A Special Report from the Gerrit User Summit 2025
First, a huge thank you to the OpenInfra Foundation for hosting this event in Paris. Their invitation to have the Gerrit User Summit join the rest of the community set the stage for a truly collaborative and impactful gathering.
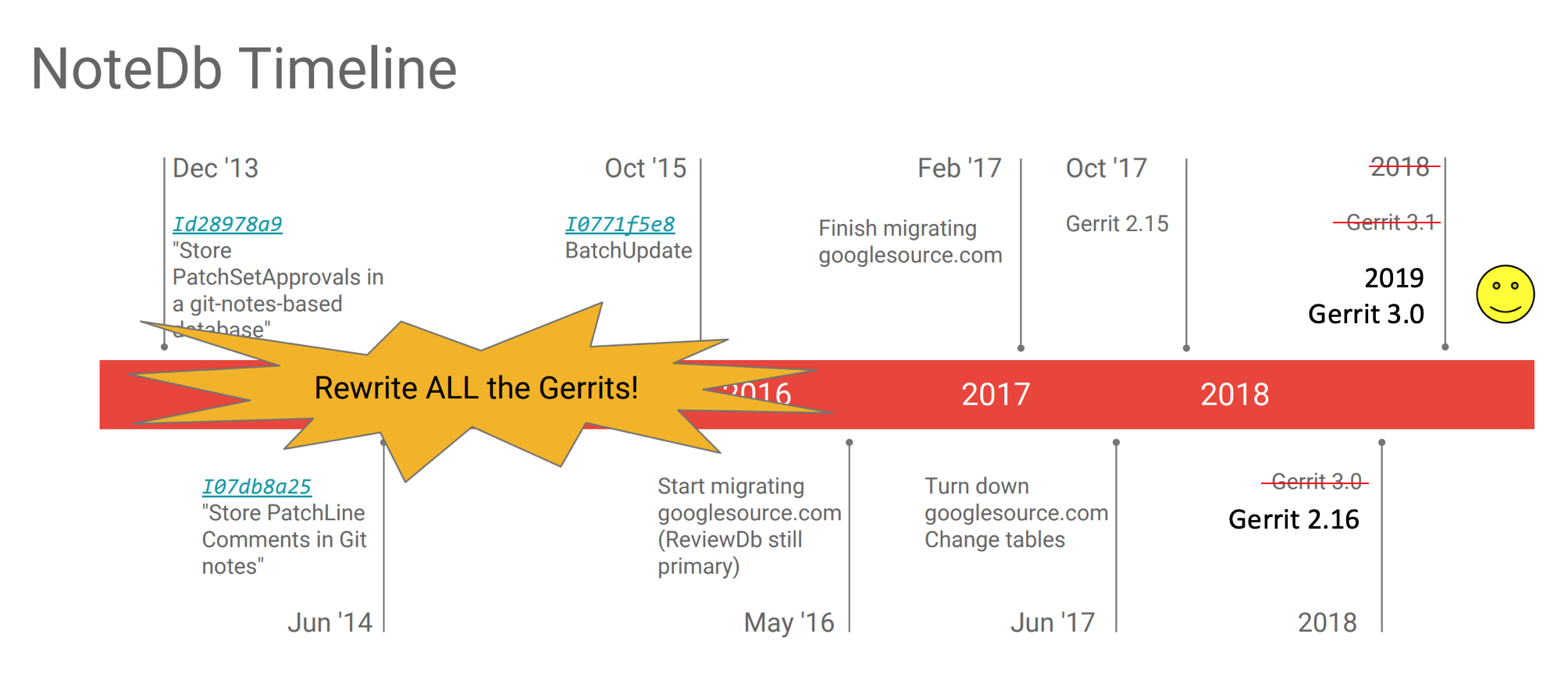
Paris last weekend wasn’t just a conference; it was a reunion. Fourteen years after the last GitTogether at Google’s Mountain View HQ, the “Git and Gerrit, together again” spirit was electric.
On October 18-19, luminaries from the early days (Scott, Martin, Luca, and many others) reconvened, sharing the floor with the new generation of innovators. The atmosphere was intense, filled with the same collaborative energy of 2011, but focused on a new set of challenges. The core question: how to evolve Git and Gerrit for the next decade of software development, a future dominated by AI, massive scale, and an urgent demand for smarter workflows.
Here are the key dispatches from the summit floor.
A Historic Reunion, A Shared Future
This event was a powerful reminder that the open-source spirit of cross-pollination is alive and well. The discussions were invigorated by the “fresh air” from new-school tools like GitButler and Jujutsu (JJ), which are fundamentally rethinking the developer experience.
In a significant show of industry-wide collaboration, we were delighted to have GitLab actively participating. Patrick’s technical presentation on the status of reftable was a highlight, but his engagement in discussions on collaborative solutions moving forward with the Gerrit community truly set the tone. It’s clear that the challenges ahead are shared by all platforms, and the solutions will be too.
Scaling Git in the Age of AI
The central theme was scale. In this rapidly accelerating AI era, software repositories are growing at an unprecedented rate across all platforms—Gerrit, GitHub, and GitLab alike. This isn’t a linear increase; it’s an explosion, and it’s pushing SCM systems to their breaking point.
The consensus was clear: traditional vertical and horizontal scaling is no longer enough. The community is now in a race to explore new techniques—from the metal up—to improve performance, slash memory usage, and make core Git operations efficient at a scale we’ve never seen before. This summit was a rare chance for maintainers from different ecosystems to align on these shared problems and forge collaborative paths to solutions.
Dispatches from the Front Lines: NVIDIA and Qualcomm
This challenge isn’t theoretical. We heard powerful testimonials from industry giants NVIDIA and Qualcomm, who are on the front lines of the AI revolution.
They shared fascinating and sobering insights into the repository explosion they are actively managing. Their AI workflows—encompassing massive datasets, huge model binaries, and unprecedented CI/CD activity—are generating data on a scale that is stressing even the most robust SCM systems. Their presentations detailed the unique challenges and innovative approaches they are pioneering to tackle this data gravity, providing invaluable real-world context that fueled the summit’s technical deep dives.
Beyond the Pull Request: The Quest for a ‘Commit-First’ World
One of the most passionate debates centered on the developer workflow itself. The wider Git community increasingly recognizes that the traditional, monolithic “pull request” model is ill-suited to the “change-focused” code review that platforms like Gerrit have championed for years.
The benefits of a change-based workflow, cleaner history, better hygiene, and higher-quality atomic changes—are driving a growing interest in standardizing a persistent Change-ID for each commit. This would make structured, atomic reviews a first-class citizen in Git itself. The collaboration at the summit between the Gerrit community, GitButler, JJ, and other Git contributors on defining this standard was a major breakthrough.
This shift is being powered by tools like GitButler and JJ, which are built on a core philosophy: Workflow Over Plumbing. Modifying commits, rebasing, and resolving conflicts remain intimidating hurdles for many developers. The Git command line can be complex and unintuitive. These new tools abstract that complexity away, guiding users through commit management in a way that feels natural. The result is faster iteration, higher confidence, and a far better developer experience.
AI and the Evolving Craft of Code Review
Finally, no technical summit in 2025 would be complete without a deep dive into AI. The arrival of AI-assisted coding is fundamentally shifting the dynamic between author and reviewer.
Engineers at the summit expressed a cautious optimism. On one hand, AI is a powerful tool to accelerate reviews, improve consistency, and bolster safety. On the other, everyone is aware of the trade-offs. Carelessly used, AI-generated code can weaken knowledge sharing, blur IP boundaries, and erode a team’s deep, institutional understanding of its own codebase.
The challenge going forward is not to replace the human in the loop, but to strengthen the craft of collaborative review by integrating AI as a true co-pilot.
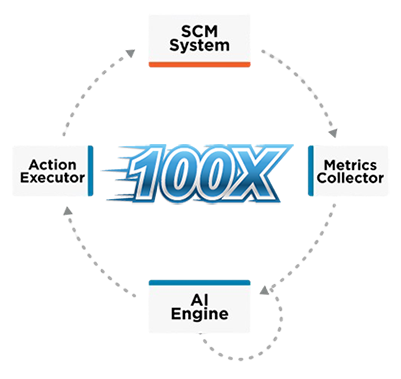
A Path to 100x Scale: The GHS Initiative
The most forward-looking discussions at the summit centered on how to achieve the massive scale required. One of the most promising solutions presented was GHS (Git-at-High-Speed). This innovative approach is not just an incremental improvement; it’s a strategic initiative designed to increase SCM throughput by as much as 100x.
The project’s vision is to enable platforms like Gerrit, GitLab, and GitHub Enterprise to handle the explosive repository growth and build traffic generated by modern AI workflows. By re-architecting key components for hyper-scalability, GHS represents a concrete path forward, ensuring that the industry’s most critical SCMs can meet the unprecedented demands of the AI-driven future.
The Road from Paris
The Gerrit User Summit 2025 was more than a look back at the “glorious days.” It was a statement. The Git and Gerrit communities are unified, energized, and actively building the next generation of SCM. The spirit of GItTogether 2011 is back, but this time it’s armed with 14 years of experience and a clear-eyed view of the challenges and opportunities ahead.
Antonio Barone – Gerrit Maintainer, Release Manager
Luca Milanesio – Gerrit Maintainer, Release Manager, Gerrit Engineering Steering Committee
Jacek Centkowski – Gerrit Maintainer
















 We have already discussed in
We have already discussed in