Gerrit was still too hard for most developers and administrators.
To develop a new Gerrit plugin you needed to know way too many things and have many skills: a different build system (Buck and now Bazel), having a full development environment and all the required dependent packages.
We still had new plugins because some people went through the initial pain of setting up the environment. However, for a project to thrive, you need to get people together and embrace a diversity of skills to allow people to give the best of their knowledge.
Maybe the typical Gerrit admin is not a Java Developer, possibly could be more familiar with Groovy because the Ruby syntax is used a lot of DevOps tools. Others are more familiar with Python, and if you accept what they can contribute, the project can benefit from many more experiences from different people and backgrounds.
What does the community think about it?
Once I shared my ideas with the community, the feedback was great. However, different people with different backgrounds started asking to use very different languages, ranging from Scala to Groovy and Python. Then I realized that supporting one scripting language would not have been good enough for most of the people.
“Hello world” in Groovy
To give you an idea of how easy is to write a new plugin in Groovy, see the following example.
import com.google.gerrit.sshd.*
import com.google.gerrit.extensions.annotations.*
@Export("groovy")
class GroovyCommand extends SshCommand {
public void run() { stdout.println "Hi from Groovy" }
}
It is straightforward to write scripting plugins: put the above content in a hello-1.0.groovy file in the Gerrit’s /plugins directory and as soon as the file is saved the plugin is there and will be loaded in Gerrit within a few seconds.
The way that Gerrit recognize this file being a plugin is through its .groovy extension. The file name denotes both the plugin name and its version, delimited by the ‘hyphen’ on the filename. In this example the file hello-1.0.groovy identify a plugin called ‘hello’ with a ‘1.0’ version.
One warning about Groovy: it is a language that relies on Java Reflection for method invocation. Reflection is a capability of the Java Runtime and enables methods discovery which is handy to use but is slower than a native Java language.
The drawback of the ease of use of the Groovy language is the CPU cycles at runtime.
The beauty of using a scripting language for plugins is the speedup of the development cycle: as soon as you edit the Groovy file on the file system, the old plugin is unloaded and the new one loaded in Gerrit. The plugin development lifecycle becomes so much faster compared to the traditional Java application development.
Develop Scripting plugins using Docker
Gerrit is provided as a Docker image on DockerHub. The ‘gerritcodereview’ organization has an image name called ‘gerrit’ with all the versions available denoted as tags since Ver. 2.14. Earlier versions of Gerrit docker images are available on the ‘gerritforge’ DockerHub organization.
In the following example I am running Gerrit 2.14.4 on Docker fetching the image directly from DockerHub:
docker run -ti -p 8080:8080 -p 29418:29418 gerritcodereview/gerrit:2.14.4
In the above example, Gerrit is exposed through HTTP on port 8080 and exposes its SSH interface at port 29418.
Docker is a system that allows running containers, which are application “packaged” with everything needed, including other components of libraries of the underlying operating system. The only requirement on your physical host is the Docker engine, which exists nowadays for MacOS and Windows other than Linux where it was originally designed. Whatever operating system you are running on your laptop, Docker is there.
Docker can be handy for all the contributors that are not familiar with Gerrit Development Environment. There is no need to know or install anything on the local box, other than running the Gerrit Docker container. When I am running Gerrit in this way in this example, it starts straight away, with zero installation steps or configuration.
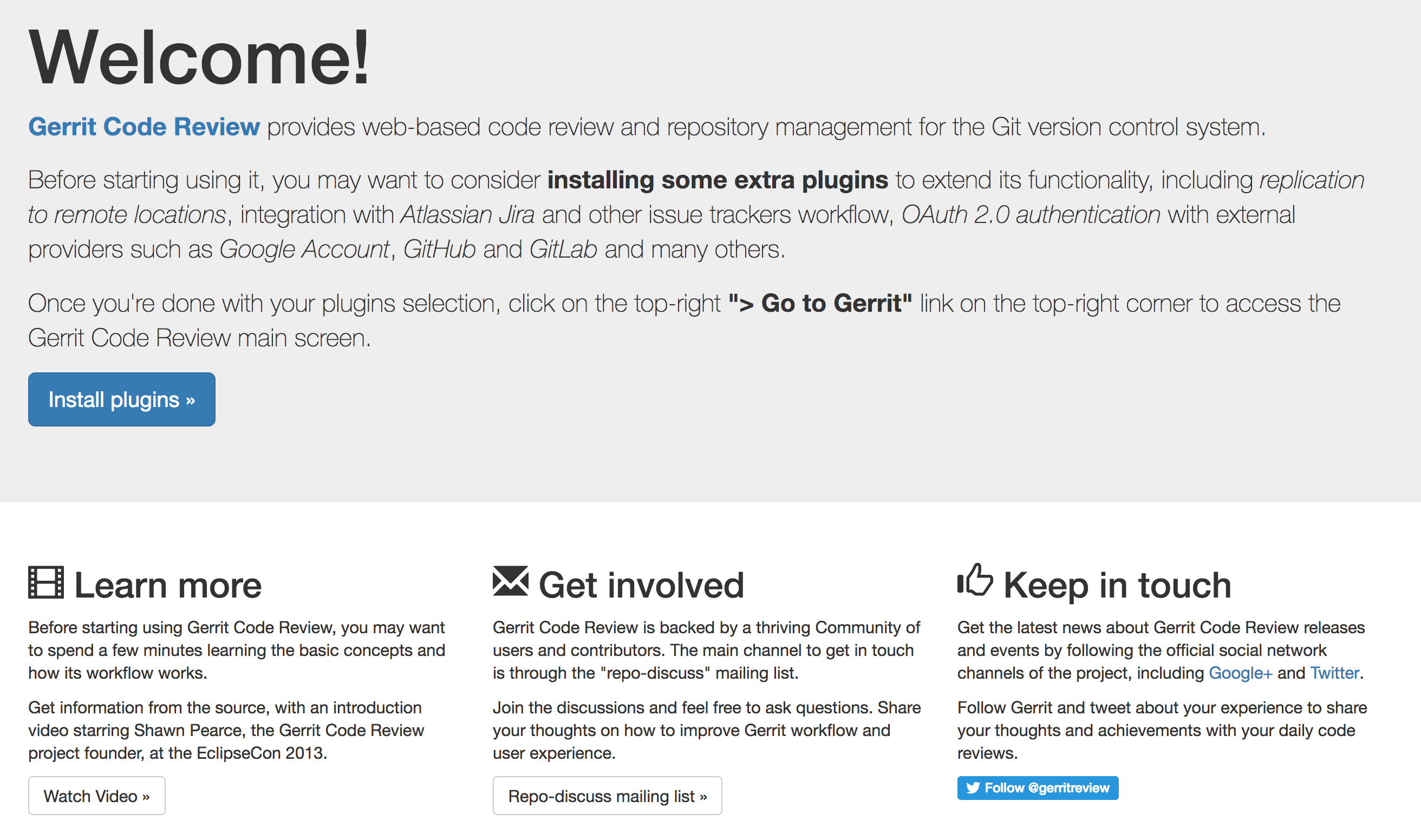
Gerrit out-of-the-box experience
The second significant value of the Gerrit Docker container is that includes an out-of-the-box configuration, a welcome screen, and the plugin manager. It consists already a set of components that, if you are not familiar with Gerrit, will help you a lot to understand what is Gerrit and how to use it.
As you can see from this screen, Gerrit has started, and if you navigate to http://localhost:8080, it shows you an initial welcome screen.
Historically the very first screen, once you have installed Gerrit, was a blank screen. I remember a few years ago people coming to me saying that as new Gerrit users they were quite confused: they just did not know what to do with the initial blank screen. In Gerrit Docker, the initial screen is a “Welcome” which is a beautiful thing to say to people that you did not know that came to your house. Additionally, it provides some useful links and information to install plugins, which is very important because Gerrit without plugins is missing some fundamental parts of its functionality.
Playing with Gerrit Plugin Manager
By clicking the “Install plugins” button, you reach the Gerrit Plugin Manager screen. For all of those who are familiar with Jenkins, it provides precisely the same functionality as in Jenkins. If you type ‘groovy’ in the search bar, you can easily find where the Groovy scripting provider is, and you can install it with a simple click. That is the plugin you need to tell Gerrit that from now on, every file in the /plugins directory with a .groovy extension is a plugin that needs to be parsed and loaded at runtime.
You can discover and install other plugins as well. For instance, typing ‘github’ would list the integration of Gerrit with GitHub authentication and pull requests, or typing ‘jira’ would return the association and workflow integration with Jira Tickets.
The plugin manager is a fantastic discovery mechanism to understand what are the integrations available for Gerrit Code Review.
The plugin manager automatically discovers the versions of the plugins that are compatible with the Gerrit you are currently running and, when you click ‘Install’, it downloads them and installs them locally. When you are done, just click on the top-right link “Go To Gerrit” and you are straight into Gerrit UX.
How we have a running Gerrit instance that has installed all the plugins I need, including the support for Groovy plugins.
Writing plugins in Scala
If you need want to leverage the Gerrit scripting plugins, but you need optimal performance at runtime, you can use a different scripting language such as Scala.
The Scala language allows compiling into the native Java bytecode; it does not use reflection for method calls and, for some operations could be even faster than the Java language itself. See the same hello world example but rewritten in Scala.
import com.google.gerrit.sshd._
import com.google.gerrit.extensions.annotations._
@Export("scala")
class ScalaCommand extends SshCommand {
override def run = stdout println "Hi from Scala"
}
When I showed this to the community people got so excited and started writing tons of scripting plugins.
What scripting plugins do in Gerrit?
Admin tasks as SSH commands
Sometimes Gerrit admins need to automate specific tasks, however, coding an external script could be slower and difficult to implement. Inside Gerrit, there are already a lot of objects which represent pre-processed in-memory entities ready to be used. It makes sense to leverage all the information that is in-memory already and write new SSH commands like Scripting plugins to control admin tasks remotely.
Scripted REST API
At times you need as well to tailor existing Gerrit REST API to your needs. For instance, imagine that your company has specific policies for requesting new repositories: why not then creating a new ‘Create Project’ REST API tailored for your needs using the Scripting plugins and expose it through a company HTML form? You can do it without the need to be an experienced Java or Gerrit contributor and using a simple Groovy script for the new REST API.
Low-footprint hooks events
A third option is fascinating because, before the introduction of Gerrit plugins, the only way to react to Gerrit events was through hooks or stream events. Hooks are a traditional Git mechanism and, in Gerrit, have a scalability problem: they are invoked for every project and every event that happens anywhere and spawn a different asynchronous process. Over time the extra processes created can cause a significant overhead for your super-busy Gerrit server.
When a hook script needs to read from the Git repository, it would then need to process from scratch the packfiles from the local filesystem, uncompress and parse them in memory over and over again, which could slow down your server significantly.
If you are implementing Gerrit events using plugins, the same processing could be ten or even hundreds times faster.
This week we are going to publish a talk from the Gerrit User Summit 2017 about Gerrit and Jenkins used together. It is a real-life story on how to set up a CI/CD pipeline for a massive traffic OpenSource project such as Gerrit Code Review and the learnings of how to manage the storage and consumption of the Jenkins build logs and the associated meta-data.
Even if you are not a Gerrit Code Review user, the learnings of this talk are going to be exciting and useful for any high load CI/CD pipeline project with Jenkins.
GerritForge: Gerrit Code Review and Jenkins expertise
I am part of GerritForge, a London-based limited company not specialized in Gerrit, as the name would tell, but also on Jenkins, Continuous Integration and Delivery. Why don’t we use our skills to serve the Gerrit Code Review project? A couple of years ago the project did not have an official CI yet, so we said: “why not help the project and set up an official pipeline to verify all the incoming Gerrit changes to the Gerrit Code Review project itself?”
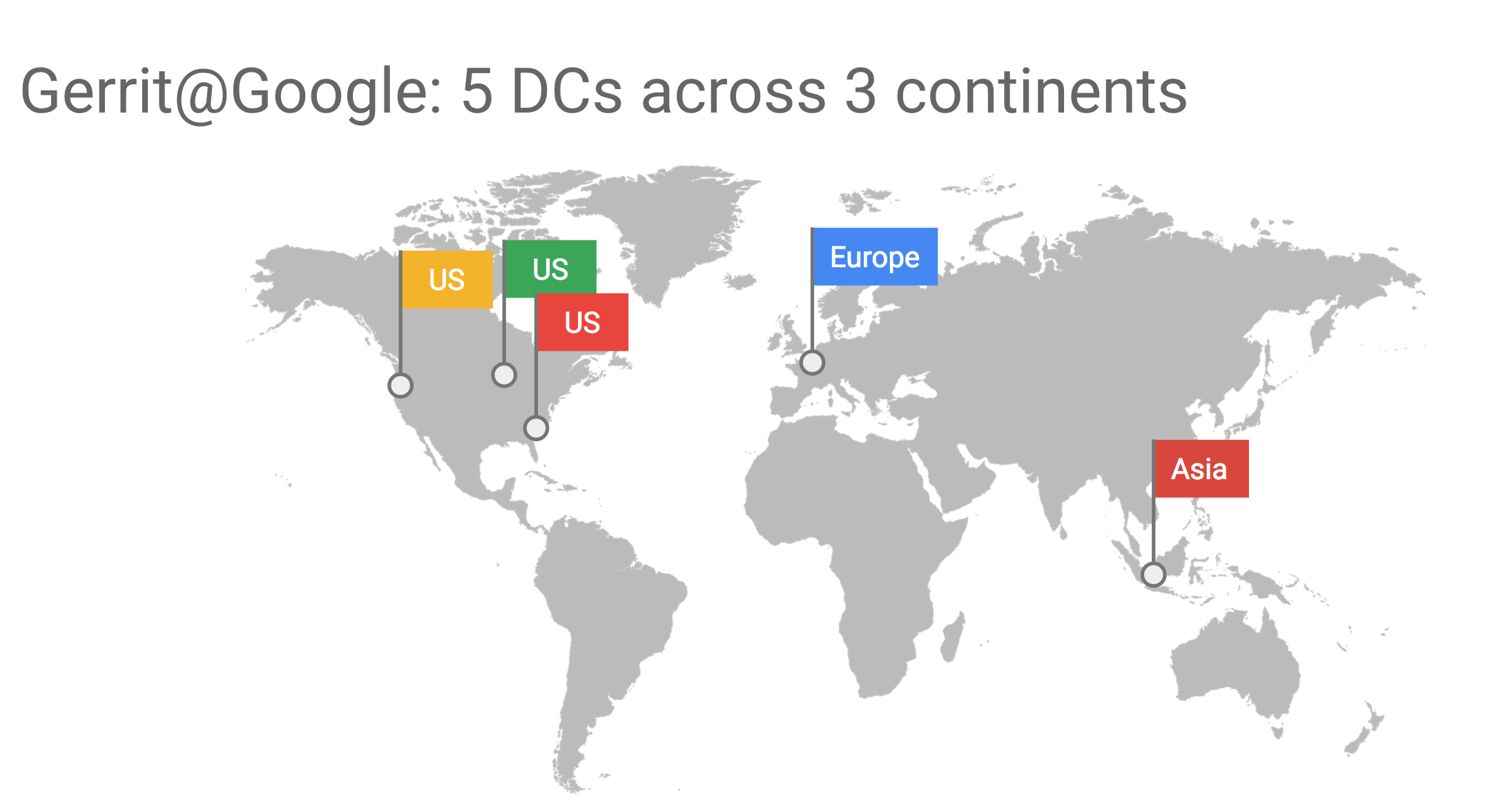
We then created https://gerrit-ci.gerritforge.com and, as you can see, it is nowadays a jam-packed CI system. We have been running a Hackathon over the weekend, and now, even while people in this room are following this talk, new changes are produced, and reviews are getting pushed to Gerrit, and that keeps our CI busy all the times.
We have a lot of slaves, some of them are provided for free by Google and others are paid by GerritForge. We have been running this service for the last couple of years, and even non-contributors to the Gerrit project like most of you guys are possibly using it for downloading some useful artifacts such as the Gerrit plugins. Additionally, if you want to download and demo the latest and greatest version of Gerrit master, as we just did with some of you before lunch, you can use the Gerrit artifacts on Gerrit-CI instead of building it yourself on your local box.
Gerrit-CI pipeline walkthrough
Let’s have a look at how Gerrit-CI works. You can log in with your GitHub credentials, and then trigger builds for your Gerrit Code Review contribution using a job called “Gerrit verifier change”. That is the most important job of the pipeline and it verifies every single change we make on the Gerrit Code Review project.
How can you manually trigger the build and verification of a change in Gerrit? You navigate to https://gerrit-ci.gerritforge.com/job/Gerrit-verifier-change/ and click on “Build with parameters” link. You enter your change number and then click “Build”: it is straightforward.
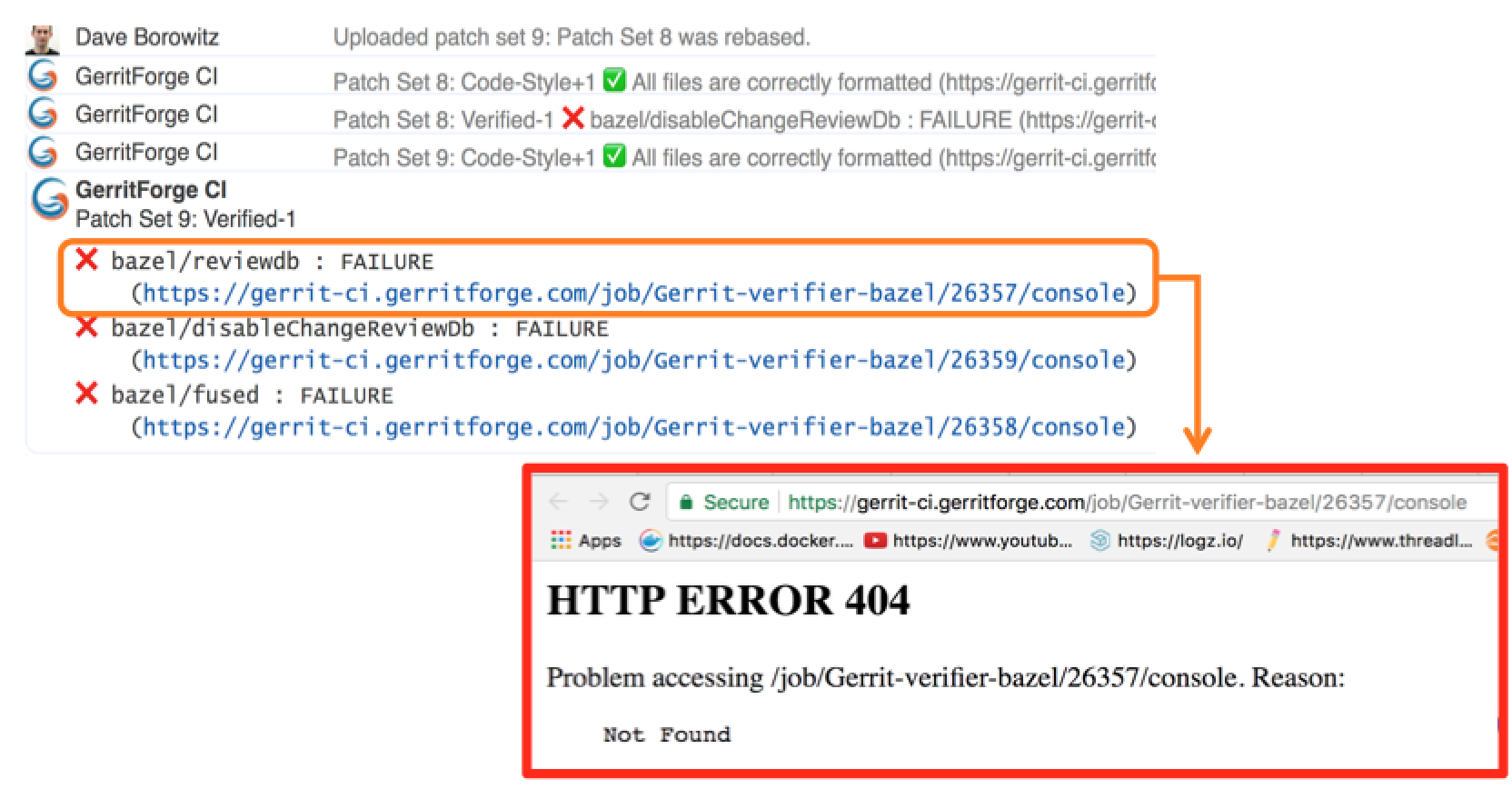
What this job does is triggering a workflow developed in Groovy language which it will provide at the end a series of feedback messages to Gerrit. When you go to https://gerrit-review.googlesource.com and list of open changes, you will notice that some of them by one guy that is called “GerritForge CI”. That means that our CI works, yeah!
At a certain point in time, someone in the Gerrit mailing list said: “Houston, we have a problem, we are too productive! We have produced so many changes and patch sets that the time you finish to build a change, we have already produced other 300 patch sets on that job and the build logs get lost”.
The Gerrit change verifier workflow
Let’s go back for a moment to review how the workflow that we came up with works. It does not rely on the Gerrit Trigger plugin, the de-facto out-of-the-box Gerrit/Jenkins integration that most of the people use, but rather on a complete “new thing” that we have built ad-hoc for our purpose.
We couldn’t use the Gerrit Trigger plugin because of two reasons:
Google data-centers do not allow incoming SSH connections
SSH stream event channel would not have been good enough for us, because of the parallelism needed.
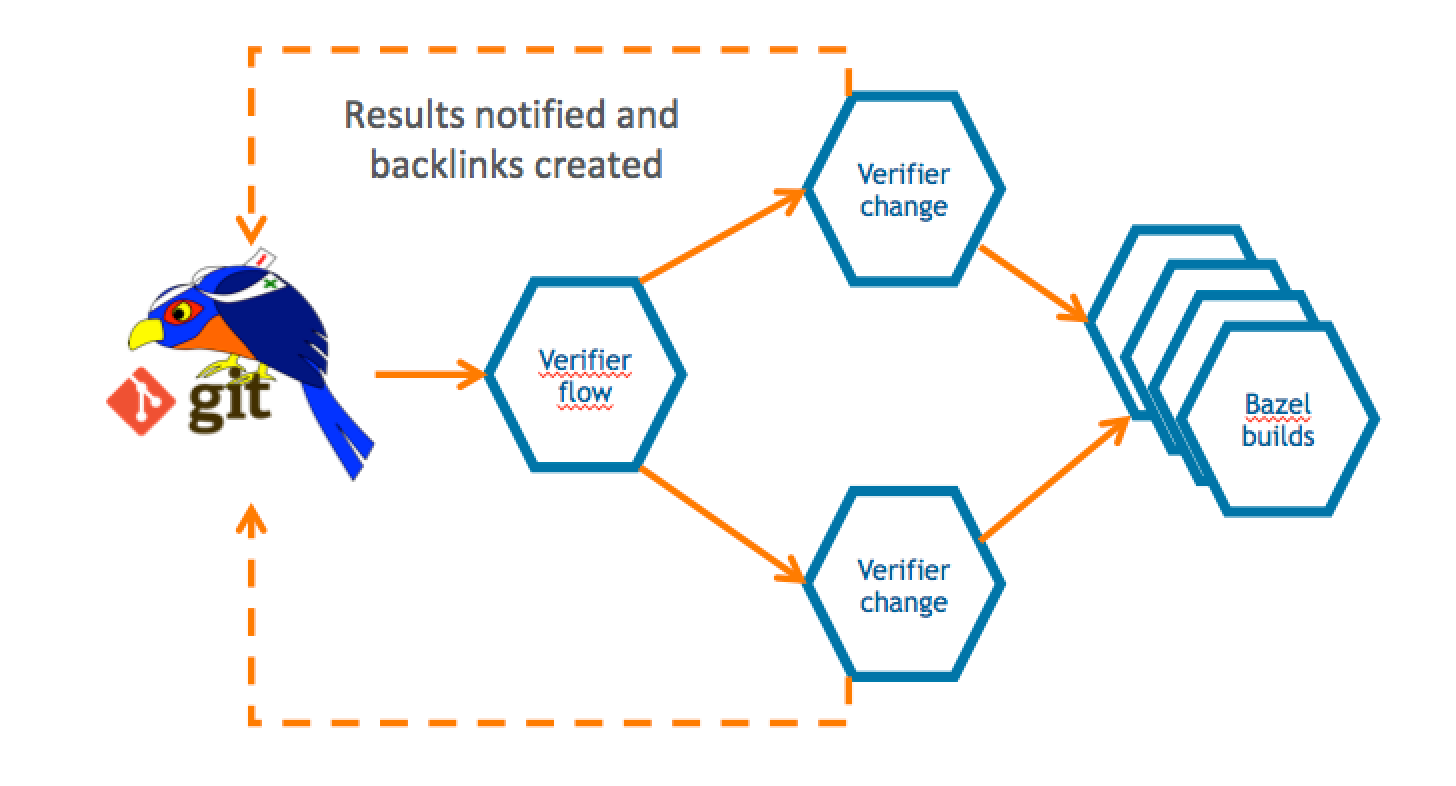
The way that our workflow works if very simple.
The verifier flow requests the list of changes that need verification by leveraging Gerrit query language which allows you to search through most of the fields of changes using a Lucene syntax. For each change that needs checking, a corresponding number of parallel jobs are triggered. This parallelism is potentially unlimited; the only limit is the number of machines that Google can assign to the Gerrit-CI, if he can allocate one hundred, we will be able to perform hundreds of parallel changes verifications.
That means that we can produce a lot of verification jobs at the same time. Bear in mind that for every change we do not trigger just one build: we have NoteDb vs. ReviewDb verification, PolyGerrit UX tests, Code-Style check there was a moment in time where a single change needed up to 6 parallel builds! That resulted into a lot of builds, which, as long as you’ve got enough horsepower in the slaves, it was working fine us.
We do not send feedback to Gerrit for every single build, but we rather have a “Gerrit Verifier Change” job coordinating the workflow and makes a decision accordingly. The criteria are the number of failed builds, the build retries for flaky builds. At the end of the process, all build results are collected and a unique coordinated feedback to send back to Gerrit as a unique verification message.
Too many logs for Jenkins lead to a 404 page.
This is all good, but as we said earlier: “Houston, we have a problem, we are too productive!”.
Here are some numbers of our productivity:
300 jobs
170,000 builds
4.8 millions of jar artifacts produced
1.7 billions of lines of logs
And of course, we want to send a link to the build logs we want to give context to the change failure or success. Unfortunately, happened to trace in Gerrit changes some nice links pointing to a quite unpleasant 404 page in Jenkins.
Why did it happen? We have a lot of contributors that generated lots of commit traffic and thus many build runs. There is a policy in Jenkins to remove “old” builds and thus happened that we lost build logs of active changes under review.
Q. (Han-Wen Nienhuys – Google) At Google internal build system we also this kind of numbers but of course with more zeros at the end, but actually we throw away our logs, and if you build binaries, they are very large.
In the beginning, we tried to keep more stuff online in Jenkins but people started saying “Luca, we have a much bigger problem now: gerrit-ci.gerritforge.com doesn’t respond anymore. When I open the Jenkins home page, it takes a very long time and eventually times out.”
That is caused by Jenkins design which is problematic when the number of logs increases considerably: everything is stored as a file and there is no efficient indexing for discovering the data on the filesystem. Additionally, if your company does not have a large infrastructure, your disk space is limited anyway. At GerritForge the Jenkins master has only 8TBytes of disk space, and we don’t have available a system with PetaBytes or more.
Keeping Jenkins logs forever
I made the Gerrit Contributors’ Community aware of the problem and I asked: do we like that? If you think about it, logs are not rubbish. Logs are of immense value, logs are like your money, and analyzing them, crunching and understanding them is our daily job. The timestamps in the logs are like precious diamonds because they tell you that you may have made a mistake in your code and some parts of your pipeline execution start taking a lot more time than before.
When you remove the “old” logs, you make much more difficult to investigate on a failed verification build: the link attached to the change verification message points to a page that returns a 404. That’s not a bug in Jenkins; it’s a feature of removing old logs and keeping the master instance fast and healthy. But actually, it is a real functionality gap because Jenkins doesn’t know yet how to manage logs archiving.
Then I asked the Community: “For how long you want your logs to be retained?” because I needed to raise a PO for a much bigger machine. “One day, one week, one month?” and the answer I got was “Forever!”
If you think about it carefully, the answer is correct. You may not need all those logs at the moment, but in a month’s time, you may need to crunch some data to extract features or metrics. Additionally, getting rid of all logs means generating broken links in my past reviews, which could be an audit requirement stored with Gerrit changes.
Sending Jenkins data to a Logstash appender
It was about time for me to think about a solution and here is a description of what I have done.
First of all, I needed to get more disk space from Google, but then how can I tell Jenkins to use an alternative disk storage mechanism for his logs?
I then started adding to the jobs a plugin called “Logstash” (https://wiki.jenkins.io/display/JENKINS/Logstash+Plugin) which is responsible for capturing and sending Jenkins data to a configured stream appender.
All the Gerrit CI jobs are managed through YAML files which are submitted through code-reviews, using the Jenkins Job Builder tool. However, showing the Logstash configuration on the Jenkins UI is much easier to show where the Logstash is playing a role in the Gerrit-verifier-change job configuration.
I have enabled a new feature to all the jobs to send all the log stream to the Logstash plugin. This works differently to what most of the people would do. Instead of just posting the log file into a stream of lines to ElasticSearch, this plugin gets the information directly from the JVM memory together with its metadata, the timestamp, the build parameters, the environment variables and send them to an endpoint, which could be anything. In this case, I have chosen to use RabbitMQ as stream appender. On RabbitMQ you can notice that I have created a queue for incoming Jenkins messages.
You may notice a lot of activity because every time that the Jenkins jobs produce something, a message is sent to RabbitMQ with the log and the attached meta-data. RabbitMQ is not used though as a storage system but acts only as a vehicle to transfer the information to a long-term storage system, which could be Google Cloud Storage.
The organization of files is straightforward: one file per hour. By looking at the file content, it is a very compressed JSON file that contains all the information I need: the build id, the result, the logs, the parameters.
Spark to the rescue
Problem solved? Can I tell all the Gerrit contributors that they have to look for a build result into a JSON file? Maybe this is not a very nice user experience.
I little more digging is needed to make the solution more transparent to the end user.
GerritForge as a company works and contributes to many BigData projects, including Apache Spark. Why don’t we build an elementary Spark transformation that consumes the input JSON files and materializes back the log into a readable format?
So we built a Spark job that is crunching this data and produces something very very similar to what Jenkins would render. However, we need to make sure to perform all those operations outside the Jenkins domain; otherwise, it would become very soon overloaded and thus unusable.
I have then created another directory that is not actually managed by Jenkins but gets populated by a Spark job. This parallel file structure has exactly the same organization of the build files generated by Jenkins builds.
Let’s have a look for instance at the oldest build that has been recorded by Jenkins: build #31639. For sure if I go to the build #31444, which is older than the #31638, Jenkins would give me a 404 because that job execution has been removed.
However, if I try now to navigate to the build log #31444, wow, I can see the full results as the build log was still accessible.
Additionally, as this log has been produced from the previous JSON file that contains all the meta-data, I can even render more information such as the time-stamps, which are not typically available in Jenkins unless you enable a specific plugin.
Moving forward, by leveraging the same input JSON file, we could do a lot more data crunching as well. It would be interesting for instance to draw a graph of the correlation between the Gerrit changes the build execution times at the different stages.
Uncovering the hidden value of your Jenkins logs
There is a lot more we can do with the JSON I’ve shown you before. It contains not just the log messages, but everything related to the build meta-data of the build and its execution metrics. That means if we go to this change #129553, the link that points to Jenkins logs is not broken anymore, even if it is not served by Jenkins but is backed by the Spark job results.
Starting to applying the same mechanism to all the Gerrit changes and redirecting them to the Google storage where all the files are going to be archived, any change in the Gerrit history will not contain broken links anymore and will be perfectly auditable.
That means that from now, whenever you are going to receive a Verified notification from Gerrit and you navigate to your change links, you are not landing anymore to a 404 page anymore.
Questions.
Q: What if I have a Jenkins instance and I want to do some of this but I don’t have infinite disk-space as Google. Is it is possible to implement?
A: With regards to disk space, you don’t have to go to Google or AWS. You can set up an HDFS filesystem yourself. All the cloud storage implementations available on the Cloud are mainly based on something very similar to HDFS which is an open standard and is available as OpenSource. That means you can store the information there and you do not necessarily need to keep it forever. In practical terms what you need to keep is the lifetime of a release of the software, or a few software iterations, maybe six months, 12 months. As the JSON files are organized on a time-series, it is going to be very easy to remove or archive all the data you do not need anymore. I have shown you how to store those files in JSON, but you can use even more optimised and compressed format such as Avro or Parquet, which may contain 10x times the information in a fraction of disk space. Additionally, when you process them, they can be even faster because they include data encoded in binary format. In a nutshell, the term “keep the logs forever” could be read as “keep for as much as you need: one week, one month, six months, …”. The problem with Jenkins is that for very busy servers like the Gerrit CI, you cannot keep even a single day of logs and when the people are coming the next day to check what’s wrong with a failed verification, would risk having a 404 error page.
Q: So if you do compression and decompression, that needs to happen server-side, so that is transparent to the browser?
A: Yes, that needs to happen on the Server, and there are a lot of ways for doing it, it could be even done on-the-fly, streaming and is pretty fast. There will be a talk tomorrow talking about the methodology to crunch large amounts of data and about the lambda architecture.
Q: Does it generate a RabbitMQ message for each log statement or a unique one at the end of the build?
A: Yes, and the reason is straightforward: If the build crashes or gets aborted for any reason, you do not want to lose your build logs. There was an implementation of Logstash for the Jenkins pipeline that was precisely collecting the logs all at the end of the build, but the design is wrong because if the builds get aborted you do not get feedback at all. Yes, it generates a message for every single line, and possibly RabbitMQ is not the correct implementation of it. But as soon as the Logstash plugin supports the Kafka transport, the performance issues related to the use of RabbitMQ for log streaming will be resolved.
Q: The Logstash plugin that you mentioned, has nothing to do with the “ElasticLogstash” implementation?
A: Yes, it is just unfortunate naming. Actually, the Jenkins Logstash plugin was possibly born before Elastic called his implementation ‘logstash’.
Q: You mentioned that you do Spark processing at some point, but it wasn’t part of your presentation.
A: Yes, it is not part of this presentation for reasons of time, but it is trivial.
Q: Question about the GerritForge CI: I have frequent problems of the test failing not because of my code, and I want to retrigger the tests without having to add a commit to retrigger the CI. Is there a way to retrigger the CI build?
A: Yes, it can be done by going to the Gerrit-verifier-change URL, you click on “Build with Parameters” and enter your change number. You can in this way retrigger any build without having to commit anything.
Q: And if that pass that would assign the Verifier approval to the change?
A: Yes. I would like to add a Button to Gerrit-Review to avoid people to navigate to a different URL.
Q: We are relatively heavy users of Gerrit topics because we have changes that are across multiple repositories. We have a very similar job to this one but we can either put a single or multiple change IDs or a topic name, and it will work out whether it is a consistent declaration. Another thing that you can comment on, you mentioned that the verifier job which runs some independent verifications and then feeds the result as one result to Gerrit, that sounds like something we could use. What is that build using?
A: Tomorrow there will be a presentation of a brand-new integration between Gerrit and Jenkins. The rationale for writing a new integration lies on the thinking that “maybe the Gerrit project is not the only one that needs a bit more from Jenkins.” So why not creating a Jenkins plugin that takes the most of the experience we’ve made in integrating Gerrit with Jenkins for the Gerrit Code Review project and makes it available to the rest of the world? There will a plugin to implement that workflow.
Starting from this week, we are going to share one video per week of the amazing talks that were presented at the Gerrit User Summit 2017 in London.
In addition to the YouTube recording, we are during the extraction of the text and publishing it together with the relevant pictures taken from the presenter’s slides, so that people can start digesting the content at small bites.
This week talk is Patrick Hiesel’s presentation on how Gerrit multi-tenant and multi-master setup has been implemented in Google.
Gerrit@Google – Patrick Hiesel, Google
My name is Patrick, and I am going to talk about the setup of Gerrit we are running at Google. I wanted to take you on a journey starting with Gerrit that you all know and making it the system we run at Google, step-by-step; and at the end will have a multi-master and multi-tenant system.
Multi-what?
Multi-tenant is the ability to serve multiple hosts from the same single Java process. Imagine like the same JVM task serving gerrit-review.googlesource.com and gerrit-chromium.googlesource.com.
Multi-master is the ability to have multiple Gerrit servers all over the world. You can contact any one of them for reads and writes.
Most systems have read replicas, which is straightforward, but write replicas is where the juicy meat is.
Multi-tenant
We have gerrit-review.googlesource.com, based on OpenSource Gerrit that you can download right now and have it running hopefully under ten minutes. That is core-Gerrit, and it depends on three things:
JGit: for all the Git stuff
Multiple indexes for the accounts, changes, and other stuff
Caches
All these three components are based on the filesystem in one way or the other.
Now you have a friend that is accessing go-review.googlesource.com, what are you going to do?
The most natural solution is to start another Gerrit instance for it. You can have all of them on one machine, you can give them different ports, very easy, and in the end, they’ll be all based on the filesystem.
All those Gerrit instances do not need to talk to each other; they can just be separate instances operating on separate ports. This is not a multi-tenant system, but only different Gerrit instances on the same host.
You can add another layer on top of it: a servlet engine which receives all the traffic, check which host the traffic is for, and just delegate to the individual host.
To take one step further, have that selection filter doing that for you. Gerrit has a daemon that runs all the functionalities. You can integrate that daemon into the incoming servlet filter. When you can get a request for go-review.googlesource.com and I do not have where to allocate it, you can just launch it, instantiate all the objects and then run the traffic from there. Also, unload instances would work in the same way.
The Gerrit server engine and the selection filter can run in a single JVM.
How Gerrit can conquer the world
So you have a master here in Europe, and you have got one friend on the west coast in the US. He says: “Oh your Gerrit is so slow I have no idea why and I wish I could move to GitHub.” You say: “Hold on, I can do better than that!” and so you put a new master for the person on West coast.
So the key to that is the replication and comes in two sets:
Objects that you have to replicate related to all the Git data. JGit is putting objects into the disk, and these are the data you need to replicate correctly and fast.
Other stuff that should replicate and fast to provide a pleasant user experience but it really can be best-effort. That is the indexes and the caches.
If it is okay for your master having a 200/600 msec additional latency, then do not replicate the caches. You can have a cold cache in Singapore or the US, and you can reread them without problems.
For the index, replication can be best-effort, but you should make an effort to replicate them. It is still nonetheless a mandatory requirement. One way to achieve that is to use ElasticSearch, but other index implementations that give indexes replication can be used as well.
Multi-tenant and Multi-master together
We talked about a multi-tenant system and then replicate them globally, so we have now a multi-tenant and multi-master system, actually pretty close to what we run at Google.
That is the stack that we run in total. We have a selection filter and two other filters to decide what the traffic is directed. We are also based on JGit, no magic there, we have index and caches we replicate, all our systems are based on filesystem and BigTable.
Some “magic” happens at the Git layer at Google because that is where all the majority consensus across all the cells. When you are pushing anything that is Git and, with NoteDb, anything that is a review is in the repository as well, the system tries to reach the majority of the cells and write the objects to them. When that is acknowledged, you get a green light on the push.
Majority consensus also means that you have it only in so many cells, but don’t have it on all the cells all the times. Some of the replication is happening in the long tail, by replication events eventually get acknowledged by the cells, and then they get written to all the masters.
Our indexes and caches are also replicated, but some of them are just in-memory and a component that gets replicated on top of BigTable.
Redundancy everywhere.
We run five data-centers across three continents (Americas, Europe, Asia-Pacific), with precisely the stack we just saw which gives us a good latency for most of our users worldwide.
Let’s talk about load balancing. We have a system that is multi-master and multi-tenant, and any of the tasks can serve any requests, but just because it can, doesn’t mean that it should.
Maybe it has in cold memory caches, or it is in Singapore, and you are in the US; so the question is what if the biggest machine is not big enough and we want to optimize it?
The idea is that we want to reduce latency that comes out of cold caches and minimize the time the site takes to load.
So you have a request for gerrit-review.googlesource.com, and your instance has a cold cache, and you need to read from disk to memory to serve the request.
You have a fleet of 300 tasks available but you want to serve gerrit-review.googlesource.com from only just five of them. If you serve 300 requests from 300 tasks in a round-robin manner, you pay the latency to load data from disk to memory for every single request. And the second motivation is that you want to distribute the load.
We want a system that can dynamically scale with changing load patterns. We want a system that can optimise the caches, to send a request for a site/repo to the few number of servers and tasks based on two conditions:
serve from one machine as long as it fits on it
server from more machines if you really have to
Level-1 load balancer
In the stack at Google, you saw two load balancing levels. What you see down in the picture is the Gerrit tasks, that contains all the software layers we talked about. We have a user that triggers JSON calls from the browser, with PolyGerrit. The first thing that the JSON request is hitting is the L1 load balancer. The primary routing of your request is by geographic proximity. We have five datacentres at Google; the L1 load balancer picks the one with the lowest latency. When the request goes into the data-center, we have another load balancer which is the one I’ll talk about more, because this is the one where the Gerrit specifics happen.
One thing that L1 is doing as well is managing the spillover of traffic. When a datacentre says “I can handle up to 100 QPS” the L1 load balancer starts redirecting traffic to other datacentres should that threshold be reached.
Level 2 load balancer
Let’s dive into L2 load balancer, we want to know how much traffic we are getting into each Gerrit task, and we want to know in the load balancer where the single request should go, and we want to know that fast!
We added three new components to the architecture:
An element to redirect tasks and provide functionality and can report the load we are handling right now. When I mean load it can be anything: QPS (Queries Per Second), metrics, we just want to know from the tasks: what is your current load? We have a system called slicer, which I am going to talk about in a second and it’s added there in the picture.
A second component we are adding to the load balancer, with a query interface that responds to the following question: “we have a request for gerrit-googlesource.com, where should it go?”. All of that should be done in memory and should be regularly updated with the new elements in the background so that we don’t add another component of latency by having another RPC.
A third part is coordinating everything and is called the assigner, and it takes all the load metrics that we reported generates new assignments and gives them to the query interface.
Introducing the slicer
We have a system that is called slicer. There is a very nice paper that I can recommend, published last fall, that talks about that. It is a load balancer that works on custom keys and can do automatic re-sharding based on new traffic patterns. When your nodes receive more traffic, the slicer will automatically distribute the load or re-shard the whole system. That is a suitable method for local sharding that happens within the data center; we do not use it for inter-datacentre because that is all done via geographic proximity.
The system works with 64-bit keys and gives you a lot of combinations. You can slice the keyspace, for instance, in 400 slices. That gives you 400 ranges, and you can take any of them and assign to one or more tasks. The hostname is my key for instance, and then you hash it, and you end up in the first slice that gets assigned to a single task with an index zero.
What can we do if the load changes? Let’s say that you have key zero that gets assigned to the first range and then the traffic changes. We have two options.
The first option is to assign more tasks, let’s say task 6, and then you round-robin between task 0 and task 6.
The second option is splitting into 600 or 800 slides to get a better grip on each of the keys.
We can also do that, and then we factor our the load for gerrit-review.googlesource.com and go-review.googlesource.com, and we put them into different hosts.
We do that for Gerrit, and one of the things we want for Gerrit is when we have to split per-host traffic with the affinity on the repository. Caches are based on the project, and because gerrit-android.googlesource.com is a massive host served from a lot of tasks, we don’t want all these tasks just to serve all general traffic for android. We want tasks serving android/project1 from here and android/project2 from there so that we optimise the second layer of caches.
What we do is to mangle these keys together based on both host and project. Before, all these chromium keyspace was served from a single host; when the load increases we just split the keys into Chromium source and the rest of metadata. This is the graph that we obtained after we implemented the load balancer. The load we have on each of the tasks in a single data center is represented by a line with a different color. What you can see is that are all nicely aligned, so that each task is serving precisely the same amount of traffic which is what you want.
What if one project is 100 times the size of the others and we are optimizing on queries per second? The system will just burn resources fast. We had that situation in May, we saw the graphs, and we said “all good, looks nice”; however, people were sending e-mails and raising bugs wondering if the system were serving any traffic at all or if it were down completely.
It turned out that Android had a lot of large repositories, regarding the number of references, and the objects. We were just optimizing the queries per second, but some of the tasks were doing just CPU intensive work, where others were happy with it. Some of them were burning CPU in flames, and others were fine.
So we moved out of the per-request affinity, and we modified the per-repository sharding to optimise all of this.
Warm vs. Cold Cache
There is an extra in the system that is pre-warming caches. What the load balancer can do for you is to tell you that traffic is changing and I need to reconsider how to split the load on the system. For each of the tasks is going to tell “I’m going to give you traffic for gerrit-review.googlesource.com” with a notice of 30 seconds. That time you can use for pre-warm caches.
That is especially nice if you restart your tasks because all the associated in-memory cache gets flushed. The load balancer tells you “oh, this is the list of the tasks I need” and then you can get them all and pre-warm their caches. This graph shows the impact of the cache warmer on our system, on the 99.9% requests latency, really on the long tail of requests latency. That looks nice because we brought the latency down by a third.
What is a task start dying during peak traffic? Imagine that the load balancer is saying “You’re going to handle this” and two seconds later says “I have to reconsider, you’re going to handle that instead”. Again you’re going to watch your system burning on fire, because you’re serving peak traffic and then you’re running close to 100% CPU. That situation causes the load balancer loading and unloading tasks all the time, which is inconvenient. The way we work around this is to make this cache warming a best-effort activity. You can do it if you’re below 50% CPU when you have time to do fancy things, but when you receive peak traffic, you just handle peak traffic without any optimisation made.
Multi-master and multi-tenant outside of Google
The question is: how do we do that in a non-Google setup?
There are plenty of options.
With the new Gerrit release in 2.15, we introduced to a new URL scheme, which includes the project name in the URL. Previously you had gerrit-review.googlesource.com/c/NNN and there was no way to directly know which project this is for and no way to do that load balancing that we just saw.
What we did in 2.15 is just add the project before that, so that extraction for both host and project can be made in a simpler way. You could do the same even before v2.15 but you needed a secondary index lookup, which most opensource load-balancers such as HAProxy or NGINX did not support. And of course, there are lots of products like Google Cloud load balancer, and others that you can use to achieve the same thing.
Wrap-up
We went through a journey where we took OpenSource Gerrit, we added sites selection and got a multi-tenant Gerrit.
Then we took this multi-tenant Gerrit, added replication and obtained multi-master Gerrit.
And then we took that with load balancing and lots of failures and lots of fixes, and we got pretty much the Gerrit that we run at Google, which brings me to the end of this talk 🙂
Q&A
Q: How strategic is Gerrit@Google? Do you have any other code-review systems? If yes, how is used Gerrit vs. the others?
We have another code-review system for internal use only, and Gerrit is used whenever we are doing OpenSource stuff, so for GoLang, Chromium, Android, Gerrit, and whenever the Google Team wants to collaborate with other OpenSource users, or in general with users that are not sitting at Google.
Historically the source at Google was developed in Perforce, and we ported from that to a home-based system called Piper. Around that, we have a tooling ecosystem which is internal. In parallel to that, Google started to do a lot of projects that have nothing to do with the internal search engine and available outside. What we see is that a lot of projects started at Google from scratch were thinking about “what system should we use?”. Many people said: “well, we’re going just to use Git because that’s what we know and we like, ” and when they needed code-review for Git they ended up with us. Gerrit and Git are very popular inside Google.
Q. You have two levels of load balancer. The first one is the location, and the second one is to decide what to do inside the data-center. What about if a location is off? Maybe is not fully off-line but has big problems, or has a very low-percentage of consensus, and some of the locations have not the “latest and greatest” of the repo. Possibly a location that should be “inconvenient for me” actually has the data I want.
You’re talking about replication layer where you have the objects in one location but not in the other. Our replication latency is in the order of seconds, but it may happen that one location is just really slow in getting the objects. That happens from time to time, and we have metrics that says what the replication lag is accounted for. When it exceeds a threshold we just shut the data-center off, which means cut-off the traffic, the data-center will not receive user-traffic anymore but it will still be able to get the replication done, and when the decrease the objects we need to replicate we can send the traffic again.
Cutting off the traffic is happing at the L1 load balancer where we said “don’t send anything there”.
Q. Do all the tasks have the same setup? Or do have a sort of micro-service architecture inside where some of the tasks are more dedicated to this type of operations and other for another type. Serving data from memory in one thing, but calculating diff change is a different type of task.
Not in general. All of our tasks are the same, except for checking access control permissions. We do not go through the whole Gerrit stack but we have only this little task that knows how the project config works and is going to tell us yes or no.
With only seven days to go, the Gerrit User Summit is approaching fast! There has been a lot of discussion on the Gerrit usability on a recent discussion thread on the GoLang project. More and more the focus of OpenSource communities is the ease of adoption and contribution, after of course the solidity and efficiency of the review process. A usable interface, clear and self-explanatory even for newbies, could contribute to the success of a project.
PolyGerrit, a fresh start from the Chromium project
In July, the entire Chromium project moved from Rietveld to PolyGerrit: this event has brought a lot more users to the Gerrit platform and triggered a creative and open debate on the future of Gerrit UX. Chromium’s unique workflow has been the driver of lots of improvements, some of which will be landing in Gerrit 2.15.
There is a new visual design for the change view to present. You may have already seen some elements of this design rolling out to googlesource.com. Arnab Banerjee from Google will take us through the complete design and show us where it’s going in the coming weeks.
A PolyGerrit booth has been set up at the conference to allow anyone to experiment the new UX and go through some research trials to provide meaningful feedback for the evolution of the user interface.
Only ten seats left, it’s never too late
The Gerrit User Summit 2017 is almost entirely booked: HURRY UP AND REGISTER TODAY so that you can see and be part of the evolution of the Gerrit UX. Your user-journey and requirements can be part of the next version of Gerrit, be part of the change and part of the Community.