After two years of remote events and three COVID-19 waves, we are finally back for a new face-to-face hackathon, talking about the future of Gerrit Code Review and coding new and innovative solutions for making Gerrit better, faster and more scalable.
Dates and schedule
The Gerrit hackathon will start on the 9th of May at 9:00 AM for five consecutive days, and will have a daily schedule from 9:00 AM to 7:00 PM BST, with networking and catch-up in the evenings.
For the remote attendees on the US/Pacific time-zone, the schedule will be daily between 7:00 AM to 11:00 AM PDT, which allows 4h of remote interaction with the hackathon in London.
Who is invited to attend the hackathon?
As with every Gerrit hackathon, we have a restricted audience: Gerrit maintainers and contributors are invited to join. We have 10 seats available on-site and 15 seats available remotely, which would allow plenty of people to collaborate and discuss.

To register to the Gerrit hackathon, add your name and role (“Gerrit Contributor” or “Gerrit Maintainer”) to the attendees sheet. All Gerrit maintainers have edit permissions to the document whilst all other contributors can request permission to edit if they are willing to attend.
Where is the hackathon taking place?
GerritForge will host the Gerrit Hackathon at Huckletree West, Mediaworks, 191 Wood Ln, London W12 7FP. We will be staying at the “Alphabet” meeting room, with a dedicated 10-seats and roundtable, a full-size wall-mounted whiteboard and a permanent online connection and wall-attached screen to interact with all the other remote attendees.

Huckletree is a creative workspace in West London, based in the heart of White City Place, a thriving new business and cultural district. Alongside the neighboring BBC Studios, Net A Porter Group, and RCA School of Communication, Huckletree West is part of a bold new chapter in the rich creative history of the neighborhood.
For all remote attendees, there will be the ability to connect remotely and interact with the rest of the team on-site during the hackathon hours.
White City and local accommodations
Huckletree West is close to the WestField Shopping Centre in White City, which includes 289 stores, 95 restaurants and Cinemas with 20 screens and almost 3,000 seats.
White City has excellent connections to all parts of London through the London Underground network (Central, Hammersmith&City and Circle lines) and Overground trains, which allow to reach all other parts of the city.

You can look for any Hotel or other accommodation (B&B or Hostels) in other part of London which is covered by the London Underground connections. However, if you are willing to stay local, there are many choices of Hotels and B&B starting from £80/night. See below a list of accommodations nearby White City:
- OYO Abbey Hotel, 23 Wood Lane Shepherds Bush
- Hotel Shepherds Bush London, 11-12 Poplar Mews, Shepherd’s Bush
- Dorsett Shepherds Bush London, 58 Shepherds Bush Green
- Hilton London Kensington Hotel, Holland Park Avenue
Travelling to the hackathon
By airplane: from London Heathrow terminals, take the Piccadilly Line to Central London till Hammersmith, then take the Hammersmith&City line (station is across the street) until Wood Lane station. From London Stansted, take the Stansted Express train to Liverpool Street station and then the Circle Line to Hammersmith until the Wood Lane station.
By train: from the Eurostar Terminal at St. Pancras International, take the Hammersmith&City or Circle line to Edgware Road until the Wood Lane station.
Taxi: you can use the London Black Cab as well as other cheaper alternatives such as Uber or local minicabs companies.
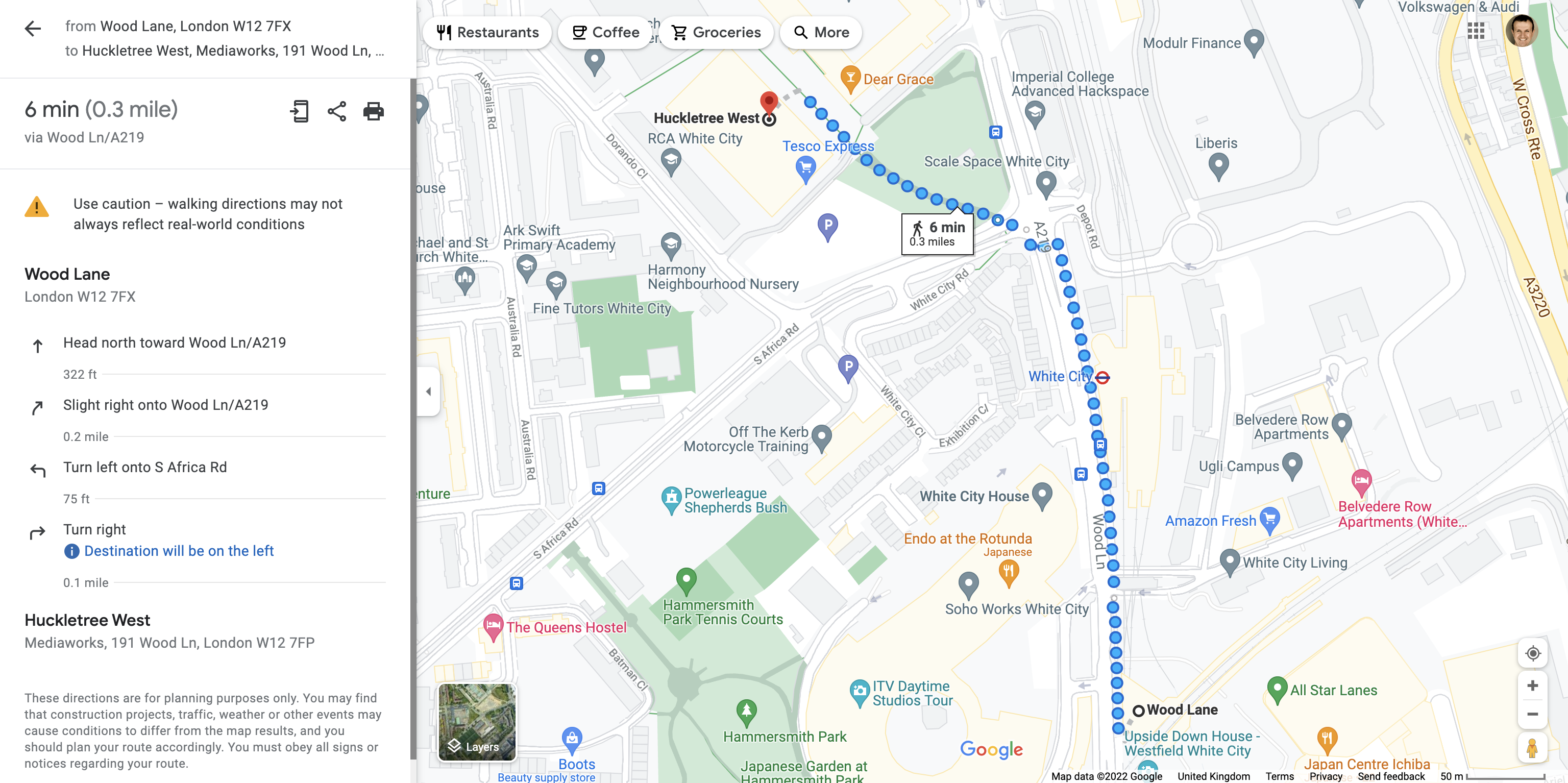
From the Wood Lane station, there is a 6 minutes walk to reach Huckletree West, located in the MediaWorks building on the ground floor.
Brexit restrictions
The UK has left the European Union the 1st of January 2021, all travellers from EU needs to follow the new rules for business trips. You can check if you need a VISA using the UK Government site and what is the required documentation and insurance required to show at the UK Border.
COVID-19 restrictions
The UK is set to end all COVID-19 restrictions by March 2022, which means there aren’t any vaccination or testing requirements for the attendees to the hackathon. We advise everyone attending face-to-face to take extra precautions and take a lateral-flow test (LFT) or antigen test before traveling to the hackathon, even though it is not required by law or regulations.
Please note that face covering are still mandatory whilst travelling by airplane, train or underground and during taxi rides.
We are excited to meet again the community of Gerrit Code Review maintainers and contributors after so many months. Come and join us in London this year and we can innovate again and help shaping the future of the Gerrit project, together.
Luca Milanesio, GerritForge
Gerrit Code Review Maintainer
Gerrit Code Review Release Manager
Member of the Engineering Steering Committee of the Gerrit Code Review Open-Source project