Jenkins and Gerrit are the most critical components of the DevOps Pipeline because of their focus on people (the developers), their code and collaboration (the code review) their builds and tests (the Jenkinsfile pipeline) that produce the value stream to the end user.
DevOps is all about iteration and fast feedback. That can be achieved by automating the build and verification of the code changes into a target environment, by allowing all the stakeholder to have early access to what the feature will look like and validating the results with speed and quality at the same time.
Every development team wants to make the cycle time smaller and spend less time in tedious work by automating it as much as possible. That trend has created a new explosion of fully automated processes called “Bots” that are more and more responsible for performing those tasks that developers are not interested in doing manually over and over again.
As a result, developers are doing more creative and design work, are more motivated and productive, can address technical debt a lot sooner and allow the business to go faster in more innovative directions.
As more and more companies are adopting DevOps, it becomes more important to be better and faster than your competitors. The most effective way to accelerate is to extract your data, understand where your bottlenecks are, experiment changes and measure progress.
Humans vs. Bots
The Gerrit Code Review project is fully based on an automated DevOps pipeline using Jenkins. We collect the data produced during the development and testing of the platform and extract metrics and graphs around it constantly https://analytics.gerrithub.io thanks to the OpenSource solution Gerrit DevOps Analytics (aka GDA).
By looking at the protocol and code statistics, we founded out that bots are much more hard worker than humans on GerritHub.io, which hosts, apart from the Gerrit Code Review mirrored projects, also many other popular OpenSource.
That should not come as a surprise if you think of how many activities could potentially happen whenever a PatchSet is submitted in Gerrit: style checking, static code analysis, unit and integration testing, etc.
We also noticed that most of the activities of the bots are over SSH. We started to analyze what the Bots are doing and see what the impact is on our service and possibly see if there are any improvements we can do.
Build integration, the wrong way
GerritHub has an active site with multiple nodes serving read/write traffic and a disaster recovery site ready to take over whenever the active one has any problem.
Whenever we roll out a new version of Gerrit, using the so-called ping-pong technique, we swap the roles of the two sites (see here for more details). Within the same site, also, the traffic can jump from one to the other in the same cluster using active failover, based on health, load and availability. The issue is that we end up in a situation like the following:
The “old” instance still served SSH traffic after the switch. We noticed we had loads of long-lived SSH connections. These are mostly integration tools keeping SSH connections open listening to Gerrit events.
Long-lived SSH connections have several issues:
SSH traffic doesn’t allow smart routing. Hence we end up with HTTP traffic going on the currently active node and most of the SSH one still on the old one
There is no resource pooling since the connections are not released
There is the potential loss of events when restarting the connections
That impacts the overall stability of the software delivery lifecycle, extending the feedback loop and slowing your DevOps pipeline down.
Then we started to drill down into the stateful connections to understand why they exist, where are they coming from and, most importantly, which part of the pipeline they belong to.
Jenkins Integration use-case
The Gerrit Trigger plugin for Jenkins is one of the integration tools that has historically been suffering from those problems, and unfortunately, the initial tight integration has become over the years less effective, slow and complex to use.
There are mainly two options to integrate Jenkins with Gerrit:
We use both of them with the Gerrit Code Review project, and we have put together a summary of how they compare to each other:
Gerrit Trigger Plugin
Gerrit Code review Plugin
Notes
Trigger mechanism
Stateful
Jenkins listens for Gerrit events stream
Stateless
Gerrit webhooks notify events to Jenkins
Stateful stream events are consuming resources on both Jenkins and Gerrit
Transport Protocol
SSH session on a long-lived stream events connection
HTTP calls for each individual stream event
– SSH cannot be load-balanced
– SSH connections cannot be pooled or reused
Setup Complexity
Hard: requires a node-level and project-level configuration.
No native Jenkinsfile pipeline integration
Easy: no special knowledge required.
Integrates natively with Jenkinsfile and multi-branch pipeline
Configuring the Gerrit Trigger Plugin is more error-prone because requires a lot of parameters and settings.
Systems dependencies
Tightly Coupled with Gerrit versions and plugins.
Uses Gerrit as a generic Git server, loosely coupled.
Upgrade of Gerrit might break the Gerrit Trigger Plugin integration.
Gerrit knowledge
Admin: You need to know a lot of Gerrit-specific settings to integrate with Jenkins.
User. You only need to know Gerrit clone URL and credentials.
The Gerrit Trigger plugin requires special user and permissions to listen to Gerrit stream events.
Fault tolerance to Jenkins restart
Missed events: unless you install a server-side DB to capture and replay the events.
Transparent: all events are sent as soon as Jenkins is back.
Gerrit webhook automatically tracks and retries events transparently.
Tolerance to Gerrit rolling restart
Events stuck: Gerrit events are stuck until the connection is reset.
Transparent: any of the Gerrit nodes active continue to send events.
Gerrit trigger plugin is forced to terminate stream with a watchdog, but will still miss events.
Differentiate actions per stage
No flexibility to tailor the Gerrit labels to each stage of the Jenkinsfile pipeline.
Full availability to Gerrit labels and comments in the Jenkinsfile pipeline
Multi-branch support
Custom: you need to use the Gerrit Trigger Plugin environment variables to checkout the right branch.
Native: integrates with the multi-branch projects and Jenkinsfile pipelines, without having to setup anything special.
Gerrit and Jenkins friends again
After so many years of adoption, evolution and also struggles of using them together, finally Gerrit Code Review has the first-class integration with Jenkins, liberating the Development Team from the tedious configuration and BAU management of triggering a build from a change under review.
Jenkins users truly love using Gerrit and the other way around, friends and productive together, again.
Conclusion
Thanks to Gerrit DevOps Analytics (GDA) we managed to find one of the bottlenecks of the Gerrit DevOps Pipeline and making changes to make it faster, more effective and reliable than ever before.
In this case, by just picking the right Jenkins integration plugin, your Gerrit Code Review Master Server would run faster, with less resource utilization. Your Jenkins pipeline is going to be simpler and more reliable with the validation of each change under review, without delays or hiccups.
The Gerrit Code Review plugin for Jenkins is definitively the first-class integration to Gerrit. Give it a try yourself, you won’t believe how easy it is to set up.
Luca Milanesio, Gerrit Code Review Maintainer and Release Manager, presented the current status of the support for multi-master and multi-site setups with the standard OpenSource Components, developed by GerritForge and the Gerrit Code Review Community.
Introduction
The focus of this talk is sharing with you one experience that we did with the Gerrit server that we maintained, GerritHub.
First of all, I’m just going to tell you how we went through the journey from a single master-slave installation back in 2013 to a fully multi-site setup across two continents.
The evolution of GerritHub to multi-site
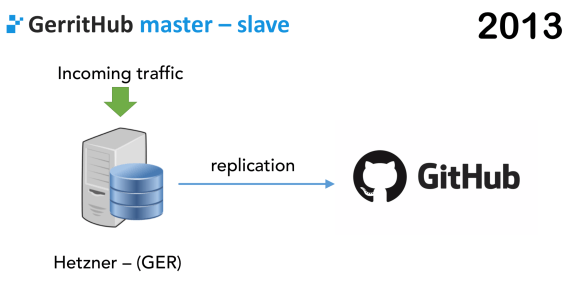
GerritHub was born in November 2013. The idea was straightforward. It was just an idea on how to take a single Gerrit server and put the replication plug-in to push to GitHub.
To implement a good and scalable and reliable architecture, you don’t need to design everything up front. At the beginning of your journey, you don’t know who your users are, how many repos are going to create, what the traffic looks like, what the latency looks like: you know nothing.
You need to start small, and we did back in 2013, with a single Gerrit master located in Germany, because we had no idea of where the users would have come from.
Would the people in Europe like it, or rather the people in the U.S. like it, or again the people in China like it? We did not know. So we started with one in Germany.
Because we wanted to make a self-service system what we did was very simple: a simple plugin called, “The GitHub plug-in”. That was just a wizard to add an entry in the replication config.
You have Gerrit incoming traffic, then you configure replication, plugin and eventually push to GitHub. The only complicated part here is that if you do it as a Gerrit administrator you have to define these remotes in the replication.config but you can express it in an optimized way. On a self-service system, you’ve got 1000s of people then will create 1000s remotes automatically. Luckily, the replication plugin works very well and was able to cope with it very well.
Moving to Canada
Then we evolved. The reason why we changed is that people started saying ‘Listen, GerritHub is cool, I can use it, works well in the morning. Why in the afternoon is so slow?“. Uh oh.
We needed to do some data mining to see precisely who was using it, where they were coming from, and what operations they were doing. Then we realized that we had chosen the wrong location because we decided that we wanted to put the Gerrit master in Germany, but the majority of people are coming from the USA.
Depending on how the backbone between the Atlantic Ocean was performing, GerritHub could be faster or slower. One of the complaints that they were saying is that in the morning, GitHub was slower than GerritHub, but in the afternoon it was exactly the opposite.
We were doing some performance tuning and analyzing the traffic, and even when people were saying that it’s very slow, actually GerritHub was a lot faster than GitHub in terms of throughput. The problem was the number of hops between the end user and GerritHub.
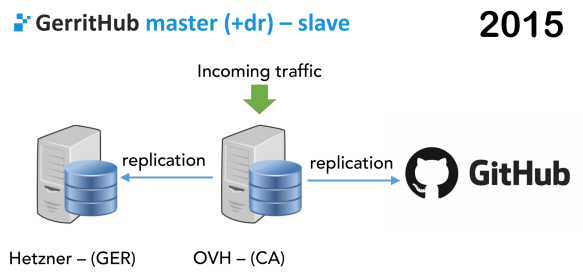
We decided that we needed to move from Germany to the other side of the Atlantic Ocean. We could have done to move the service to the USA but we decided to go with Canada because the latency was precisely the same as hosting in the USA but less expensive.
What we could have done is just to move the Master from Germany to the other side of the Atlantic Ocean, but because, from the beginning, we wanted to give a service that is always available, we decided to keep both zones.
We didn’t want to have any downtime, even in this migration. We wanted, definitely, to do one step at a time. No changes in releases, no changes in configurations, only moving stuff around. Whenever you change something, even if it’s a small release change, you change the function, and that has to be properly communicated.
If we were changing data center and version, when something goes wrong, you would have the doubt of what it is. Would it be the new version that is slower or the new data center that is slower? You don’t know. If you change one thing at a time, it must be that thing that wasn’t working.
We did the migration in two steps.
Step-1: The Gerrit master in Germany, still the replication to GitHub, and the new master in Canada was just one extra replication end.
The traffic was still coming on this side of the master, but it was replicated to both Canada and the other GitHub. Then, when that was stable, so we were doing all the testing, the other master was used as it was at Gerrit slave, but was not a slave, all the nodes were master, with just a different role.
Step-2: Flip the switch the Gerrit master is in Canada. When replication was online and everything was aligned, we have put a small read-only plug on the German side, which was making the whole node read-only for a few minutes, to give time to the last replication queue to drain.When the replication queue was drained, we flipped the switch, when it was going to the new master it was already read/write.
The people didn’t change their domain, didn’t notice any difference, apart from the much-improved performance. The feedback was like “Oh my, what have you done to GerritHub since yesterday? It’s so much faster. It has been never so fast before.‘
Because it was the same version, and we were testing in parallel for quite some time, nobody had a single disruption.
Zero-downtime migration leveraging multi-site
But that was not enough, because we wanted to keep Gerrit always up and running and always up to date with the latest and greatest version. Gerrit is typically released twice a year; however, the code-base is stable in every single commit.
However, we were still forced to do the ping pong between the two data centers when we were doing our roll out. It means that every time that an upgrade was done, users had a few minutes of read-only state. That was not good enough, because we wanted to release more frequently.
When you upgrade Gerrit within the same release, let’s say between 2.15.4 and 2.15.5, the process is really straight forward, because you just replace the .war, restart Gerrit, done.
However, If you don’t have at least two nodes on either side, you need to ping pong between the two different data centers, then apply the read-only window, which isn’t great.
We started with a second server on the central node so each node can deal with the entire traffic of GerritHub. We were not concerned about the German side, because we were just using it as disaster recovery.
Going multi-site: issues
We started doubling the Canadian side with one extra server. Of course, if you do that with version v2.14 which problem do you have?
Sessions. So, how do you share the sessions? If you login into one Gerrit server, you create one session, then you go to the other and you don’t have have a session anymore.
Caches. That is easier to resolve, you just put the TTL of the cache to a very low value, put some stickiness, you may sort this out. However, cache consistency is another problem and needs to be sorted.
Indexes are the very painful one, because, at that time there was no support for ElasticSearch. Now things are different, but back in 2017, it wasn’t there.
What happens is that every single node has its own index. If an index entry is stale, it’s not right until someone is going to re-index.
The guys from Ericsson were developing a high availability plugin. We said instead of reinventing the wheel, why don’t we use a high availability plugin? We started rolling it out to GerritHub and actually, the configuration is more complex and looks like this one.
So, imagine you’ve got in Canada you’ve got two different masters, still only one in Germany. They align the consistency of the Lucene index and the cache through the HA plugin and they still use the replication plugin.
How do you share the repository between the two? You need to have a shared file system. We use what exactly the same used by Ericsson, NFS.
Then, for exposing the service we needed HAProxy, not just one but at least two. If you put one HAProxy, you’re not HA anymore, because if that HA proxy dies, your service goes down. So, you have two HAProxy, they must have a cross configuration’s, it means that both of them, they can redirect traffic to one master or the second master, it’s not one primary and the second backup: they have exactly the same role. They do exactly the same thing, they contain exactly the same code, they’ve got exactly the same cache, exactly the same index. They’re both running at the same time. They’re both accepting traffic.
This is something similar to what Martin Fick (Qualcomm) did, I believe, last year, with the only difference that they did not use HAProxy but only DNS round-robin.
Adoption of the high-availability plugin
Based on the experience of running this configuration on GerritHub, we started contributing a lot of fixes to the high-availability plugin.
A lot of people are asking “Oh, GerritHub is amazing. Can you sell me GerritHub?”. I reply with “What do you mean exactly?”
GerritHub is just a domain name that I own, with Gerrit 2.15, plus a bunch of plugins: replication plugin, GitHub plugin, the high-availability plugin (we use a fork), the web session flat file and a bunch of scripts to implement the health check.
If you guys want to do your own, the same configuration, you don’t need to buy any commercial product. We don’t sell commercial products. We just put the ideas into the OpenSource community to make it happen. Then if you need Enterprise Support, we can help you implement it.
The need for a Gerrit disaster-recovery site
Then we needed to do something more because we had one problem. OVH had historically been very reliable, but, of course, shit happens sometimes.
It happened one day that OVH network backbone was down for a few hours.
That means that any server that was on that Data-Center was absolutely unreachable. You couldn’t even connect to them, you couldn’t even check their status, zero. We turned the traffic to the disaster recovery side, but then we faced a different challenge because we had only one master.
It means that if something happens to that master, I don’t know, a peak, or whatever, is becoming a little bit unhealthy, then we are going to have an outage. We didn’t want to risk to have an outage in that situation.
Your disaster recovery side is never really safe until you are going to need and use it. Then use it all the times, on a regular basis. This is what we ended up to implement.
We have now two different data centers, managed by two different cloud providers. One is still OVH with Canada, and the other is Hetzner in Germany. We still have the same configuration, HA plugin over a shared NFS, so this one is completely replicated into the disaster recovery site, and we are using the disaster recovery continuously to make sure that is always healthy and aligned.
Leverage Gerrit-DR site for Analytics
Because we didn’t want to serve actual user traffic on the disaster recovery site, because of the synchronization lag between the two sides, we ended up using for all the data mining activities. There is a lot of things that we do on data, trying to understand how our system performs. There is a universe of data that typically either never looked at or you don’t really extract and process in the right way.
Have you ever noticed how much data Gerrit generates under the logs directory? A tremendous amount of data and that data tells you exactly the stories that you want to know. It tells you exactly how Gerrit works today, what I need to do to makes sure that Gerrit will work tomorrow, how functions are performing for the end users, if something has blown up, it’s all there.
We started really long ago to work on that DevOps Analytics space, and we started providing that metrics and insights data for the Gerrit Code Review project itself and reporting it back to the Gerrit Code Review project through the service https://analytics.gerrithub.io.
Therefore we started using the disaster recovery site for analytics traffic because if I do an extraction and processing of my data on my logging, on my activities, is there really a need for an analysis of the visit of 10 seconds ago or not? A small time lag on data doesn’t make any difference from an analytics’s perspective.
We were running Gerrit v2.15 here, so the HA plugin needed to be radically different from the one that it is today. We are still massively on the HA plugin fork, but all the changes have been pushed for review on the high availability.
However, the solution was still not good enough because there were still some problems. The problem is that the HA plugin within the same data center relies on the shared file system. We knew within the same data center that was not a problem. But, what about creating an NFS across data-centers in different continents? It would never work effectively because of the latency limitations.
We then started with a low tech solution: rely on the replication plugin for the Git data in the repository. Then every 30 minutes, there was a cronjob that was checking the consistency between the two and then does a delta re-index between the different sites.
Back in Gerrit v2.14, I needed to do as well a database export and import, because contained the reviews.
But, there was also the timing problem: in case of a disaster occurred, people will have to wait for half an hour to get the data after re-index.
They would have not lost anything because the index can be recreated at any time, but the user experience was not ideal. And also, you’ve got the DNS related issues for going from one zone to the other.
Sharding Gerrit across sites
First of all, we want to leverage the sharding based on the repository, available from Gerrit 2.15, which include the project name in each page or REST-API URLs. That allows achieving basic sharding across different nodes even with a simple OpenSource HAProxy or other Workload Balancer, without having the magic of the Google intelligent Gerrit/Git proxy. Bear in mind this is not pure sharding, because all the nodes keep on having all the repositories available on every node. HAProxy is going to be clever and based on the project name and action, will use the most appropriate backend for the reads and writes operation. In that way, we are making sure that you never push on the same repository on the same branch from two different nodes concurrently.
How magic works? The replication plugin takes care of synching the nodes. Historically with master-slave, the synchronization was unidirectional. With multi-site instead, all masters are replicating to each other. It means that the first master will replicate to the second and the other way around. Thanks to the new URL scheme, Google made our lives so much easier.
Introducing the multi-site plugin
We have already started writing a brand-new plugin called multi-site. Yes, it has a different name, because the direction that it’s taking is completely different in terms of decisions compared to the high-availability plugin, which required having a shared file system. Secondly, the HTTP synchronous communication with the other site was not feasible anymore. What happens if, for instance, a remote Site in India is not reachable for 50 seconds? I still want things events and data to be put into a persistent queue to be eventually sent through the remote site.
For the multi-site broker implementation, were have decided to start with Kafka, because there is already an implementation of the stream events it in Gerrit as a plugin. The multi-site plugin, however, won’t be limited to Kafka but could be extended to support other popular brokers such as NATS.
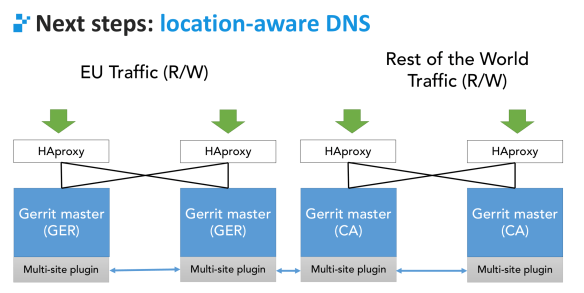
We will go to the location-aware DNS because we want the users to access the HAProxy that is closer to him. If I am living in Germany maybe it makes sense for me to use only the European servers, but definitely not the servers in California.
You will go by default to a “location-aware” site that is closer to you. However, depending on what you do, you could still be laster on redirected to another server across zones.
For example, if I want to fetch data, I can still fetch everything on my local site. But, if I want to push data, the operation can either be executed locally or forwarded to the remote site, if the target repository has been sharded remotely.
The advantage is the location-awareness and data-locality. The majority of data transfer will happen with my local site because, at the end of the day, the major complaints of people using Gerrit with remote masters is a sluggish GUI.
If you have Gerrit master/slave, for instance, a Gerrit master in San Francisco and your Gerrit slaves in India, you have the problem that everyone from India will still have to access a remote GUI from the server in San Francisco, and thus would experience a very slow GUI.
Even if only 10 percent of your traffic is a write operation, you would suffer from all the performance penalties of using a remote server in San Francisco. However, if I have an intelligent HAProxy, with also an intelligent logic in Gerrit that understands where the traffic needs to go to, I can always talk to my local server is in my zone. Then, depending on what I do, I can use my local server or a remote server. This happens behind the scenes and is completely transparent to the user.
Q&A
Q I just wanted to ask if you’re ignoring SSH?
SSH is a problem in this architecture, right, because HAProxy supports SSH, but has a big problem.
Q: You don’t know what projects, you don’t have any idea of the operation, whether it’s read or write.
Exactly. HAProxy works at transport levels, so it means that it knows that flow of encrypted data going back and forth to the Gerrit server, but cannot see anything in clear and thus cannot make an educated decision based on it. Your data may end up being forwarded to the zone where your traffic is not optimized, and you will end up waiting a little bit more. But, bear in mind, that the majority of complaints about Gerrit master/slave is not really on the speed of the push/pull but rather on the sluggish Gerrit GUI.
Of course, we’ll find as a Community a solution to the SSH problem, I would be more than happy to address that in multi-site as well.
Q: Solution is to get a better LAN because we don’t have any complaints about the GUI across the continents.
Okay, yeah, get a super fast network across the globe, so everyone and everywhere in the world will be super fast accessing a single unique central point. However, not everyone can have a super-fast network. For instance in GerritHub, we don’t own the infrastructure so we cannot control the speed. Similarly, a lot of people are adopting a cloud infrastructure, where you don’t own and control the infrastructure anymore.
Q: Would you also have some Gerrit slaves in this setup. Would there be several masters and some of the slaves? Or everything will become just a master?
In multi-site architecture, everything can be a master. The distinction between master and slave does not exist anymore. Functionally speaking, some of them will be master for certain repositories and slave for other repositories. You can say that every single node is capable of managing any type of operations. But, based on this smart routing, any node can potentially manage everything, but effectively forwards the calls based on where is best to execute them.
If with this simple multi-site solution you can serve the 99% of the traffic locally, and for that one percent, we accept the compromise of going a bit slower, than it could still sound very good.
We implement this architecture last year with a client that is distributed worldwide and it just worked, because it is very simple and very effective. There isn’t any “magic product” involved but simply standard OpenSource components.
We are on a journey, because as Martin said last year in his talk, “Don’t try to do multi-master all at once.” Every single situation is different, every client is different, every installation is different, and all your projects are different. You will always need to compromise, find the trade-off, and tailor the solution to your needs.
Q: I think in most of the cases that I saw up there, you were deploying a Gerrit master in multiple locations? If you want to deploy multi-master in the same sites, like say I want two Gerrit servers in Palo Alto, does that change the architecture at all? Basically, I am referring to shared NFS.
This is actually the point made by Martin: if you have the problem on multi-site, it’s not a problem of Gerrit, it’s a problem of your network because your network is too slow. You should solve the network, you shouldn’t solve this problem in Gerrit.
Actually, the architecture is this one. Imagine you have a super fast network all across the globe, everyone is reaching the same Gerrit in the same way. You have a super fast direct connection with your shared NFS, so you can go and grow your master and scale horizontally.
The answer is, for instance, yes, if your company can do that. Absolutely, I wouldn’t recommend doing multi-site at all. But if you cannot do anything about speed, and you got people that work remotely and unfortunately, you cannot go and put a cable between the U.S. and India, under the sea just for your company, then maybe you want to address the problem in a multi-site fashion way.
One more thing that I wanted to point out, is that the multi-site plugin makes sense even in the same site. Why this picture is better than the previous one? I’m not talking about multi-site, I’m talking about multi-master on the same data center. Why this one is better?
You’ll read and write into both. Read, write, traffic to both. The difference between this one and previous is that there is no shared file system on this one. The previous, even within the same data center, if you use a shared file system, you still have a single point of failure. Because, even if you are willing to buy the most expensive shared file system with the most expensive network and system that exists in the world, they will still fail. Reliability cannot be simply resolved by throwing more money on it.
It’s not the money that makes my system reliable. Machines and disks will fail one day or another. If you don’t plan for failures, you’re going to fail anyway.
Q: Let’s say when you’re doing an upgrade on all of your Gerrit masters right? Do you have an automatic mechanism to upgrade? I’m coming from a perspective where we have our Gerrit on Kubernetes. So, sure, if I’m doing a rolling upgrade, it’s kind of like a piece of cake, HAProxy is taking care of by confd and all that stuff, right? In your situation, how does an upgrade would look like, especially if you’re trying to upgrade all the masters across the globe? Do you pick and choose which site gets upgraded first and then let the replication plugins catch up after that?
First of all, the rolling upgrade with Kubernetes will work if you do minor upgrades. If you’re doing major Gerrit upgrades, it doesn’t. This is because that changes the data, right? With the minor upgrades, you do exactly the same here. Even if the others in the other zones have a different version, they are still interoperable, right, because they talk exactly to the same schema, exactly to the same API, exactly in the same way.
Q: I guess taking Kubernetes out of the picture, even, so with the current multi-master setup you have, if you’re not doing just a trivial upgrade, how do you approach that usually?
If you are doing a major version upgrade, that is going to orchestrate exactly like the GerritHub upgrade from 2.14 to 2.15. You need to use what I called a ping-pong technique. You basically need to do across data centers.
It’s not fully automated yet. I’m trying to automate it as much as possible and contribute back to the community.
Q: In the multi-master, when you’re doing the major upgrade, and even in the ping pong, so if the schemas changed, and you’re adding the events to replication plugin, are you going to temporarily suspend replication during the period of time? Because the other items on the earlier version don’t understand that schema yet. Can you explain that a little?
Okay, when you do the ping pong that was this morning presentation, what happens is the upgrade on the first node, interruption the traffic there, you do all the testing you want, you are behind with the original master but it catches up with replication and does all the testing.
With regards to the replication event, they are not understood by the client, such as the Jenkins Gerrit trigger plugin. That point was raised this morning as well. If you go to YouTube.com/GerritForgeTV, there is the recording of my talk of last year about a new plugin that is not subject to this fluctuation of Garret version.
Luca Milanesio – Gerrit Code Review Maintainer and Release Manager