My name is Luca Milanesio, and I work for GerritForge. My talk today is about plugins and how to create them using scripting languages.
Gerrit plugins, where it all began
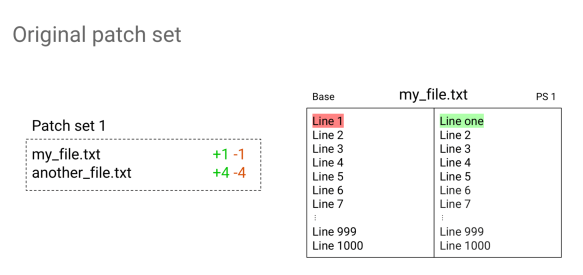
My contribution to the Gerrit Code Review project started in 2011 with the introduction of plugins. To understand where we are coming from we need to back to those times when the project was just born a year earlier. Gerrit was mighty since its very beginning, and different companies that used and contributed to the tool had tailored the code base to their specific needs. When I joined the GitTogether conference in 2011, almost every user was talking about their fork of Gerrit. Forking is excellent especially in OpenSource because you can customise a project as much as you want and, we were all excited about the growing popularity of GitHub and forking was a popular concept. However, keeping a fork up-to-date is not as easy as you may initially envision. Moving on with the upstream releases is hard when you are working on a fork.
Back in 2011 when I was at the conference, I thought: “how can the Gerrit project evolve and grow if we are all working on forks?”. My way to convince the Gerrit Community to change that status quo was inviting Kohsuke Kawaguchi, the Jenkins CI project founder, to the summit. Jenkins CI is wholly based on plugins while the core does not do much: the plugins are making the whole thing work as a CI.
That was enough to convince the community that a change was needed and, during the next Hackathon in 2012, I wrote the initial version of the Gerrit plugin loader and the first “Hello world” Gerrit plugin was born.
The introduction of scripting languages
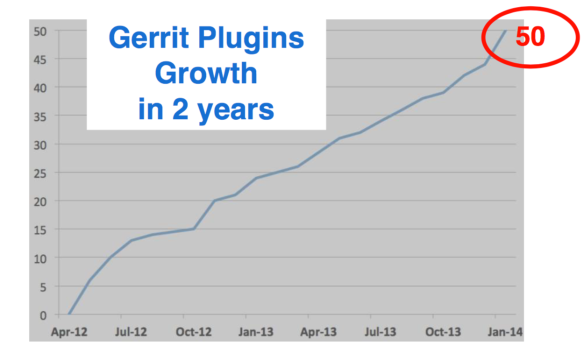
After two years, Gerrit had only 50 plugins. If you had looked at Jenkins, at that time they had over 600 plugins, ten times as many plugins compared to Gerrit. Writing a new plugin for Gerrit was still too hard for most developers and administrators.
To develop a new Gerrit plugin you needed to know way too many things and have many skills: a different build system (Buck and now Bazel), having a full development environment and all the required dependent packages.
We still had new plugins because some people went through the initial pain of setting up the environment. However, for a project to thrive, you need to get people together and embrace a diversity of skills to allow people to give the best of their knowledge.
Maybe the typical Gerrit admin is not a Java Developer, possibly could be more familiar with Groovy because the Ruby syntax is used a lot of DevOps tools. Others are more familiar with Python, and if you accept what they can contribute, the project can benefit from many more experiences from different people and backgrounds.
What does the community think about it?
Once I shared my ideas with the community, the feedback was great. However, different people with different backgrounds started asking to use very different languages, ranging from Scala to Groovy and Python. Then I realized that supporting one scripting language would not have been good enough for most of the people.
“Hello world” in Groovy
To give you an idea of how easy is to write a new plugin in Groovy, see the following example.
import com.google.gerrit.sshd.*
import com.google.gerrit.extensions.annotations.*
@Export("groovy")
class GroovyCommand extends SshCommand {
public void run() { stdout.println "Hi from Groovy" }
}
It is straightforward to write scripting plugins: put the above content in a hello-1.0.groovy file in the Gerrit’s /plugins directory and as soon as the file is saved the plugin is there and will be loaded in Gerrit within a few seconds.
The way that Gerrit recognize this file being a plugin is through its .groovy extension. The file name denotes both the plugin name and its version, delimited by the ‘hyphen’ on the filename. In this example the file hello-1.0.groovy identify a plugin called ‘hello’ with a ‘1.0’ version.
One warning about Groovy: it is a language that relies on Java Reflection for method invocation. Reflection is a capability of the Java Runtime and enables methods discovery which is handy to use but is slower than a native Java language.
The drawback of the ease of use of the Groovy language is the CPU cycles at runtime.
The beauty of using a scripting language for plugins is the speedup of the development cycle: as soon as you edit the Groovy file on the file system, the old plugin is unloaded and the new one loaded in Gerrit. The plugin development lifecycle becomes so much faster compared to the traditional Java application development.
Develop Scripting plugins using Docker
Gerrit is provided as a Docker image on DockerHub. The ‘gerritcodereview’ organization has an image name called ‘gerrit’ with all the versions available denoted as tags since Ver. 2.14. Earlier versions of Gerrit docker images are available on the ‘gerritforge’ DockerHub organization.
In the following example I am running Gerrit 2.14.4 on Docker fetching the image directly from DockerHub:
docker run -ti -p 8080:8080 -p 29418:29418 gerritcodereview/gerrit:2.14.4
In the above example, Gerrit is exposed through HTTP on port 8080 and exposes its SSH interface at port 29418.
Docker is a system that allows running containers, which are application “packaged” with everything needed, including other components of libraries of the underlying operating system. The only requirement on your physical host is the Docker engine, which exists nowadays for MacOS and Windows other than Linux where it was originally designed. Whatever operating system you are running on your laptop, Docker is there.
Docker can be handy for all the contributors that are not familiar with Gerrit Development Environment. There is no need to know or install anything on the local box, other than running the Gerrit Docker container. When I am running Gerrit in this way in this example, it starts straight away, with zero installation steps or configuration.
Gerrit out-of-the-box experience
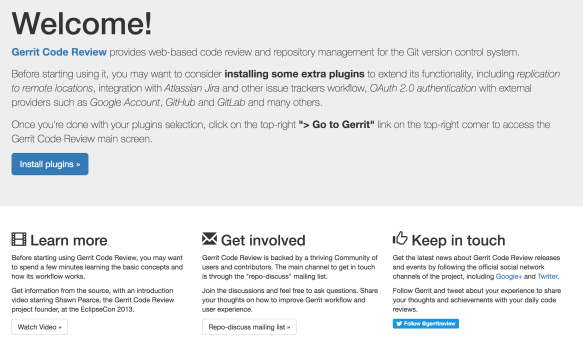
The second significant value of the Gerrit Docker container is that includes an out-of-the-box configuration, a welcome screen, and the plugin manager. It consists already a set of components that, if you are not familiar with Gerrit, will help you a lot to understand what is Gerrit and how to use it.
As you can see from this screen, Gerrit has started, and if you navigate to http://localhost:8080, it shows you an initial welcome screen.
Historically the very first screen, once you have installed Gerrit, was a blank screen. I remember a few years ago people coming to me saying that as new Gerrit users they were quite confused: they just did not know what to do with the initial blank screen. In Gerrit Docker, the initial screen is a “Welcome” which is a beautiful thing to say to people that you did not know that came to your house. Additionally, it provides some useful links and information to install plugins, which is very important because Gerrit without plugins is missing some fundamental parts of its functionality.
Playing with Gerrit Plugin Manager
By clicking the “Install plugins” button, you reach the Gerrit Plugin Manager screen. For all of those who are familiar with Jenkins, it provides precisely the same functionality as in Jenkins. If you type ‘groovy’ in the search bar, you can easily find where the Groovy scripting provider is, and you can install it with a simple click. That is the plugin you need to tell Gerrit that from now on, every file in the /plugins directory with a .groovy extension is a plugin that needs to be parsed and loaded at runtime.
You can discover and install other plugins as well. For instance, typing ‘github’ would list the integration of Gerrit with GitHub authentication and pull requests, or typing ‘jira’ would return the association and workflow integration with Jira Tickets.
The plugin manager is a fantastic discovery mechanism to understand what are the integrations available for Gerrit Code Review.
The plugin manager automatically discovers the versions of the plugins that are compatible with the Gerrit you are currently running and, when you click ‘Install’, it downloads them and installs them locally. When you are done, just click on the top-right link “Go To Gerrit” and you are straight into Gerrit UX.
How we have a running Gerrit instance that has installed all the plugins I need, including the support for Groovy plugins.
Writing plugins in Scala
If you need want to leverage the Gerrit scripting plugins, but you need optimal performance at runtime, you can use a different scripting language such as Scala.
The Scala language allows compiling into the native Java bytecode; it does not use reflection for method calls and, for some operations could be even faster than the Java language itself. See the same hello world example but rewritten in Scala.
import com.google.gerrit.sshd._
import com.google.gerrit.extensions.annotations._
@Export("scala")
class ScalaCommand extends SshCommand {
override def run = stdout println "Hi from Scala"
}
When I showed this to the community people got so excited and started writing tons of scripting plugins.
What scripting plugins do in Gerrit?
Admin tasks as SSH commands
Sometimes Gerrit admins need to automate specific tasks, however, coding an external script could be slower and difficult to implement. Inside Gerrit, there are already a lot of objects which represent pre-processed in-memory entities ready to be used. It makes sense to leverage all the information that is in-memory already and write new SSH commands like Scripting plugins to control admin tasks remotely.
Scripted REST API
At times you need as well to tailor existing Gerrit REST API to your needs. For instance, imagine that your company has specific policies for requesting new repositories: why not then creating a new ‘Create Project’ REST API tailored for your needs using the Scripting plugins and expose it through a company HTML form? You can do it without the need to be an experienced Java or Gerrit contributor and using a simple Groovy script for the new REST API.
Low-footprint hooks events
A third option is fascinating because, before the introduction of Gerrit plugins, the only way to react to Gerrit events was through hooks or stream events. Hooks are a traditional Git mechanism and, in Gerrit, have a scalability problem: they are invoked for every project and every event that happens anywhere and spawn a different asynchronous process. Over time the extra processes created can cause a significant overhead for your super-busy Gerrit server.
When a hook script needs to read from the Git repository, it would then need to process from scratch the packfiles from the local filesystem, uncompress and parse them in memory over and over again, which could slow down your server significantly.
If you are implementing Gerrit events using plugins, the same processing could be ten or even hundreds times faster.
This week we are honored to publish the amazing talk of Gerrit Ver. 2.15 presented by Dave Borowitz, the “father” of NoteDb review format. It is the very first time that a full roadmap of the migration from the traditional ReviewDb (a relational DBMS) to NoteDb (a pure Git notes-based review store) is drawn and explained in all details.
First steps with Gerrit Ver. 2.15 using Docker
For all of those who want to experiment what Dave has presented at the Gerrit User Summit, there is a Gerrit Ver. 2.15 RC2 Docker image already published on DockerHub on https://hub.docker.com/r/gerritcodereview/gerrit.
See below the simple instruction on how to start a Gerrit 2.15 locally and playing with it.
Open your web-browser at http://localhost:8080 and you will automatically get into the plugin manager selection. At the moment only the core plugins are available, so you can just click on to top right “Go To Gerrit” link.
As soon as Gerrit 2.15 will be officially available, you would be able to discover and install many more plugins on top of your installation.
Step 3 – Create a new Repository
Click on the new top “BROWSE” menu and select “CREATE NEW”
Then insert the repository name (e.g. “gerrit-playground”), select “Create initial empty commit” to True and click on “CREATE“.
Step 4 – Clone the repository
From the repository page select the “HTTP” protocol and click on the “COPY” link next of the “Clone with commit-msg hook” section.
Click on “CODE-REVIEW+2” button on the right toolbar to approve the change and then press “SUBMIT” to merge into the master branch.
What’s new in Gerrit Ver. 2.15
Hi, I’m Dave Borowitz, I work for Google, and I’m going to talk about what is new in Gerrit 2.15. We have a six months release cycle, and it has been around 158 days since Ver. 2.14.0 was released in April, and now, just last night at 10 PM, I have release 2.15-RC0.
Gerrit Ver. 2.15 in numbers
Gerrit Ver. 2.15 is aligned with other recent releases:
2,102 commits
53 contributors from all around the world and different companies
seven new contributors who have never commit before
I don’t know if any of the new contributors are in this room and if they are, thank you, if not I will thank them remotely.
PolyGerrit frontend
There is a bunch of new stuff going on in Gerrit Ver. 2.15, I will talk only briefly about the frontend, because we had an excellent talk from Logan and Arnab and Justin this morning about what’s happened recently in PolyGerrit.
I want to give you my perspective as a developer that is doing mostly backend work. It’s fascinating to have in Gerrit a modern JavaScript environment to develop in because it has been historically difficult for us to attract frontend developers in the project. There are not just enough GWT developers in the world as there are JavaScript developers and I think that the Gerrit project has suffered from a lack of UI attention in the past because of that.
But now we have a whole team here at Google, we have a lot of external contributors, that are happy to work on modern JavaScript, and PolyGerrit has made some excellent strategies of improving the user experience.
PolyGerrit is also usable. Everyone that has been working in software development always has the attraction of starting from scratch and say “how would have done it differently, “: PolyGerrit follows a little bit that approach.
We understand that we have users that are used to a certain workflow and we have to preserve it. However, when you are writing new code, you have the opportunity to learn from your past mistakes and improve things and maybe make it easier to onboard new people.
There is a little bit of preview of what PolyGerrit looks like in Gerrit Ver. 2.15; I had to cut the screenshot last night to make sure that it would be entirely accurate.
You can see that there is a reasonable rate of improvements, even in the last 24h and I hope that we will keep this peace of development.
Backend
From Ver. 2.15 we support NoteDb, and we suggest that you should convert your existing ReviewDb to NoteDb.
What is the motivation for doing NoteDb? Until now the Gerrit administrators had to be DBMS Administrators as well which is a sort of weird feeling: you care about version control and software development workflow, and, for some reasons, you should take care about being a DB Admin?
The idea behind is that we carry on the data historically stored in ReviewDB and we move it directly into the Git repository.
When you create a new change with a patch-set, a topic and all its meta-data, including comments and reviewers then everything gets stored in the same Git repository with the rest of the committed change data. There are several advantages in storing data and meta-data in this way.
You don’t have to worry about two stores that somehow are going to get eventually inconsistent. If you have to make a backup of your Gerrit Server, you have to take a Database dump and then to have a backup of all of your repositories. If you want to have a consistent backup where everything that is stored in the Database exists in the Git repository and vice-versa, you have to do it while the server is down. There is no other way to do it because you may get new records in the database while you are backing up the Git repositories and you would not see that data reflected.
With NoteDb, it’s all in the Git repository, and it is even better because we changed JGit to be able to write to multiple Git repositories refs atomically atomically. This means you can submit a change and also submit the status of the meta-data at the same time. When you upload a patch-set, we update three refs, either all of them succeed, or all of them fail. There isn’t a state where the change was merged in the branch, but the ReviewDb wasn’t updated, that is just no longer possible. That enables us to have consistent backups.
NoteDb provides a very helpful audit log. We had a lot of data issues in the past where could not understand how a change got into a particular state because in ReviewDb you just update a field with ‘X’ and you forget completely that the field was previously with a value ‘Y.’ In Git the model you append commits to a history graph, so you actually store every operation that has ever happened on NoteDb, and that gives you an understanding on how a change ended in the current state.
We are thinking about giving extensibility for new features, and this is a kind of optimistic view about the future, plugins will be able to add new data to NoteDb while it wasn’t possible for a plugin to add a new column to an existing table of ReviewDb. I don’t think that we have any plugins that are currently able to leverage this capability and we do not have any extension for it yet, but the data layer supports it.
Whilst is automatically giving new features such as moving changes between Gerrit hosts without having to throw away code review meta-data.
NoteDb roadmap
We never actually pictured in the past a complete NoteDb timeline, which spreads across five long years.
2013
The very first commit on NoteDb was in December, that was a very long time ago.
2014
We had an intern, and he wrote all the stuff on inline comments in NoteDb.
2015
I wrote a thing that it was at the end a good idea in retrospective, but it was a considerable amount of work. It is called the batch update and allows to have a coordinated transaction across two different data-store with a consistent interface. This period is what I called “rewrite every single line of Gerrit”.
2016 We started migrating googlesource.com; ReviewDb still existed, and it was always the single source of truth in case they got out of sync with NoteDb. Later this year, a few months ago, we moved everything to NoteDb and we don’t use the change table anymore. We have several hundreds of servers nowadays using NoteDb and generated several hundreds of changes to it. That is exciting, we have been running in production for months, and that’s why we believe it could work for other people to run in production.
2017 Last night, we released Ver. 2.15, the first version of Gerrit where we officially say “we officially support NoteDb and we encourage you to migrate away from ReviewDb.”
2018 We are going to release Gerrit Ver. 3.0 and Ver. 3.1. The reason for the name ‘3.0’ is because we will not have ReviewDb anymore. There will still be the code and the ability to migrate from ReviewDb to NoteDb, but you would not be able to run Gerrit on ReviewDb. The Ver. 3.1 is the one I am most excited about because in that version we do not have even to support a migration tool. We will then be able to throw away all the ReviewDb code, and that would make me very happy.
How to migrate from ReviewDb to NoteDb
I mentioned that migration for googlesource.com took us a very long time because we’ve found a ton of issues with our data. We discovered all these things while we were running our migration and we fixed them all.
We developed a system that was scanning all ReviewDb, performed an in-memory migration and then compared the result with the changes stored in NoteDb. One example of a bug was that some subjects were truncated in ReviewDb. The subject is supposed to come from the first line of the commit message. We were comparing the data in Git with the data in ReviewDb and they did not match because they were truncated. If we were to require that all the subjects in NoteDb were identical to the ones in ReviewDb we would have never passed because there was this truncation. We could have patched all the existing data but actually what we did is to consider that if the subject in NoteDb starts with the subject in ReviewDb it was then regarded as valid. There were many more bugs of that flavor.
There were also bugs in the NoteDb code that we fixed; it was not just like all related to not good data; my code was far from being bug-free. The reason why I am talking about how much effort we put in making it right is that I want you to feel confident and not think about that this is a so much scary operation on your data. We tested on ourselves, and we fixed a lot of these bugs, and we are still pretty confident that this is a safe operation.
In Ver. 2.15 there are two types of migration options: on-line and off-line. At Google, we are in an exceptional condition because we are always at zero downtime, but that was useful because it allowed us to write a tool for a live migration from ReviewDb to NoteDb while the server is running.
Migration to NoteDb is pretty much similar to the way you do reindex: there is an online reindex and an offline reindex. You can choose to do it offline, and it will be probably faster, but there will be a downtime. Or you can decide to do it online, and it will be slower, but there will be no downtime.
And then in Ver. 3.0 we only are going to support an off-line migration, following the same paradigm of all the other schema upgrades. If you skip between releases, we force you to do to an off-line update, but if you upgrade just one point release at a time, you don’t have to have any downtime for your schema migration. Similarly for NoteDb if you migrate from Ver. 2.14 to Ver. 2.15 and then Ver. 3.0, you won’t have any downtime.
Q: (Han-Wen) Is this process parallel?
A: It is parallel if you do it offline if you do it online it is using a single thread because we are assuming that your server is mostly busy doing other stuff and that’s why you may want to do an online migration in the first place.
Benefits of migrating to NoteDb
There are a lot of incentives to migration to NoteDb; one is that you have new features such as hashtags and others that we implemented only in NoteDb because they were a lot harder in ReviewDb such as the history of all reviewers on a change. NoteDb manages audit natively while on ReviewDb we would have needed to have a new table called reviewers_audit which would have been much harder to implement.
The robot comments introduced in Ver. 2.14, the ability to remove clutter in your dashboard to mark a change as reviewed, are all features that you only have in NoteDb.
What did we learn from migration to NoteDb?
Writing every single line of code just takes a long time, and Gerrit has hundreds of thousands of lines of code. Shawn Pearce, my manager, and the Gerrit project founder at Google, every time he needs to touch NoteDb related code just says “I don’t even recognize this, ” and he is still the contributor #1 in the project. We changed it almost beyond its recognition.
Everything I’ve said so far is about changes; there are also other data besides changes. Accounts have been unconditionally migrated to NoteDb in Ver. 2.15. Is more a git config file format for the accounts that we store in NoteDb, it is not even actually a Note-space format. The account is now a config file that has your name and your e-mail address and the status, which is a new feature in NoteDb. For instance, my account status says that “I having a talk in England”.
New Patch-set comparison
Hi, my name is Alice Kober-Sotzek, and I work at Google. In Ver. 2.15 we have changed the way we compared patch-sets. Let’s imagine we have just a small change with a patchset and two files on it. In the first file we have only the first line modified, and the file consists of one thousand lines. The second file has four lines changed.
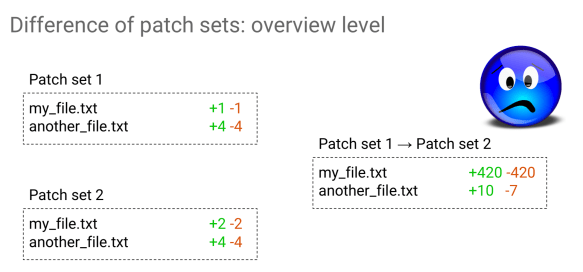
Let’s see what happens now when I rebased it to the latest version of master. If I had now to visualize what the patchset 1 consisted of and patchset 2 consisted of, what would I assume it would be? If I had been the author of the change, I would have expected that only one line would have been changed. Let’s just do it and ask Gerrit Ver. 2.14 what the result is.
What’s happening? Why do I have 420 lines changed in my file and ten additions and seven removals on the other?
That was not even touched on. Let’s have a look at the content of my file and what is in there.
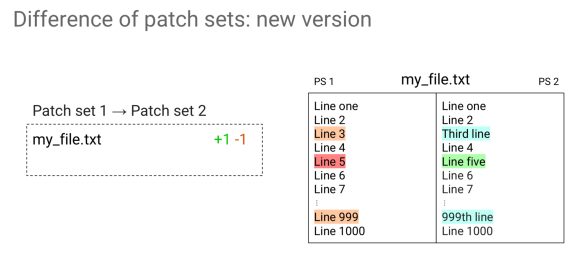
In Ver. 2.14 we were just hiding all the differences due to rebasing, and that was it. In Ver. 2.15 things look different though because we try to figure out what happened in between the rebase. All the hanks that we are sure are added by something else, are displayed in a different color. We have not only red and green but orange and blue as well; these are all the ones that were introduced by other changes that were in between rebase.
This feature only works in PolyGerrit, while in GWT was not shown at all.
Can I rely on that and trust what I see there?
The decision we made is that all the hunks marked with orange and blue are the ones we are sure of and you can safely avoid looking at them because they were the ones that happened because of other changes occurring in between rebase.
The ones marked with red and green, we give no guarantee. They could be introduced by other changes, because of conflicts or may be added by the patchset. With that coloring, it is much easier to look at the things that are important.
Killing Draft Changes.
Some of the people think that draft changes are very much a visibility thing so that only my reviewers can see them. Other people use it like a change is not yet ready for review so that I can leave it as draft change until it is ready for being reviewed. You may even just use the server as a store for your changes; rework the code through the Gerrit in-line edit feature until the code is ready and then come up with an absurd number of patchsets. Nobody wanted any of them, but those are the conditions that we ended up with patchset drafts.
Patchsets could have been even deleted so they would never exist. They could just be kept invisible so that you see a gap, but that could be the current patchset: the UI claims that the current patchset is three, but then I do some other operations that say that this patchset is not current anymore, just because the current one is a draft!
Drafts are a kind of mass fraud; the main reason is that they are colliding all these things into a single feature. In Gerrit Ver. 2.15 we killed drafts. Now you have little small features instead of drafts. You have now “Private Changes” which only you and your reviewers can see. There are Work-In-Progress (WIP) changes, that means that while the WIP flag is set nobody gets notifications about it: you can push 30 patchsets, and the reviewers would not get spammed with 30 emails. Last but not least, we introduced a long ago the Change Edit, which can be used as well in conjunction with WIP Changes.
Marking Changes as reviewed
Another thing that we introduced in Ver. 2.15 is the ability to mark changes as you reviewed it. For instance, the one below is a change screen from my dashboard this morning: some changes are highlighted in bold and those other changes are not. I feel like the bold changes are yelling at me and you have to give me your attention just like in e-mails where bolds means “you need to look at me now.” Gerrit Ver. 2.15 when you are using NoteDb allows you to unbold any of them by just clicking a button on the change screen. Or like in an email you wish to remove some changes from your dashboard entirely. There is a function that allows you remove a change unilaterally from your dashboard that the other cannot undo or ignore it, that just makes the change go away.
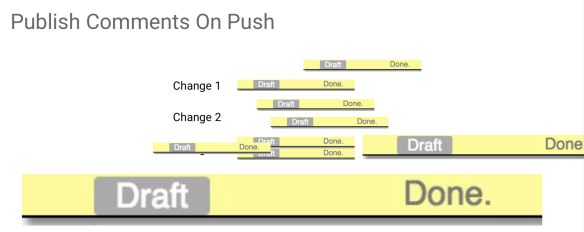
It was annoying that I could not mark them as reviewed manually and it was really irritating that patchsets disappeared. It is really irritating when I received a review with a bunch of comments, I had to say “done, done, done, done” on each one of them.
And then when I pushed a new patchset, I just forgot to submit all these drafts comments that say “done”. So I added just a push option that says “when you push, publish comments” and all the draft comments will be published automatically. So instead of clicking on all the patchset on that change and check if in any of the patchset I have any draft and if I do, click send on all of them one by one, I can instead just set an option.
It can be specified by the command line, but it is difficult to remember. So there is a user preference with a checkbox which I really encourage you to select in your user preferences screen and it is only available on PolyGerrit.
CCing a Change under review
When someone is getting a co-worker and they want him to be a reviewer for a change, you get an error saying that your co-worker is not a registered user. We have partially solved this problem by adding a CC with an e-mail address, also only available on NoteDb. There are technical and even product reasons why we don’t want to add them as a reviewer, some of them are related to the accountability related to everyone that is working on that change. So people needs to have an account to be a reviewer, but if people just want to look at it or a mailing list, it doesn’t have to be a real user, you can then just CC any e-mail to a code review if you turn the config option to allow this.
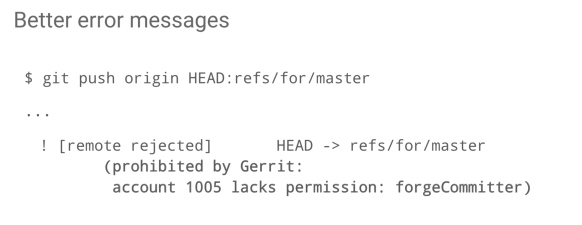
Better error messages.
Another inch that Han-Wen scratched was the introduction of better error messages. Sometimes you do a push, and it fails with a very unhelpful error message that says “Prohibited by Gerrit.”
It turns out that it is not difficult to check if a user does not have a permission then gives permissions error, so we have included a message saying this user lacks this permission. It is not perfect, so it doesn’t say precisely where in the project hierarchy this permission was coming from but at least says “this is the problem”, it tells you not the solution but at least highlights where the problem is.
Robot comments and automatic fixes.
Robot comments are a feature that we believe it will start to rump up in adoption. With NoteDb, you can suggest fixes as well, and then you have a button that says “apply fixes” which creates a change that applies the fixes.
Many more improvements in the bag.
There is a lot of speed improvements in PolyGerrit, so the changes with a lot of diffs will run a lot faster. An admin can delete comments that really shouldn’t be there. We can explicitly keep track that a change reverts another change so that you can search if that change was reverted. It can even tell you if that was a pure revert at Git level only, or if other changes were sneaked in claiming that this was only a revert which happens way too often I think.
There are a better server consistency checks and a new plugin endpoint for dashboards; there is a new URL scheme as described by Patrick and we are now off the page for putting, even more, new features.
The fourth talk of the Gerrit User Summit 2017 edition is Zoekt, an improved fast and secure Code Search engine made by Han-Wen at Google.
One year after its inception, the search engine supports now Unicode v2.0 and is fully integrated with Gerrit ACLs, ready to be used with large enterprise installations.
Say hello to Zoekt, the fast source code search
My name is Han-Wen, I’ve been writing a new source code search engine called Zoekt.
Here is the home page of the search engine and you can see that I am not a Web UI person 🙂
It is running on the public internet on the website hosted by my friends of the Bazel Team.
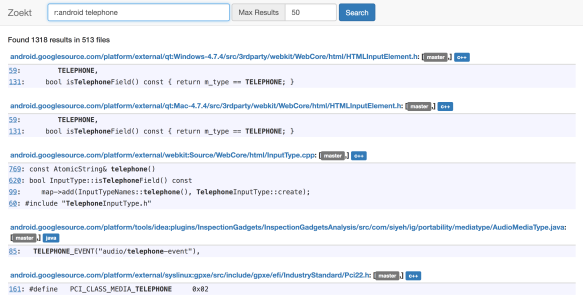
It has a bunch of source code indexed, about 30 GB, which is mostly Google source code. You can search through the Android source code project for things that match “telephone” and get lots of results associated.
Linus Torvalds created the Linux operating system and, as we all know, he has not a very diplomatic use of language. If you want to know where he says “crazy idiot” you can find it in just under 9 milliseconds!
Zoekt is super fast and is OpenSource. You can run it on your server or your laptop, but if you want just to check it out, you can go to this URL: https://cs.bazel.build.
Why I did this?
I work at Google, and I spend most of my time looking at others’ code and trying to understand what is doing. Frequently I have to dig into code that I don’t know, and I have not necessarily have checked out locally. I use the Google internal code search for that, and I missed it when I started to work on Gerrit. Then I thought: “I can fix that, I can just do it on my own.”
Last year I announced this search code site running on the Bazel site and was a kind of the first instance. I have been running it for one year, finding a lot of bugs and things that could break and developed many improvements and I am going to show you some of them today.
The core of a search engine for code is an engine that can find substrings in a large file of text. They can be arbitrary substrings, and most of the code search engine like to search for words. However, if you take the last char of the word away, e.g. you are not looking for “crazy idiot” but only for “craz idiot”, most search engines like ElasticSearch of GitHub won’t find any match.
ASCII vs. Unicode
Zoekt works, but the implementation was initially based on the idea that everything is ASCII and then any char is one byte. In reality, a lot of text is not just ASCII and, maybe, someone from Sweden has the strange “A” with the circle on top. The character is then is no longer ASCII, and you can’t search for any of their names. That is a bummer, and then I thought “well, it kinda works, but it doesn’t really work”. The regex engine uses Unicode for searching, and that leads to bugs, that means things are right there, but you can’t find them.
That happens surprisingly often like, for example, the source code of this project which has Unicode characters because it has some tests about Unicode. Finally, this is just a bug, and to me, this is pretty much like the mountain Everest.
Why do people climb mountain Everest?Because it is there. And why I wanted to fix this bug? Because the bug was there.
Triagrams
Before you can understand what the bug is, you need to understand what Unicode is and how it works so that you can understand why the code was not working before.
The basic idea of code searching is that you build an additional data structure that helps you find things in a large chunk of text.
For example, we have two files, one contains the word “code” and the other contains the word “model”. What we do is split it out into two sequences of three characters, and we record the offsets of each of those group of threes: we call them triagrams. Then we create an index of the triagrams and the associated offsets. If you want to look for “temp 50C max”, you take the first group of three characters which is “tem” and the last group which is “max”. Then you look for this with exactly the distance of 10 characters apart, because with this data structure over here we can do this very efficiently.
So we are looking for the characters “tem” and in the data structure over here we should find something that matches “tem” and you only have to look at one row over here and may to another one row over there. Finding if a string is not there is very quick and, if the string is there, these offsets will give you the position for a real string search.
In practice, you always want to look for things disregarding case. In this case, if you ‘re going to do it case insensitively you can generate all the different flavor of cases, for the first and the last triagram, and then you can do the same strategy again.
What about Unicode?
Unicode, in essence, is a mapping from numbers to meanings, for example, the Unicode number 24991 is the Chinese character “Wen” which is part of my name. So, it is a huge book which is a sequence of numbers mapped to a list of different characters.
The predecessor was ASCII in 1963 where you find the common characters like “abcd”. In 1988 Unicode Ver. 1.0 introduced a space for 65 thousand characters; the people that invented it were not too familiar with Asian languages because it turns out that you can fill a lot of Chinese and Japanese into that but if you want to have all the characters it is a little bit tight on space. In 1996, Unicode Ver. 2.0 introduced a 21-bit space with the ability to represent up to 2 millions of characters, including as well this Egyptian character and the “poo” emoji.
UTF-8 encoding
It is important to remember that Unicode is merely a book of numbers and their associated characters. It doesn’t say anything on how you store this data and that is why you need an encoding format. There are different encodings, but the one that has won is UTF-8. It uses a scheme where the ASCII characters have a first 0 bit at the beginning and then 7 bit of data. If you have a character that needs more space, you start using multiple bytes for its representation.
The advantage of this approach is that ASCII stays ASCII. It is nice because the reality most strings are effectively ASCII and then remain ASCII which is a space saving. The disadvantage is that characters can occupy a variable amount of space; if you want to index them you don’t know where the characters start anymore. For most indexing, this is not a big problem, but unfortunately for code search, it is.
Why bother? We can still just make trigrams out of Unicode characters and look for their indexes. This kind of works, except that there a catch. Suppose that you are not searching for the temperature of 50 Celsius max, but you are searching for 323 Kelvin max. So if you are using Unicode, you could be looking for the lowercase k the capital K or Unicode symbol 212A which is the symbol for Kelvin degrees. It turns out that the Kelvin symbol takes 3 bytes, and so if I am looking for the string over here I want to look for “tem” and “max” but what distance do I pick? Because if someone is using Kelvin in Unicode, the distance is 12 but if I use K the distance is 10. The scheme isn’t working anymore.
I changed the triagrams to work with Unicode. I have used 64bit, and the three times 21-bit is 63 which fits nicely and works efficiently for all the offsets regarding Unicode code points.
So if we take the example earlier, we have Egyptian character and the “poo” emoji. So you can still search using this table over here, you can find where concerning Unicode code points the string is. If you want to use the actual comparison you need to find the offset in the file in bytes so that you can start making the real string comparison. So we have an extra table with the offsets with the mapping between the Unicode code points and the corresponding bytes offsets. You can see that the codepoint at offset number 6 is at byte 9, and so, it works!
Zoekt hosted by the Bazel project
I’ve put this on a machine that is hosted by the Bazel project, so it runs on the Google Cloud infrastructure on https://cs.bazel.build. As I work at Google, this is also nice because I can understand what customers go through when they want to use our products. Deploying is always good because when you need to start using your software for real, you then find the actual bugs and the real issues.
Code Search and Security
Of course, Google is a company that takes security and privacy seriously. Zoekt is a project that I do for fun, spending a couple of hours of free hacking time once a week and I don’t want to have any trouble with security.
One way to get into trouble is to set Cookies on your site, and then you’re subject to various laws in various countries, multiple lawyers will talk to me, and I don’t want that.
Another way to get into trouble is to have a security breach. If you do something that compromises the machine and opens it up to bad people, bad people to bad things with it and then other people from Google come to me and make my life difficult, and I don’t want that. Does anybody recognize this image? As a cultural reference, this is an image from “The Matrix Reloaded” where Trinity uses an existing exploit from SSH to access to the power grid of The Matrix. One of my personal goals is also to not be in any movie where the bad guys try to get in: don’t be implicated with bad guys in the film.
Threat model
What do I have that people want to steal from me? In case of a code search engine, if you’d be indexing private code and someone would want to leak that code; in this case this is not a problem since I am indexing Open Source code, so it is all public.
There is an SSL key to keep the traffic going securely so if someone steals that key and can make a man-in-the-middle attack and show source code that subtly different from the real thing and how bad would that be? In my case, this is not a problem because the Google Infrastructure provides the load balancing. You upload your private key into the load balancer, and then the only way to compromise it is hacking your Google account which is very well protected.
There is an access token needed to get the code into the indexing machine for processing. In my case is a GitHub public token, so it is not a big deal if it is getting lost, but possibly Google will get very upset with me if that is getting misused.
Finally, if you can get access to the machine, you can do any of the above. You can use it for other attacks, to mine bitcoins and to do many different bad things. Again, I don’t want these things happening because people come and speak to me, talk to my manager and I don’t want bad things happening to me because of a project that I do for fun.
So, how would you get into such a system? The search engine itself is written in Go, which is a memory-safe language. The worst thing you could do is to make it crash and then it gets restarted again. So no big deal. But there is one part of the search engine that is important which is the thing that provides symbols. When you are looking for something you typically want to have the definition of a symbol. I am using a problem called ‘ctags’ for that, and this is a problem written in C that parses lots of languages. It understands where the identifiers definition are so that I can get better search results.
But CTags is written in C and if someone would have control to the source code that I am indexing could create source code that looks suspicious and maybe exploit some error in this hundred of thousands of lines of C code.
For example, the ANSI C standard says that identifiers can be at most 32 chars. I hope they didn’t do it but suppose that CTags used a fixed buffer size for that and someone creates a commit that introduces this variable that overflows a buffer. Then it may overflow the buffer and try to dial a four pin number: that would be bad.
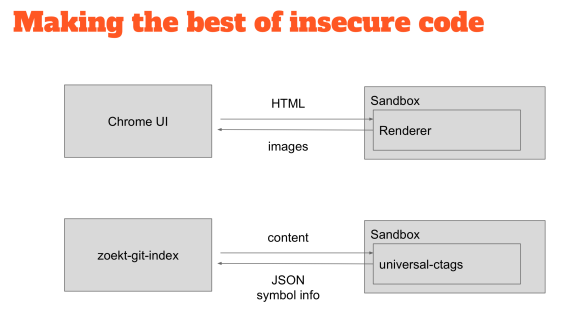
So how do you deal with that? You can take inspiration from other projects, which have the same problem, so Chrome, for example, is one of the most secure browsers out there because it uses sandboxing. So the part that renders HTML which is entirely untrusted is put inside sandbox where they can do almost no damage.
If you find a problem in the renderer that you can exploit, then you’ll find yourself in a place where you cannot do any damage. I have used the same technique for the indexer. I run the untrusted binaries inside the sandbox, I ship the content to the CTags binary, and the CTags binary responds with JSON containing the symbol definitions.
It uses seccomp which is available only on Linux. You start the program by declaring what system calls it can do, allocating the memory, providing the input and you then get the output. When you exit there is as well a system call that, if you can forget to exit from the process, it will automatically kill the sandbox. All of the above is all done by seccomp.
As you can see in this picture, I am now peacefully sleeping because everyone is secure and I don’t have to worry about anything anymore.
Gerrit ACLs
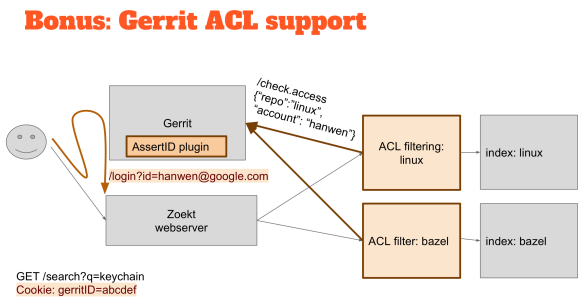
We had a hackathon yesterday, and I have thinking about this idea for a while, and I thought that I would have to go to tackle the Gerrit ACLs integration during those days. The overall ACL model in Gerrit is very sophisticated, so the only way to understand if someone can read a piece of source code is just to ask Gerrit “can this person see this source code?” A component of the solution is an ACL filter in the middle when you contact a web server to search something you typically start on the Web server and then it looks at all the different indexes to ask for a search result.
For the Gerrit support, I’ve put something in the middle that if you want to search for the code, it asks Gerrit if that person has permissions to read that code and to be able to execute the search. If the person doesn’t have the permissions, you just don’t return any result.
Gerrit SSO
So how do you know who the person is? I added some HTML magic that in case you don’t have a specific cookie you go to Gerrit and there is a little plugin that redirects back to the web server. So the plugin knows who you are on the Gerrit domain and using a redirect can tell the Web server your identity.
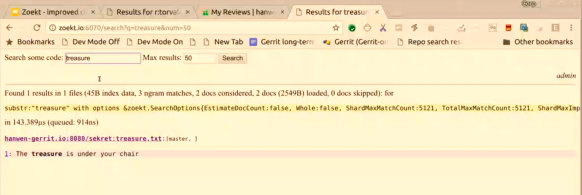
I am the administrator in Gerrit, as you can see over there on the top, and so if I go to Zoekt, then you can see in the corner that I am an Administrator there as well. That goes very quickly because now runs locally, but in reality, it does a redirect to Gerrit, and then Gerrit sends a redirect back to Zoekt.
If I want to search for things, I can find results in the “secret” repository. So if I now were to log out from Gerrit, there is another redirect to make sure that I am also logged out from the Zoekt, and now if I try to access the search engine I got “how no, who are you?” you have to authenticate.
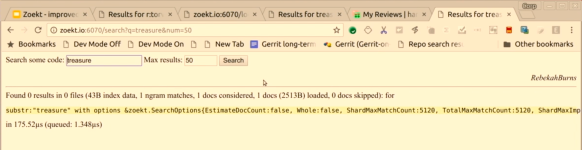
I can now become another person, logging in as Rebecca; looking at Zoekt, I am Rebecca as well. If I try now to search for the treasure in the “secret” repository, hopefully, it doesn’t work: so “no results” right?
That is how ACL support could work, regarding the overall idea on how to make this work, the piece that goes from here to there was a little bit complicated, but I think it is a decent idea. The plugin in Gerrit that does this redirect is quite hacky, and in a real deployment, you have to integrate to whatever authentication system people have on site.
I don’t know how LDAP works and so if anyone is interested in this and wants to have this, and there to make it work but then need some help on how to integrate with external authentication providers.
Questions
Q: (Martin Fick – Qualcomm) How do you envision this working by knowing Projects and Branches that users can use and be doing in a performant way in case they can’t read most of the information on the server?
A: The ACL filtering can cache that information, and my idea is that all pre-loading of ACLs can be cached to whether the user has access to it or not.
Q: So only at the repository level? Not at the branch level?
A: So this check access endpoint, I added it because we had people misconfiguring their Gerrit server leading to confidential data being leaked. People should test this so I made it so that people can pre-verify that people had no access to it has support for branches as well, but that part has been left off the slides though.
Q: So from a performance standpoint. Suppose you have a large amount of stuff you can’t see, would you be taking into account what you is authorized to see before you run the query?
A: Yes, it happens before the query goes into the index. So if the person has no access to it, you skip the search for the piece of data that person has no access to it.
Q: So if on the other side they have access to a lot of things and a lot of refs, then the filtering may be slow on the frontend.
A: Wow, this is basically what I have implemented in two days. Real life tests would be helpful. I would love people to try out and tell me how well it performs, so, let me know.
Q: So, does that mean that index is done once and access control is done afterward. So that indexing is not dependant on the access.
A: The indexing is usually done off-line on a cronjob because it generates a lot of data. The entire point of the indexing is to make the online search queries very fast and not doing the indexing when the person is looking for the document.