First, a huge thank you to the OpenInfra Foundation for hosting this event in Paris. Their invitation to have the Gerrit User Summit join the rest of the community set the stage for a truly collaborative and impactful gathering.
Paris last weekend wasn’t just a conference; it was a reunion. Fourteen years after the last GitTogether at Google’s Mountain View HQ, the “Git and Gerrit, together again” spirit was electric.
On October 18-19, luminaries from the early days (Scott, Martin, Luca, and many others) reconvened, sharing the floor with the new generation of innovators. The atmosphere was intense, filled with the same collaborative energy of 2011, but focused on a new set of challenges. The core question: how to evolve Git and Gerrit for the next decade of software development, a future dominated by AI, massive scale, and an urgent demand for smarter workflows.
Here are the key dispatches from the summit floor.
A Historic Reunion, A Shared Future
This event was a powerful reminder that the open-source spirit of cross-pollination is alive and well. The discussions were invigorated by the “fresh air” from new-school tools like GitButler and Jujutsu (JJ), which are fundamentally rethinking the developer experience.
In a significant show of industry-wide collaboration, we were delighted to have GitLab actively participating. Patrick’s technical presentation on the status of reftable was a highlight, but his engagement in discussions on collaborative solutions moving forward with the Gerrit community truly set the tone. It’s clear that the challenges ahead are shared by all platforms, and the solutions will be too.
Scaling Git in the Age of AI
The central theme was scale. In this rapidly accelerating AI era, software repositories are growing at an unprecedented rate across all platforms—Gerrit, GitHub, and GitLab alike. This isn’t a linear increase; it’s an explosion, and it’s pushing SCM systems to their breaking point.
The consensus was clear: traditional vertical and horizontal scaling is no longer enough. The community is now in a race to explore new techniques—from the metal up—to improve performance, slash memory usage, and make core Git operations efficient at a scale we’ve never seen before. This summit was a rare chance for maintainers from different ecosystems to align on these shared problems and forge collaborative paths to solutions.
Dispatches from the Front Lines: NVIDIA and Qualcomm
This challenge isn’t theoretical. We heard powerful testimonials from industry giants NVIDIA and Qualcomm, who are on the front lines of the AI revolution.
They shared fascinating and sobering insights into the repository explosion they are actively managing. Their AI workflows—encompassing massive datasets, huge model binaries, and unprecedented CI/CD activity—are generating data on a scale that is stressing even the most robust SCM systems. Their presentations detailed the unique challenges and innovative approaches they are pioneering to tackle this data gravity, providing invaluable real-world context that fueled the summit’s technical deep dives.
Beyond the Pull Request: The Quest for a ‘Commit-First’ World
One of the most passionate debates centered on the developer workflow itself. The wider Git community increasingly recognizes that the traditional, monolithic “pull request” model is ill-suited to the “change-focused” code review that platforms like Gerrit have championed for years.
The benefits of a change-based workflow, cleaner history, better hygiene, and higher-quality atomic changes—are driving a growing interest in standardizing a persistent Change-ID for each commit. This would make structured, atomic reviews a first-class citizen in Git itself. The collaboration at the summit between the Gerrit community, GitButler, JJ, and other Git contributors on defining this standard was a major breakthrough.
This shift is being powered by tools like GitButler and JJ, which are built on a core philosophy: Workflow Over Plumbing. Modifying commits, rebasing, and resolving conflicts remain intimidating hurdles for many developers. The Git command line can be complex and unintuitive. These new tools abstract that complexity away, guiding users through commit management in a way that feels natural. The result is faster iteration, higher confidence, and a far better developer experience.
AI and the Evolving Craft of Code Review
Finally, no technical summit in 2025 would be complete without a deep dive into AI. The arrival of AI-assisted coding is fundamentally shifting the dynamic between author and reviewer.
Engineers at the summit expressed a cautious optimism. On one hand, AI is a powerful tool to accelerate reviews, improve consistency, and bolster safety. On the other, everyone is aware of the trade-offs. Carelessly used, AI-generated code can weaken knowledge sharing, blur IP boundaries, and erode a team’s deep, institutional understanding of its own codebase.
The challenge going forward is not to replace the human in the loop, but to strengthen the craft of collaborative review by integrating AI as a true co-pilot.
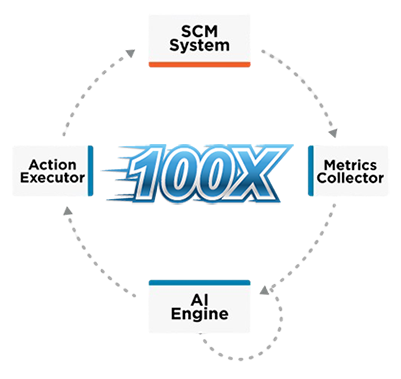
A Path to 100x Scale: The GHS Initiative
The most forward-looking discussions at the summit centered on how to achieve the massive scale required. One of the most promising solutions presented was GHS (Git-at-High-Speed). This innovative approach is not just an incremental improvement; it’s a strategic initiative designed to increase SCM throughput by as much as 100x.
The project’s vision is to enable platforms like Gerrit, GitLab, and GitHub Enterprise to handle the explosive repository growth and build traffic generated by modern AI workflows. By re-architecting key components for hyper-scalability, GHS represents a concrete path forward, ensuring that the industry’s most critical SCMs can meet the unprecedented demands of the AI-driven future.
The Road from Paris
The Gerrit User Summit 2025 was more than a look back at the “glorious days.” It was a statement. The Git and Gerrit communities are unified, energized, and actively building the next generation of SCM. The spirit of GItTogether 2011 is back, but this time it’s armed with 14 years of experience and a clear-eyed view of the challenges and opportunities ahead.
I started my business 17 years ago, with a simple mission: spread the use of Git into large enterprises worldwide. The goal was simple and challenging: convincing large companies to trust Git and fill the gaps separating them from migrating from their legacy systems.
The first product that came out of it was, not surprisingly, Git Enterprise. You can still access its official launch YouTube video (https://youtu.be/unJxlD2aopY), which attracted over 5k views and interest. Since then, my blog has been called GitEnterprise. My mission to work with large companies intensified, and I successfully reached my first client, who agreed to abandon Subversion, which was the de facto standard at that time, and adopt Git after seeing my product.
I didn’t know that Google had started with a similar idea for a different purpose: making Git suitable for large enterprises to cooperate on developing the Android Operating System. The Google project was called Gerrit Code Review, inspired by the Gerrit Ritvield Code Review tool built by Guido Van Rossum after he joined Google.
I donated all the code of GitEnterprise to the Gerrit Code Review project and joined the endeavour under the leadership of Shawn Pearce, the Gerrit project founder. Inspired by the new partnership, I also changed the name of my company to GerritForge to represent its new mission.
Fast forward to today, and a lot has changed. Gerrit is a complex ecosystem comprising a central Gerrit with its core plugins and a constellation of 200+ plugins created by a universe of over 800 contributors. GerritForge has also grown and started expanding to new countries, opening an HQ in Sunnyvale, California. After the passing of Shawn Pearce in 2018, who died from lung cancer, we also took over the management of the global community events and local meetups, to serve the need of coordinating and fostering collaboration amongst contributors and users worldwide. We owe it to honour Shawn’s legacy to make his project successful. He used to call Gerrit Code Review his “130% Google side-project”, as it was more of a mission than a $DAY_JOB for him.
The 100% pure Open-Source model I adopted over 17 years ago must be upgraded to tackle the new challenges of managing and supporting a larger organization and community, and ensuring that it will continue to innovate and evolve in the years to come.
Re-licensing GerritForge plugins
GerritForge has helped many organizations worldwide get the most out of Gerrit Code Review and benefit from a 100% Open-Source business model while relying on rock-solid Enterprise Support with quality gates, longer-term maintenance, and strict SLAs.
However, the marketplace is evolving, and fewer companies are willing to invest in pure 100% Open-Source communities. On the other hand, the recent threats from Cybercriminals targeting the supply chain have driven Enterprises to request a higher level of software and supplier certification, which may interfere with a 100% pure Open-Source contribution model.
After exploring many other options, including joining software foundations or traditional contracting, I have decided to switch from a pure Apache 2.0 Open-Source to a mixed Open-Core contribution model for creating a rock-solid Gerrit distribution that can satisfy the more stringent requirements of certification and compliance.
I have called this new software Gerrit Enterprise to avoid confusion with the Gerrit core, which remains 100% Open-Source.
GerritForge confirms its commitment to the Gerrit core and core-plugins Open-Source contributions under the current AOSP Apache 2.0 license. Some of the plugins developed almost exclusively by GerritForge will continue to be developed as a Commercial Product with a new software licensing model.
To explain the re-licensing policy with a formula: Gerrit Enterprise [Commercial Product] = Gerrit Core [Open-Source Apache 2.0] + GerritForge plugins [Commercial Product].
The licensing model we have chosen is called “Business Software License”, aka BSL.
What is BSL, and what does it mean
The term BSL or “BSL license” was used for the first time by Cockroach Labs (the creators of CockroachDB) back in 2019. “BSL license” most commonly refers to the Business Source License. This source-available license allows for public viewing and non-production use of source code but restricts commercial or production use unless a specific “additional use grant” is provided by the licensor. After a predetermined period, the BSL automatically converts to a fully Open-Source license. This model balances software developers’ need for revenue with the benefits of Open-Source, making software source-available while ensuring it eventually becomes Open-Source.
In a nutshell, the GerritForge plugins released under BSL will have more restrictions compared to the current Apache 2.0 Open-Source:
The requirement to receive a formal BSL License by GerritForge.
The Software License will be FREE of charge for small businesses up to $5M annual revenue, non-profit organizations, and non-productive environments.
Does not allow bundling, reselling, or reusing in other products and services without the written consent of GerritForge
All contributors to the plugins under BSL will have to sign a specific CLA with GerritForge
The source code cannot be modified, fully or in part, or reused in source or binary form in any other Open-Source project before the expiration of the BSL
After 5 years of the GerritForge’s plugins released date under BSL, the code will be automatically released as Apache 2.0 to the Gerrit-Review main repository.
The BSL model allows us to continue to develop our plugins in the Open and support the current versions under Apache 2.0, but it will ensure that we are in control of the way the software is certified, distributed, and guaranteed to all the users who benefit from it.
This initiative fosters a virtuous cycle of mutual benefit. The support from companies adopting Gerrit and GerritForge plugins will directly fuel the community, allowing us to reinvest in core software development, key summits, and local meetups, ensuring the ecosystem thrives.
Which GerritForge plugins are going to be under BSL?
The plugins chosen to be converted to a BSL license are the ones that are developed and maintained by GerritForge for at least 80% of the code in the past 24 months.
Also, GerritForge has decided to leave as Open-Source under the Apache 2.0 license the ones that are widely used by the community or reused in other projects.
The major plugins involved in the re-licensing as BSL are:
Gerrit Multi-Site, with its associated components, Kafka/Kinesis/PubSub brokers, Zookeeper/DynamoDb refdb, Healthcheck-Enterprise, and Websession broker
Pull-replication plugin
GitHub and Virtualhost plugins, which are the basis of GerritHub.io
Cache-Chroniclemap lib module
Gerrit and Git analytics, including git-repo-metrics
AWS deployment for Gerrit
Other minor plugins may be added at a later time
The re-licensing means that the new development will happen on the GerritForge organisation (https://github.com/gerritforge) on GitHub and GerritHub (https://review.gerrithub.io), and the current master branch will be deprecated on Gerrit-Review.
What happens to the current GerritForge plugins on the stable branches?
GerritForge confirms its commitment to continue supporting all the existing plugins, either from GerritForge or other contributors, on the stable and supported non-EOL versions (see https://www.gerritcodereview.com/support.html#supported-versions) on the current Google-owned Gerrit-Review site.
What happens to the current GerritForge plugins on the unsupported EOL branches?
What if I am using those plugins in production now?
The current version of the plugins you have installed in your production environment will continue to work and be under Apache 2.0 on the Gerrit-Review site. Once you upgrade to the newer version of Gerrit Code Review (e.g., Gerrit v3.13 or later), you must contact GerritForge (www.gerritforge.com/contact) to obtain a license key before proceeding with the upgrade in production.
What if I am a GerritForge customer and want to upgrade to a new BSL version?
All GerritForge customers have automatic access to the BSL version of the plugins under support. Their Gerrit Enterprise Support contracts and associated policies have not changed. The BSL will not have any impact on their budget or the service they receive today.
What if I have both Open-Source and BSL commercial plugins from GerritForge installed?
You need to obtain a BSL license for the ones released by GerritForge, and you can use them alongside any other Open-Source plugin. The Open-Source plugins are released under the Apache 2.0 license and hosted on Gerrit-Review, and are not subject to any BSL license.
Questions or Concerns?
I am happy to address your concerns and answer any questions you may have about the move we are making for GerritForge; feel free to ask questions on this blog post or get in touch with me through https://gerritforge.com/contact.
Our goal is to continue to exist and support the Gerrit Code Review community, today and for the foreseeable future. GerritForge BSL will allow us to continue to innovate and bring even more contributions and features to Gerrit core and its plugins.
Thank you for supporting us in the past and in the near future!
Luca Milanesio GerritForge co-Founder and CEO Gerrit Code Review Maintainer & Release Manager Member of the Gerrit Code Review Engineering Steering Committee
(TL;DR) The Gerrit Code Review project has an ambitious roadmap for 2025 and beyond. Gerrit 3.12 (H1 2025) will focus on JGit performance improvements, X.509 signed commit support, and enhanced Owners and Analytics plugins. Gerrit 3.13 (H2 2025) aims to further optimize push performance, UI usability, and plugin updates, including Kafka and Zookeeper integrations.
The k8s-Gerrit initiative will improve Gerrit’s deployment on Kubernetes, ensuring better scalability and resilience. Looking ahead, Gerrit 4.0 (2026/2027) plans to decouple the review UI from the JGit server, enabling alternative review interfaces and improved flexibility.
The development team is prioritizing significant performance enhancements in JGit, the Java implementation of Git used by Gerrit. Key objectives include:
Speeding Up Conflicting Ref Names on Push: This aims to reduce delays during push operations when ref name conflicts occur.
Enhancing SearchForReuse Latency for Large Monorepos: The goal is to improve latency by at least an order of magnitude, facilitating more efficient operations in extensive monorepositories.
Improving Object Lookup Across Multiple Packfiles: Efforts are underway to accelerate object lookup times by at least tenfold, enhancing performance in repositories with numerous packfiles.
Parallelizing Bitmap Generation: By enabling bitmap generation across multiple cores, the team aims to expedite this process, contributing to overall performance gains.
Gerrit Core Experience Enhancements
A notable feature planned for this release is the support for X.509 signed commits, which will bolster security and authenticity in the code review process.
Owners Plugin Improvements
Enhancements to the Owners Plugin are set to provide clearer insights and streamlined interactions:
Action Requirements Display: Explicitly showing required actions by each owner at the file level.
Detailed Pending Reviews: Offering more comprehensive information on pending reviews by owners.
Easier Contact with File Owners: Facilitating more straightforward communication with file owners.
Analytics Plugin Optimization
The analytics plugin is slated for improvements to enhance speed and usability:
Repo Manifest Discovery: Native support for discovering repository manifests.
Faster Metrics Extraction: Accelerated extraction of metrics for branches, aiding in quicker data analysis.
Gerrit 3.13 (Target: H2 2025)
JGit Performance and Concurrency Enhancements
Building upon previous improvements, version 3.13 aims to further optimize performance:
Optional Connectivity and Collision Checks: Improving push performance by allowing the skipping of certain checks when appropriate.
Customizable Lock-Interval Retries: Providing flexibility in managing lock intervals to enhance concurrency handling.
Read-Only Multi-Pack Index Support: Introducing support for read-only multi-pack indexes to improve repository access efficiency.
Gerrit Core and UI Experience Enhancements
User experience remains a focal point with planned features such as:
File List Filtering: Allowing users to filter the file list in the change review screen for more efficient navigation.
Headless Gerrit Packaging: Offering a version of Gerrit that serves only read/write Git protocols, catering to users seeking a streamlined experience.
Plugin Updates
The roadmap includes updates to key plugins:
Kafka Events-Broker: Upgrading to support Kafka 3.9.0, enhancing event handling capabilities.
Zookeeper Global-Refdb: Updating to support Zookeeper 3.9.3, improving global reference database management.
Replication Plugin Enhancements
Efforts to simplify configuration and improve performance include:
Dynamic Endpoint Management: Introducing APIs for creating and updating replication endpoints dynamically.
UI Integration: Displaying replication status within the user interface for better visibility.
Reduced Latency on Force-Push: Improving replication latency during force-push operations by applying objects with prerequisites.
k8s-Gerrit
The k8s-Gerrit initiative focuses on deploying Gerrit within Kubernetes environments, aiming to enhance scalability, resilience, and ease of management. This approach leverages Kubernetes’ orchestration capabilities to provide automated deployment, scaling, and management of Gerrit instances, facilitating more efficient resource utilization and operational consistency.
Gerrit 4.0 (Target: 2026/2027)
Looking ahead, Gerrit 4.0 is set to introduce significant architectural changes:
Decoupling Gerrit Review UI and JGit Server: This separation will allow the Gerrit UI and JGit server to operate as independent services, providing greater flexibility in deployment and scaling.
Enabling Alternative Review UIs: By decoupling components, the platform will support the integration of other review interfaces, such as pull-request systems, offering users a broader range of tools tailored to their workflows.
The Gerrit community is encouraged to stay engaged with these developments, as the roadmap is subject to change. Contributors planning to work on features not listed are advised to inform the Engineering Steering Committee (ESC) to ensure alignment with the project’s goals.
As 2024 draws to a close, it’s a great time to reflect on the milestones and achievements of the GerritForge team in innovating Git performance with the release of GHS, supporting and advancing the Gerrit Code Review project with 20 releases and over 1.5k commits. This year has been one of exciting developments and initiatives that have made Gerrit stronger, more accessible, and better equipped to meet the needs of modern software teams. Here’s what GerritForge accomplished for the Git and Gerrit Code Review ecosystem in 2024.
2024 in numbers
1,500 changes merged
40 repositories involved in the Gerrit and JGit projects
20 releases
5 conferences, 6 meetups
11 contributors, 4 maintainers
20k man/hours spent in open-source projects
Managing the Releases of Gerrit 3.10 and 3.11
As usual, we continue to ensure the regular releases of new Gerrit versions. This year was no exception with the releases of Gerrit 3.10 and 3.11. These releases introduced new features, performance optimisations, and bug fixes to further solidify Gerrit as the leading code review tool for large-scale projects.
Our team cooperated with the Gerrit Code Review community to ensure these releases were stable, well-documented, and aligned with community needs. From coordinating release schedules to ensuring compatibility with plugins and integrations, GerritForge played a key role in making these versions a reality.
Key Highlights
Gerrit 3.10 brought major improvements in user experience, including refined UI capabilities and enhanced search functionality.
Gerrit 3.11 introduced critical updates to multi-site support, security enhancements, and significant performance boosts.
GerritMeets success in both the USA and Europe
The GerritMeets series has become a cornerstone of community engagement, and 2024 was no exception. GerritForge organised six GerritMeets across several locations, including California, Germany, and the UK, bringing together contributors, users, and maintainers to share knowledge, discuss trends, and explore use cases. Each session covered a diverse range of topics, including:
Best practices for multi-site setups.
Advanced plugin development.
Gerrit performance tuning for large repositories.
Innovations in CI/CD workflows with Gerrit.
These virtual meetups provided a platform for collaboration and learning, reinforcing Gerrit’s community spirit. All the recordings of the 2024 GerritMeets are available as a playlist on the GerritForge TV YouTube channel.
World-class Enterprise Gerrit-as-a-Service on Google Cloud Platform
In 2024, GerritForge expanded Gerrit’s capabilities by adding support for Gerrit-as-a-Service (GaaS) on the Google Cloud Platform (GCP). This initiative makes it easier than ever for organizations to adopt Gerrit without the operational overhead of managing infrastructure.
Benefits of Gerrit-as-a-Service on GCP
Scalability: Leveraging GCP’s powerful infrastructure to scale Gerrit deployments for enterprises of any size.
Simplicity: Reducing setup and maintenance complexity, allowing teams to focus on development and code reviews.
High Availability: Utilizing GCP’s advanced networking and storage capabilities for improved uptime and disaster recovery.
By enabling Gerrit on GCP, GerritForge is broadening the tool’s accessibility, particularly for teams looking for a cloud-native, fully managed solution.
Gerrit User Summit with Qualcomm
This year’s Gerrit User Summit, organized by Qualcomm in collaboration with GerritForge, was a highlight for the community. Held at the Qualcomm HQ in San Diego, CA (USA), the summit offered a chance for Gerrit enthusiasts worldwide to come together in person. The agenda featured:
Keynotes by Gerrit maintainers and industry leaders.
Hands-on hackathon for contributors and users.
Insightful panels on the future of Gerrit.
The collaboration with Qualcomm not only expanded the summit’s reach but also highlighted Gerrit’s growing importance in enterprise environments.
Showcasing GHS and Gerrit Code Review worldwide
This year, GerritForge actively participated in numerous conferences to showcase GHS and expand Gerrit’s visibility, and demonstrate its unique capabilities. These events were a fantastic opportunity to uncover GHS and showcase Gerrit to hundreds of developers who had never encountered it.
At these conferences, we showcased:
GHS: It demonstrates its seamless integration with Git and showcases a whopping 100x performance improvement over a vanilla setup thanks to the power of AI and reinforcement learning.
K8s-Gerrit: Highlighting how Gerrit deployed on Kubernetes provides unparalleled flexibility, performance, and multi-site support.
Through live demos, presentations, and Q&A sessions, we highlighted GHS and Gerrit’s ability to scale, its unique review model, and its role in making software delivery pipelines up to 100x times faster.
K8s-Gerrit Hackathon with SAP
Collaboration was at the forefront of the k8s-Gerrit Hackathon, co-hosted by GerritForge and SAP. The hackathon brought together developers from both SAP and GerritForge teams to tackle the challenges of Kubernetes-based Gerrit deployments and multi-site support.
Outcomes of the Hackathon
Enhanced scalability for k8s-Gerrit deployments.
Breakthroughs in multi-site replication and disaster recovery.
Valuable contributions to the Gerrit codebase and documentation.
The event exemplified the power of open collaboration, pushing Gerrit further into cloud-native development.
Looking Ahead to 2025
As we celebrate the progress made in 2024, we remain focused on the road ahead. GerritForge is committed to:
Public offering of GHS
Gerrit-as-a-Service in Google Cloud
Gerrit Code Review v3.12 and v3.13
More GerritMeets and Gerrit User Summit events
Our gratitude goes out to the Git and Gerrit Code Review communities, contributors, and partners who have made this year a success. Together, we’re building a tool that empowers teams to deliver high-quality code faster and more efficiently. Here’s to an even more impactful 2025!
GerritForge has confirmed over 2023 its commitment to the Gerrit Code Review platforming, helping deliver two major releases: Gerrit v3.8 and v3.9.
The major contributions combined are focused on the plugins for extending the reach of the Gerrit platform, first and foremost the pull-replication and multi-site, as shown by the split of the 853 contributions across the projects, weighted by the number of changes and average modifications per change.
Pull replication plugin This is where GerritForge excelled in providing an unprecedented level of performance over anything that has been built so far in terms of Git replication for Gerrit. Roughly one-third of the Team efforts have contributed to the pull replication plugin, which provided over 2022/23 a 1000x speedup factor compared to Gerrit tradition factor. GerritForge has further improved its stability, resilience and self-healing capabilities thanks to a fully distributed and pluggable message broker system.
Gerrit v3.8 and v3.9 GerritForge helped release two major versions of Gerrit Code Review, contributing noteworthy features like Java 17 support, cross-plugin communication, importing of projects across instances and the migration to Bazel 7.
Owners plugin Jacek has completely revamped the engine of the owners plugin, boosting it with an unprecedented level of performance, hundreds of times faster than in the previous release, and bringing it to the modernity of submit requirements without the need to write any Prolog rules.
Multi-site plugin The whole team helped provide more stability and bug fixes across multiple versions of Gerrit, from v3.4 up to the latest v3.9.
JGit GerritForge kept its promises in stepping up its efforts in getting important fixes merged, including the optimisation of the refs scanning in Git Protocol v2 and the fix for bitmap processing with incoming Git receive-pack concurrency that we promised to fix at the beginning of 2023.
Migration of Eclipse JGit/EGit to GerritHub.io
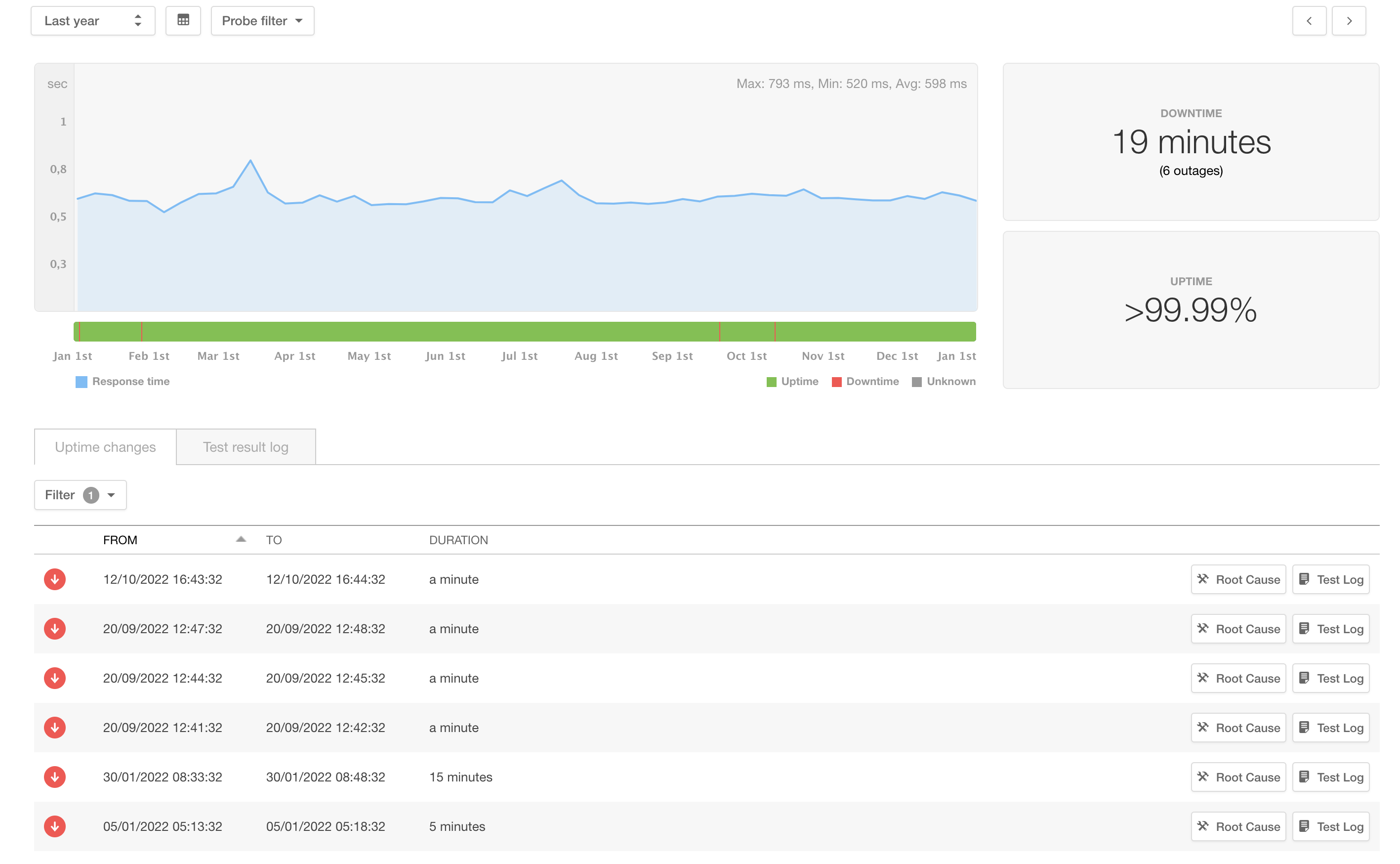
The 2023 has also seen a major improvement in GerritHub stability and availability, halving the total outage in a 12-month period from 19 to 10 minutes, with a total uptime of 99.998% (source: PIngdom.com)
The whole process was completed without any downtime and a reduced read-only window on the legacy Eclipse’s instance git.eclipse.org, which was needed because of the lack of multi-site support on the Eclipse side.
What we did achieve from our goals of 2023
JGit changes: we did merge 22 changes in 2023, most of them within the list of our targets for the year. One related to the packed-refs loading optimisation was abandoned (doesn’t get much traction from the rest of the community), and the last major one left is the priority queue refactoring still in progress on stable-6.6. Also, thanks to the migration of JGit/EGit to GerritHub.io, David Ostrovsky managed to get hold of its committer status and will now be able to provide more help in support in getting changes reviewed and merged.
JGit multi-pack index support: we did not have the bandwidth and focus to tackle this major improvement. The task is still open for anyone willing to help implement it.
Git repository optimiser: we kick-started the activity and researched the topic, with Ponch presenting the current status at the Gerrit User Summit 2023 in Sunnyvale CA.
Gerrit v3.8 and project-specific change numbers: the design document has been abandoned because of the need of rethinking its end-to-end user goals. However, we found and fixed many use cases where Gerrit wasn’t using the project/change-number pair for identifying changes, which is a pre-requisite for implementing any future project-specific change number use-case.
Gerrit Certified Binaries: the Platinum Enterprise Support for Gerrit has been enriched in 2023 with the certified binaries programme, with enhanced Gatling tests and E2E validation using AWS-Gerrit. Many bugs have been found and fixed in all the active versions of Gerrit; some of them were very critical and surprisingly undiscovered for months.
GerritForge Inc. revenue targets in the USA: the revenues increased by 50% in 2023, which was slightly below the initial expectations but still remarkable, despite the latest economic downturn of the past 12 months. 100% of the business has been transferred to the USA, including the GerritForge trademark and logo and we are now ready to start a new robust growth cycle in 2024 and beyond.
Looking at the future with AI in 2024
The recent economic news in the past 6 months has highlighted a difficult moment after the COVID-19 pandemic: the conjunction of the cost of living crisis, rising interest rates and two new major wars across the globe have pushed major tech companies to revise their small to medium-term growth figures, resulting in a series of waves of lay offs in the tech sector and beyond.
Whilst the layoffs are not immediately related to a lack of profitability of the companies involved, it highlights that in the medium term there will be a lot fewer engineers looking after the production systems across the company, including SCM.
SCM and Code Review are at the heart of the software lifecycle of tech companies and, therefore, represent the most critical part of the business that would need to be protected at all costs. GerritForge sees this change as a pivotal moment for stepping up its efforts in serving the community and helping companies to thrive with Gerrit and its Git SCM projects.
How do we maintain SCM stability with fewer people?
Gerrit Code Review has become more and more stable and reliable over the years, which should sound reassuring for all of those companies that are looking at a reduced staff and the challenge of keeping the lights on of the SCM. However, the major cause of disruption is represented by what is not linked to the SCM code but rather its data.
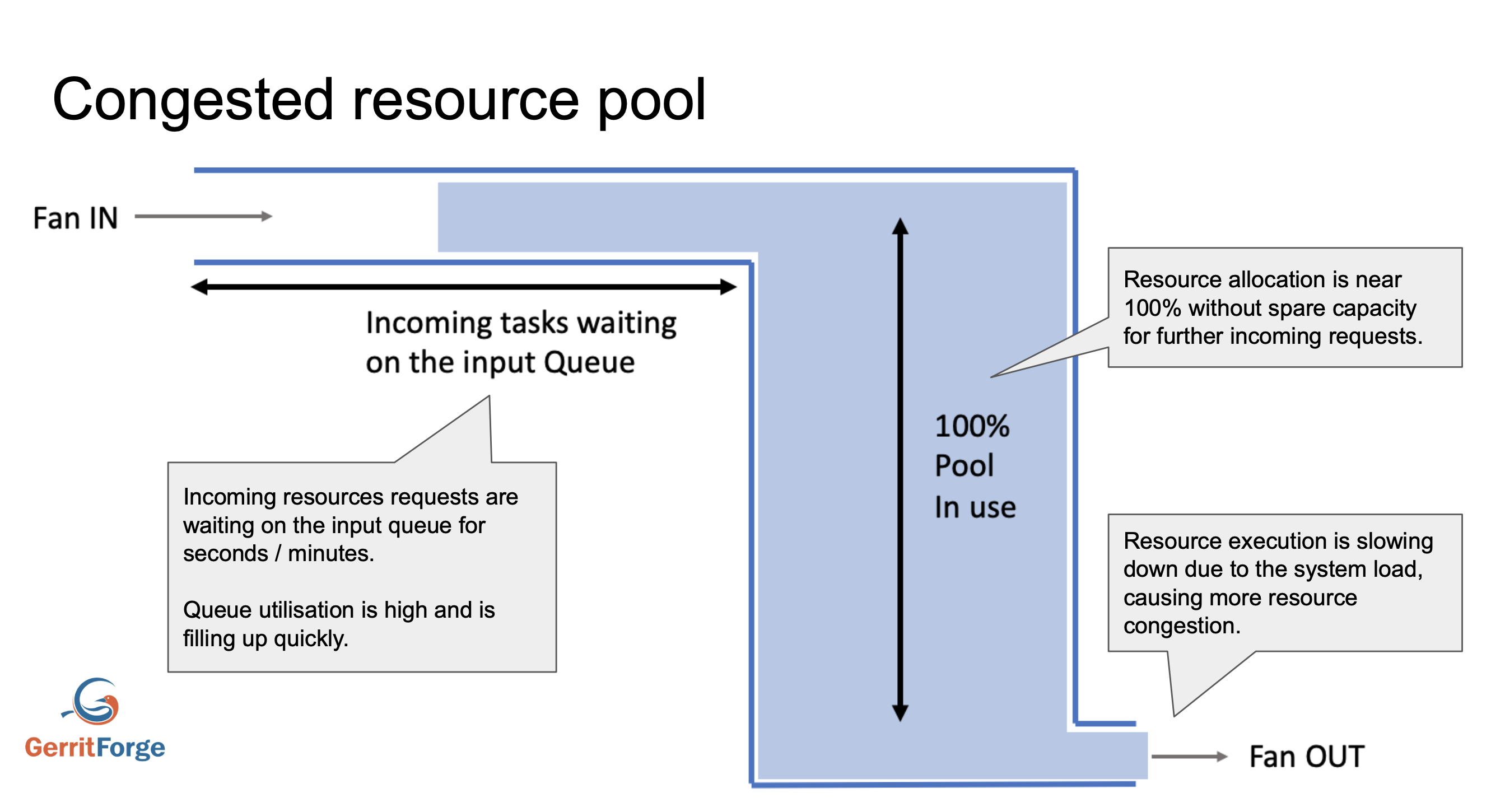
The Git repositories and their status are nowadays responsible for 80% of the stability issues with Gerrit and possibly with other Git servers as well. Imagine a system that is receiving a high rate of Git traffic (e.g. Git clone) of 100 operations per minute, and the system is able to cope thanks to a very optimised repository and bitmaps. However, things may change quickly and some of the user actions (e.g. a user performing a force-push on a feature branch) could invalidate the effectiveness of the Git bitmap and the server will start accumulating a backlog of traffic.
In a fully staffed team of SCM administrators and with all the necessary metrics and alerts in place, the above condition would trigger a specific alert that can be noticed, analysed, and actioned swiftly before anyone notices any service degradation.
However, when there is a shortage of Git SCM admins, the number of metrics and alerts to keep under control could be overwhelming, and the trade-offs could leave the system congestion classified as a lower-priority problem.
When a system congestion lasts too long, the incoming tasks queueing could reach its limits, and the users may start noticing issues. If the resource pools are too congested, the system could also start a catastrophic failure loop where the workload further reduces the fan out of the execution pool and causing soon a global outage.
The above condition is only one example of what could happen to a Git SCM system, but not the only one. There are many variables to take into account for preventing a system from failing; the knowledge and experience of managing them is embedded in the many of the engineers that are potentially laid off, with the potential of serious consequences for the tech companies.
GerritForge brings AI to the rescue of Git SCM stability
GerritForge has been active in the past 14 years in making the Git SCM system more suitable for enterprises from its very first inception: that’s the reason why this blog is named “GitEnterprise” after all.
We have been investing over 2022 and 2023 in analysing, gathering and exporting all the metrics of the Git repositories to the eyes and minds of the SCM administrators, thanks to open-source products like Git repo-metrics plugin. However, the recent economic downturn could leave all the knowledge and value of this data into a black hole if left in its current form.
When the work of analysing, monitoring and taking action on the data becomes too overwhelming for the size of the SCM Team left after the layoffs, there are other AI-based tools that can come to the rescue. However, none of them is available “out of the box” and their setup, maintenance and operation could also become an impediment.
GerritForge has a historic know-how on knowledge-based systems and has been lecturing the community about data collection and analysis for many years in the Gerrit Code Review community, for example the Gerrit DevOps Analytics initiative back in 2017. It is now the right time to push on these technologies and package them in a form that could be directly usable for all those companies who need it now.
Introducing GHS – GerritForge-AI Health Service
As part of our 2024 goals, GerritForge will release a brand-new service called GHS, directly addressing the needs of all companies that need to have a fully automated intelligent system for collecting, analysing and acting on the Git repository metrics.
The high-level description of the service has already been anticipated at the Gerrit User Summit 2023 in Sunnyvale by Ponch and the first release of the product is due in Q1 of 2024.
How does GHS work?
GHS is a multi-stage system composed of four basic processes:
Collect the metrics of your Gerrit or other Git repositories automatically and publish them on your registry of choice (e.g. Prometheus)
Combine the repository metrics with the other metrics of the system, including the CPU, memory and system load, automatically.
Detect dangerous situations where the repository or the system is starting to struggle and suggest a series of remediation policies, using the knowledge base and experience of GerritForge’s Team encoded as part of the AI engine.
Define a direct remediation plan with suggested priorities and, if requested, act on them automatically, assessing the results.
Stage 4, the automatic execution of the suggested remediation, can be also performed in cooperation with the SCM Administrators’ Team as it may need to go through the company procedures for its execution, such as change-management process or communication with the business.
However, if needed, point 4. can also be fully automated to allow GHS to act in case the SCM admins do not provide negative feedback on the proposed actions.
What the benefits of GHS for the SCM Team?
GHS is the natural evolution of GerritForge’s services, which have historically been proactive in the analysis of the Git SCM data and the proposal of an action plan. The GerritForge’s Health Check is a service that we have been successfully providing for years to our customers; the GerritForge Health Service is the completion of the End-to-End stability that the SCM Team needs now more than ever, to survive with a reduced workforce.
To the SCM Administrator, GHS provides the metrics, analysis and tailored recommendations in real-time.
To the Head of SCM and Release Management Team, GHS gives the peace of mind of keeping the system stable with a reduced workforce.
To the SCM users and developers, GHS provides a stable and responsive system throughout the day, without slowdowns or outages
To the Head of IT, GHS allows to satisfy the company’s needs of costs and head count reduction without sacrificing the overall productivity of the Teams involved.
GerritForge’s pledges to Gerrit Code Review quality and Open-Source
GerritForge has provided Enterprise Support and free contributions to Gerrit Code Review for 14 years, pretty much since the beginning of the project. We pledged in the past to be always 100% Open-Source and do commit to our promises.
For 2024, GerritForge will focus on delivering its promising Open-Source contributions to the stability and reliability of Gerrit Code Review, with:
Support for the Gerrit Code Review platform releases, Gerrit v3.10 and v3.11
Free support and development of the Gerrit CI validation process, in collaboration with all the other Gerrit Code Review contributors and maintainers
Free Open-Source fixes for all critical problems raised by any of its Enterprise Support Customers, available to everyone in the Gerrit Code Review community
Free Open-Source code base for the main four components of the new GHS product, following the Open-Core methodology for developing the service.
With regards to the initiatives that we started in the past few years, including pull-replication and multi-site, we believe they have reached a maturity level that would not need further major refactoring and extensions in 2024. We will continue to support and improve them over the years, based on the feedback and support requests coming from the Enterprise Support Customers and the wider Gerrit Open-Source community.
GHS AI engine and dogfooding on GerritHub.io.
GHS will have a rule-based AI system that will drive all the main decisions on the selection and prioritisation of the corrective actions on the system. As with all AI systems, the engine will need to start with a baseline knowledge and intelligence and evolve based on the experience made on real-life systems.
GerritForge’s commitment to quality is based on the base principle of dogfooding, where we use the system we develop every single day and learn from it. The paradigm is on the basis of our 14 years of success and we are committed to using it also for the development of GHS.
GerritForge has been hosting GerritHub.io since 2013, and tens of thousands of people and hundreds of companies are using it for their private and Open-Source projects every single day. The system is fully self-serviced; however, still relies on manual maintenance from our Gerrit and Git SCM admins.
We are committed to starting using GHS on GerritHub.io from day 1 and use the metrics and learning of the systems to improve its AI rule engine continuously. All customers of GerritForge’s GHS service will therefore benefit from historic knowledge and experience induced by the the learnings and optimisations made on GerritHub.io for the months and years to come.
GHS = Git SCM admins humans and AI-robots working together
GHS will revolutionise the way Git SCM admins are managing the system today: they will not be alone anymore, juggling a series of tools to understand what’s going on, but they will have an intelligent and expert robot at their service, driven by the wisdom and continuous learnings made by GerritForge, at their service every single day.
We expect a different future way of working in front of us: we are embracing this radical change in how people and companies work and making GHS serve them effectively and in line with our Open-Source pledges.
The future is bright with GerritForge-AI Health Service, Git and Gerrit Code Review at your service !
Luca Milanesio GerritForge CEO Gerrit Code Review Release Manager and member of the Engineering Steering Committee
21 November 2023 (Sunnyvale, CA) – GerritForge Inc. the leader in Gerrit Code Review Enterprise Support, has successfully re-hosted the Eclipse JGit/EGit projects on GerritHub.io, preserving 14 years of the repository history, including all changes, reviews and comments. Everything that has been produced and was historically available on the https://git.eclipse.org/r website is now fully available on https://eclipse.gerrithub.io.
The Eclipse Foundation started to encourage all of its projects to adopt Gerrit Code Review, which became the main hub where all the other Open-Source components and contributors were uploading their code and collaborating.
Today, the https://git.eclipse.org/r site hosts over 1300 repositories and tens of thousands of contributors and reviewers.
The risks of the announced shutdown
The Eclipse Foundation started looking at more comprehensive hosting solutions well beyond pure Git hosting and associated Code Review, including GitHub and GitLab and started using them side-by-side with their existing https://git.eclipse.org/r. In November 2021, the organisation decided to shut down the Gerrit Code Review instance giving as alternatives to migrate the projects to either GitHub or GitLab.
Although both GitHub and GitLab would have offered to keep the code history of all projects, the review information would have been completely lost. Gerrit Code Review has a JSON format (code-named NoteDb) for storing all the review comments together with the repository so that code and review meta-data can be kept safe in the same place. However, GitHub and GitLab have a more traditional relational DBMS approach and would have been unable to render Gerrit’s NoteDb.
If the project would have migrated to GitHub or GitLab, they could have created three main issues:
All the review history would have been formally accessible in the repository but not visible on the GitHub or GitLab UI
All associations between the NoteDb data and the committers’ identity would have been lost.
New reviews of the code developed on GitHub or GitLab UI would have been stored on a server-side relational DBMS.
GerritForge offers to rescue 14 years of review data
The main goal of GerritHub.io was to enable anyone who has a public or private repository on GitHub to use Gerrit Code Review on top of their existing data. All the authentication, authorisation and publishing of the repository stay on GitHub, whilst GerritHub.io provides the Code Review and collaboration experience.
The projects’ win: all their repositories would have been moved to GitHub, and all existing 14 years of review history and new reviews would be accessible through GerritHub.io
The migration project from git.eclipse.org/r to eclipse.gerrithub.io
The project was made possible thanks to the introduction of the “importing feature” in Gerrit v3.7, where projects can be moved between Gerrit instances by keeping their change numbers, accounts identities mapping and all associated review data.
Using existing GitHub projects on GerritHub.io is straightforward, and anyone can get started in a matter of minutes; however, the Eclipse Foundation case was more complex because of multiple additional requirements:
Custom validation of incoming Git commits authors against the Eclipse ECA policies. The Foundation had developed a custom plugin on Gerrit Code Review that needed to be amended to be suitable for a shared-hosting platform like GerritHub.io.
The Eclipse Foundation needed the configuration of specific OAuth scopes and permission tailored to the roles of the Eclipse Foundation contributors and reviewers.
Last but not least, the migration from https://git.eclipse.org/r to https://eclipse.gerrithub.io needed to be completed with zero downtime and minimal disruption for the existing committers and contributors to the project. Therefore, a classic “big-bang” migration with a planned outage was not an option.
Gerrit multi-site and the enablement of smooth migration paths
Being multi-site means that the “logical domain” (e.g. eclipse.gerrithub.io), instead of being served by a set of hosts in a single data centre, it can point to different locations across the globe, all active at the same time and accept read/write operations, such as Git push, clone, fetch and code-reviews. The full design of the solution is available on the multi-site plugin repository
When two users are pushing code at the same time to two different sites, Gerrit will check the destination refs against the SHA1 stored in the global-refdb and will coordinate the transactions to avoid ending up in a split-brain situation. Synchronisation between sites is achieved using the pull-replication plugin.
Gerrit Code Review is designed to be future-proof, thanks to a clear separation and contract between the front end and the backend REST-API. That allows a smooth blue-green migration between releases because every release of Gerrit is forward and backwards compatible with its next release +1. For example, GerritHub.io is running two different versions of Gerrit Code Review on different sites as we speak: v3.8.2 in the US and Canada (https://review-am.gerrithub.io) and v3.9.0-rc5 in Europe (https://review-eu.gerrithub.io), without anyone noticing any disruption. Each site progresses towards newer releases bi-weekly whilst the overall service remains active.
Project-based migration from git.eclipse.org to eclipse.gerrithub.io
Gerrit projects include all the commits and meta-data in the same repository and, therefore, have the perfect design to allow an easy migration between servers. However, there are some gotchas:
Every Gerrit server has a server-id associated with it, which is used to “tag” every change. That prevents Gerrit from parsing and indexing data that does not necessarily belong to the server.
Every NoteDb meta-data record is strictly decoupled from any Personal Identifiable Information (aka PII), including the full name and e-mails of the authors, committers, owners and reviewers of the changes under review. The lookup between the anonymised identity (aka account-id) and the PII is contained in a centralised repository called ‘All-Users.git’, which isn’t accessible.
Every change has a unique incremental number associated with it, the change number. The numbering sequence is unique per Gerrit server, but when moving projects between different servers, you may have numbering conflicts.
GerritForge has configured the server ID of git.eclipse.org as an “external imported server ID” so that every project coming from the Eclipse Foundation can be parsed and indexed. Its review metadata is rendered on the UI.
The identities are mapped using the public REST-API https://git.eclipse.org/r/accounts/NN/detail, which allows the association of GerritHub users with the legacy Eclipse Foundation account IDs matched by e-mail address.
The Open-Source version does not have support for multi-tenancy in the Gerrit core. However, I developed a minimalistic solution six years ago that would give the “user experience” of virtual hosting on Gerrit. The idea behind the solution is quite simple: hide unwanted projects based on the full domain name, pretty much like the virtual hosts work on the HTTP Servers world.
For example, you could define eclipse.gerrithub.io as follows:
Shawn himself was stunned when he saw the source code of the virtual-host libmodule back in 2017, with the comment “how did I end up writing so much code, if you did everything in just 7 Java classes?”
To be fair, the solution Shawn implemented on review-*.googlesource.com was a lot more comprehensive than the virtual-host libmodule, because it also included the ability to have different gerrit.config per tenant, whilst the solution implemented on GerritHub.io is a simple extra permission filter applied based on the domain name.
That means that all the Eclipse repositories are effectively available on any of the GerritHub.io sites and also accessible with the main domain URL https://review.gerrithub.io; the filtering on the virtual-host is a pure visibility setting for avoiding the users coming from the Eclipse Foundation from being overwhelmed by the other 50k projects hosted on GerritHub.io.
The advantage is that all the current GerritHub.io sites replicate the Eclipse Foundations repositories, providing, therefore, additional redundancy to the overall setup. All commits pushed to any of the repositories on eclipse.gerrithub.io will also be replicated to all sites, including the ones NOT starting with eclipse.gerrithub.io. Thanks to this redundancy, all the projects hosted on GerritHub.io can benefit from an astonishing 99.997% availability, well above any other free Git hosting sites for Open-Source available right now.
What’s next for the other 1,300 repositories on git.eclipse.org?
The work done for migrating the JGit and EGit projects to https://eclipse.gerrithub.io is the ground needed for the reuse of the same path for many more repositories and projects that want to keep their review history before the legacy git.eclipse.org site is going to be shut down by the Eclipse Foundation. The scope definition, the user accounts association, and the provision of the users and projects are going to be exactly the same for any other project that wants to move to keep its history.
Migrating projects between Gerrit instances was declared impossible just a few years ago; however, that was the end goal of the whole Gerrit NoteDb project. Shawn Pearce used to say that he “would like to make all his reviews locally on his laptops and just push code and reviews once they landed“, making the Code Review an integral part of the Git data format.
The success of this migration project is the demonstration that Shawn’s vision was really innovative and, thanks to the cooperation of the community, projects can last and persevere well beyond the boundaries and lifetime of the people who initially founded them.
Migrating projects and consolidating Gerrit Servers is not something that is only applicable to this example of the Eclipse Foundation server shutdown, but can be further applied to other domains and use cases. Companies are constantly changing, splitting and merging; projects need to follow the organisation and also move between Gerrit Servers and domains.
All the innovations introduced in Gerrit v3.7 and beyond can serve as an example of the implementation of a different migration path compared to the traditional big-bang approach.
One important lesson from the Eclipse Foundation’s experience is that every migration comes with many little but important details: all of them need accurate evaluation, implementation and testing. Upfront planning is needed; however, many times, many more details are found along the migration path, making it difficult to estimate correctly all the efforts and costs associated. Migrating is like doing daily exercising, the first round sounds quite lengthy and challenging, however, the following rounds can reuse the tools and experience earned in the previous migrations.
Lastly, this exercise has shown how important it is to keep the project’s history for planning its future. It would have been unthinkable for the JGit/EGit projets to continue developing without being able to leverage the learnings, discussions and experience from the past.
“The Code Review history is our legacy; learning from our past gives us direction for our future.”
Luca Milanesio GerritForge, Inc. – CEO and CTO Gerrit Code Review Maintainer Gerrit Release Manager Member of the Gerrit Engineering Steering Committee
TL;DR: GerritForge has been dedicating its efforts to organising and managing the Gerrit User Summit in London back in November 2022, in conjunction with the release of Gerrit v3.7. The event has been a great success, with a significant presence on-site and record-breaking attendees on the GerritForge TV youtube channel. It has also committed to its promises to research and improve the JGit and Gerrit scalability to large mono-repos, with tens of millions of objects and refs. 2023 will see the finalisation of these efforts with an increase in development efforts and a new JGit Committer for pushing the platform to a new level of performance and scalability and a new innovating system for collecting and optimising the repository metrics automatically. Stay tuned.
Read the full story here below (9 mins read).
2022 has been a critical year for turning the Gerrit Code Review community and development back on track after the COVID-19 pandemic. At GerritForge, we’ve been working hard to make sure that the development, support, and innovation of Gerrit Code Review continue on its main objectives.
Gerrit Code Review v3.6 and v3.7
We have continued to deliver on the development and release of Gerrit Code Review and its plugins, helping the testing and releasing of versions v3.6.0 (May) and v3.7.0 (November).
3,627 Changes have been merged on 76 projects related to the Gerrit Code Review platform, including JGit
113 committers from 42 different organisations
A special mention to the top #10 contributors: Google (Ben Rohlfs, Edwin Kempin, Chris Pouchet, Dhruv Srivastava, Frank Borden, Milutin Kristofic), GerritForge (Luca Milanesio), Wikimedia (Paladox) and SAP (Matthias Sohn and Thomas Dräbing).
In comparison with 2021, we had 25% fewer changes merged but with more contributors coming from more companies, which is a symptom to a very healthy and thriving ecosystem of maintainers.
GerritForge has committed to resuming the face-to-face user summits, which were suspended since 2020.
It was a glorious success, with record-breaking attendance from all around the globe:
50 people registered to attend on-site, 26 of them managed to arrive despite the London tube strike, whilst the others attended remotely
235 people viewed the summit on YouTube with an average view time of 40 mins (one talk)
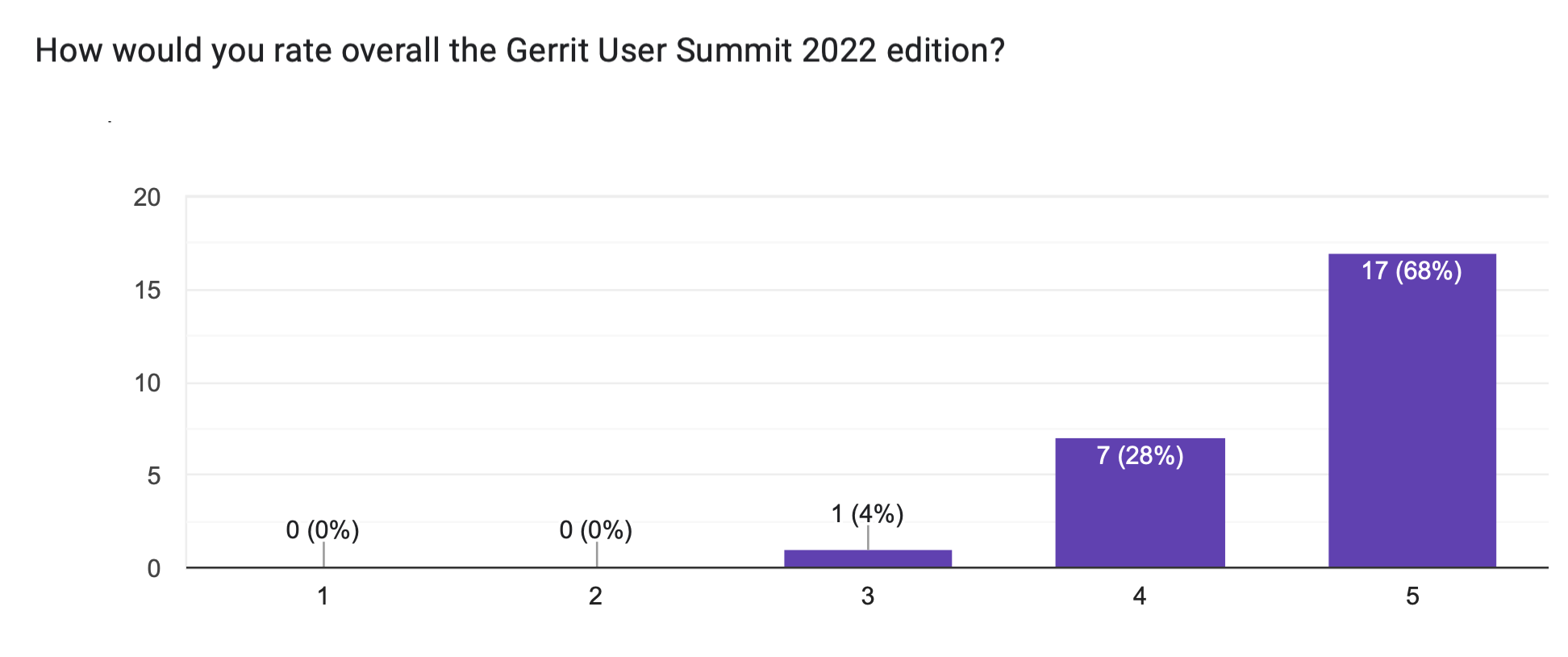
The summit survey had an outstanding report showing a huge acceptance and appreciation of the event:
82% rated the remote video streaming as “good” or “outstanding”
96% rated the quality of the summit as “good” or “outstanding.”
100% would recommend the summit to a colleague, with 83% strongly recommending it
GerritHub.io SLA gets closer to five-nines.
We have been working hard to make Gerrit more stable and resilient throughout 2022, discovering and fixing many issues in the code base and on the multi-site software architecture. In 2022, GerritHub.io had only six small hiccups for a total of 19 mins of downtime (SLA = 99.997%) over a 12-month period, a 75% reliability improvement compared to 2021.
We have run extensive RCAs on the causes of the downtime and identified two leading issues, which are explained in the details below.
The “anonymous unlimited query” hole in Gerrit GerritHub.io has been subject to a 15 mins outage because of anonymous users being able to bring offline all the sites before the system could auto-recover. Gerrit allows bypassing of all limits set in the ACLs for running queries by simply adding the “no-limit” parameter. Returning an arbitrary payload without limits could allow a single user to generate a server-side workload for collecting and building a GBytes-sized JSON payload; unfortunately, that option was available to everyone, including anonymous users making any publicly faced Gerrit Code Review installation subject to deny-of-service attacks. We have identified the issue, reported and fixed it in Gerrit with Change 333304, which has been included in Gerrit v3.3.10, v3.4.4, v3.5.1, and all v3.6.0 or later releases.
More granular monitoring and alerting We have lowered the threshold of uptime checks on GerritHub.io to 1 minute, giving us the ability to detect and react immediately to 4 smaller hiccups. We have detected a lack of scalability for some specific higher-load projects. Those hiccups have been responsible for 2 mins of downtime over the 2nd part of 2022. Many more projects are also planning to be onboarded on GerritHub.io; hence we do need to address this project-specific capacity needs.
Scaling Gerrit Code Review and JGit beyond its limits
We have been investing a massive effort in building a test environment designed to stress Gerrit and JGit to its limits and identify all the limitations and bottlenecks that prevented us from scaling further.
Scaling the test repository We have created over the months some test repositories that increased in every dimension:
Tens of millions of refs as both refs/changes and refs/heads
Millions of delta-chains
Tens of millions of Git objects
Packfiles of tens of Giga-bytes and packed refs of hundreds of megabytes
For generating a significant load on both client and server side, we have invested more into the aws-gerrit cloud setups and gatling-git performance loading tool.
There were some “well-known” issues and additional surprising ones.
SHA1 complexity and CPU utilization for large entities JGit has been used SHA1 for identifying uniqueness not just for Git objects but also for other large entities. However, computing SHA1 has become increasingly CPU intensive because of the relatively recent findings about collisions on shattered.io. We have highlighted two major potential improvements in cooperation with Matthias Sohn (SAP) on the raw SHA1 performance and its application for detecting packed-refs changes on the filesystem.
Commit priority queues JGit has a custom implementation of priority queues which are intensively used in RevWalk, which has almost quadratic complexity. That isn’t a problem for small to medium chains of commits; however, when the number of commits reaches millions, the performance degradation becomes unbearable. We have replaced the JGit’s custom implementation with the one provided by the Java JVM library, which has a logarithmic complexity that massively improves its performance with large commit chains.
Unwanted reachability checks JGit needs to perform a full reachability check whenever a remote unknown client is advertising refs, which makes sense when serving a remote client. However, the cost of full reachability of millions of advertised refs can be a daunting task that may be alleviated if the remote end can be considered trusted.
Fixing JGit bitmaps Since the introduction of Git bitmap, the whole community has learned how key they are in speeding up the counting and selection during the clone phase. However, large and unoptimized bitmaps could be so unhelpful for Git that instead of speeding up, they could represent a massive overhead for the system, causing CPU spikes and, eventually, lowering the throughput of the server. Git bitmaps are compressed using the JavaEWAH library, which is good for memory consumption but evil for CPU utilization: that is the reason why the smaller is best for performance. We have discovered and fixed a critical issue with the JGit bitmap generation that was causing the inclusion of all commits and BLOBs pointed by annotated tags. Also, we have introduced the ability to inform JGit about the heads that can be excluded from the bitmap, allowing to shorten the creation tens of thousands times (5h generation time for a 2k refs to as little as 60s) and increase its effectiveness by 200%.
Millions of unneeded ref logs When performing a clone of a repository with millions of heads, JGit created one local reflog file for every remote ref, including the ones there were not actually cloned but just fetched as remote references. This was creating a significant performance gap between JGit and Git, which would instead lazily create the reflog files once they are effectively checked out the first time. Cloning a single branch of a repository with millions of remote refs took around 1h, compared to a few minutes of Git.
All of the findings were included in multiple updates on the following components:
aws-gerrit is going through upgrades for making use of pull-replication plugin, including the support for the bearer token which allows to replicate virtually any repository, including All-Users.git
gatling-git: we have upgraded the Gatling version and JGit to the latest stable-5.13 to include the latest performance improvements.
git-repo-metrics: we have introduced a brand-new plugin that allows us to keep under control the major dimensions of a repository and therefore graph their increase over time.
GerritForge goals for 2023
We are definitely not done yet with the performance improvements on Gerrit and JGit: there are still significant improvements to be made, and JGit changes to get merged into the mainstream branches. We believe we are on track to finalize the job and allow a stable and scalable platform for large Git repositories in 2023.
Finalise what we cooked in 2022 for JGit JGit has a new maintainer, David Ostrovsky, awarded in 2022 as Git committer of the project. GerritForge’s devs are focused to get more reviews and attention to the JGit performance improvements. We are committed to finalising all the open changes related to large repositories.
JGit multi-pack indexes support There is still a major gap between JGit and Git when dealing with very active repositories: multi-pack indexes. The proliferation of packfiles would eventually lead to a long and painful search-for-reuse phase for BLOBs which could be cut down 100s of times with a multi-pack index.
Git repository optimiser for Gerrit We have been working on tracking the live information on the Git repository, thanks to the git-repo-metrics plugin. Wouldn’t it be nice to have a tool that can do something with it and automatically? We would be doing R&D on how to correlate the repository metrics, the Git audit trail, and the performance data for making AI-based decisions on what needs to be improved on the repository. This work stream is going to be useful for any Git repository, not just the ones powered by Gerrit Code Review. The ‘git-repo-metrics’ and the repository optimiser would also apply to other products, including GitHub and GitLab.
Gerrit v3.8 and projects-specific change numbers We will finalise the design document for the transition to project-specific change numbers in Gerrit v3.8. That would allow the seamless migration of projects across Gerrit setups without having to worry about changes renumbering anymore.
Gerrit Code Review testing and GerritForge-certified binaries GerritForge is spending a tremendous amount of time developing test environments and tools for serving the Gerrit community with more stable releases and improving the quality of its code. We want to intensify the effort and also offer our platinum support customers a unique service that includes the GerritForge digital signature and rubber stamp on the binaries of Gerrit Code Review and its plugins that have been successfully tested and validated for being production-ready. Stay tuned; more details are coming soon …
GerritForge company forecast in 2023
GerritForge Inc. will finalise its roll-out to the USA, and all contracts and services will be run from Sunnyvale, CA and Europe. Over 2022, 60% of the customers and businesses have already been moved, and the operation will be completed over the course of 2023.
We are looking forward to doubling our revenue figures in 2023 and also our contributions to the open-source community, with a main focus on JGit as the driver of performance growth for Gerrit Code Review.
It has been seven years since we first introduced the native packages for Gerrit Code Review. At that time, Docker was just two years old and was starting to pick up momentum: the native packages found their first incarnation in the Gerrit Code Review base on images published on DockerHub.
Since then, Gerrit has always been released as both a “plain vanilla” war file and the equivalent “native packaging” flavors, including the base Docker images.
In the beginning, the release managers mainly used the Gerrit Docker images to simulate pre-configured test environments for testing purposes. However, the adoption spiked up when Kubernetes and AWS Container Services (aka ECS) started to become mainstream.
Nowadays, the Gerrit base images on Dockerhub are pulled millions of times and used as the baseline for creating Enterprise-grade setups, like in the aws-gerrit recipes.
x86 Native Packaging
Even though it wasn’t initially thought off, the native packages ended up mainly in x86-based containers, even though Gerrit is a 100% pure-Java application. How was that possible?
Dependencies: gerrit.sh requires some basic OS services to work properly, including the native git command line.
Build & testing: the build of gerrit.war and associated testing was always performed on x86, also due to the restrictions of the platform supported by Bazel at that time.
ARM-64 takes off
The ARM processor comes from the historical legacy of Acorn Computers Ltd, a British-born company of the 80s, well known for the BBC Micro project. Back in the 90s, a new joint venture was created with Apple Computer and VLSI Technology to design a brand-new Advanced Risc Machine (aka ARM).
Over time, ARM has created first a 32-bit architecture and subsequently a 64-bit architecture processor, well known and appreciated for its low-power consumption and performance efficiency.
Whilst Intel, with its x86 architecture, dominated the desktop and the server market, the ARM architecture found its natural market space in the low-power devices and, more recently, the mobile phones market.
Apple goes ARM-64, everywhere
Apple initially adopted the ARM architecture on its mobile phones and portable devices, licensing the instruction set to build its microchips in 2010. Ten years later, Apple announced it was also transitioning all the other desktop devices to its ARM-based silicon.
Nowadays, nearly all Apple laptops are on ARM and the other devices are migrating to that too. The applications are rapidly adapting to the new instruction set and getting rebuilt quickly, gaining in both performance and increased battery life.
Cloud services are moving to ARM-64 too.
The move from x86 to ARM-64 brings noticeable advantages in terms of costs and energy efficiency has been recently amplified by the increase in the costs of electricity triggered by the spiked wholesale prices of oil, gas, and other fossil fuel.
GCloud (see T2A offering ) and AWS (see EC2 Graviton) offer now ARM-64 based VMs that promise a healthy 60% reduction of cloud hosting costs and higher throughput and performance per $.
Gerrit has always put high performance and low operating costs at the top of its agenda, allowing companies to keep their development teams highly productive with minimum dedicated staff looking after the system.
Now it is also time to reduce the Gerrit Code Review Cloud hosting costs and increase efficiency while preserving all the benefits that Gerrit brings.
Introducing ARM-64 native packages for Gerrit Code Review
Gerrit Code Review native packages are now available for ARM-64 on all its recent releases, from v3.4.8 onwards. If you are currently running on x86, you can easily switch to ARM-64 transparently by just rebuilding from the base image. All the DockerHub images have been repackaged and republished:
On Debian, just refresh the repository cache with ‘apt-get update‘ and the new packages will automatically show-up and be available for setup.
Because this is a repackaging of the existing Gerrit release, the 4th number of the package name has been updated, e.g., gerrit-3.4.8-2 is the package name associated with the ARM-64 compatible package.
Ready to switch to ARM-64?
The Gerrit maintainers have already switched to ARM-64 with the recent wave of MacBook upgrades: all the non-EOL Gerrit releases are typically developed on Apple M1 or M2 which are based on ARM-64 rather than x86.
The need to reduce costs and the overall carbon footprint of the Gerrit project would most likely drive the CI agents’ switch to ARM-64 very soon.
Are you ready to switch to ARM-64 to reduce your operating costs and help the planet by reducing your Gerrit consumption?
Q&A
Q1. Are Gerrit on x86 and ARM-64 compatible in terms of data?
Yes, because the underlying data structure is platform-independent and is all based on Git, which is already interoperable cross-platform.
Q2. Can I mix&match x86 and ARM-64 Gerrit nodes?
Yes, by adopting the Gerrit multi-site setup, you can configure and host different sites on different architectures.
Q3. Will Gerrit on x86 continue to be supported?
Yes, because we want to allow the Gerrit administrator to choose the most suitable platform for his users and compatible with his Company’s requirements.
If you cannot come to London to attend face-to-face, the entire event will be live-streamed on the internet on GerritForge’s live stream channel, already successfully used in the past for the Summit 2019 in Sunnyvale.
How to register
You can pre-register for the online event by visiting https://live.gerritforge.com and clicking the orange button “Register to Watch.”
You would need to provide your name, e-mail, and affiliation (specify “independent” if you are attending just for personal interest) and your consent to be contacted with detailed instructions on the day of the event.
You may also request to be included in future communications about the subsequent events organized by GerritForge Inc. for the Gerrit Code Review community.
On the 10th of November 2022, around one hour before the event, you will receive via e-mail all the instructions for watching the event.
Thanks again for coming to London or watching and engaging with the event remotely.
See you next week at the Gerrit User Summit 2022 !
Luca Milanesio – GerritForge Gerrit Code Review Maintainer, ESC member and Release manager.
Dear fellow Gerrit User, We are pleased to announce that GerritForge will be organizing this year’s Gerrit User Summit and Hackathon in hybrid mode: face-to-face and online.
Gerrit User Summit is the event that brings together Gerrit admins, developers, practitioners, and the whole community, in one place, providing attendees with the opportunity to learn, explore, network face-to-face, and help shape the future of Gerrit development and solutions.
After two years of remote meetings and virtual conferences, this year, we are back face-to-face at CodeNode in the heart of the vibrant City of London.
The dates will be: Nov 7th to 9th – Hackathon Nov 10th to 11th – User Summit
Shortly we will be publishing the full schedule and logistics for the event. I look forward to meeting all the community’s friends, face-to-face or virtually, again during the Hackathon & Summit.
Thanks for being a part of the Gerrit community, and we look forward to seeing you in November.
Luca Milanesio Maintainer, member of the Engineering Steering Committee, and Gerrit Code Review Release Manager