Slow Git isn’t just annoying – it’s expensive for everyone: developers wait for a CI/CD validation of their changes, SCM admins are wasting their time in fire-fighting SCM slowdown and broken pipelines, IT managers are wasting millions of dollars in CPU and Disk hosting costs.What if your Git operations could be up to 100x faster, and keep up with the new AI-vibe coding landslide of PR and changes?
100x Faster Git, Powered by AI
GHS is an AI-based accelerator for Git SCM that redefines performance:
Up to 100x faster clones and fetches.
CI/CD pipelines that run without SCM barriers.
Adapt automatically to your repository shape and make it faster.
Scale without slowdown even under heavy loads
This isn’t traditional “tuning.” GHS learns your repos and access patterns, then continuously optimises them so your Git server is always running at maximum speed.
How Does GHS Deliver 100x Faster Git?
Measure Everything It collects detailed metrics in realtime on your repositories.
Spot Bottlenecks GHS AI model is trained on recognizing the bottlenecks and take immediate action, before they become a problem
Stay Fast Your Git stays consistently accelerated, not just temporarily boosted.
Why Speed Matters
Developers stop wasting hours on slow fetches and builds.
Release managers push features out faster.
IT leaders reduce infra costs by doing more with less.
Admins no longer fire-fight performance issues.
Every 1% of time saved in Git can add up to days of productivity across a large team. Imagine saving 100x that.
Who Needs 100x Faster Git?
Repositories of all sizes: AI-driven code generation and “vibe-coding” have dramatically accelerated the pace of software delivery.
Enterprises that have adopted the AI-pipeline want that value delivered faster to production.
Any team frustrated with slow CI/CD pipelines.
The GHS Advantage
Transformative speed: not just 2x or 5x faster, but up to 100x
SCM expertise: GerritForge’s decades of enterprise SCM know-how built in.
Proven reliability: Stability and uptime as performance scales.
Get Started Today
You can try GHS free for 30 days and experience the difference for yourself.
First, a huge thank you to the OpenInfra Foundation for hosting this event in Paris. Their invitation to have the Gerrit User Summit join the rest of the community set the stage for a truly collaborative and impactful gathering.
Paris last weekend wasn’t just a conference; it was a reunion. Fourteen years after the last GitTogether at Google’s Mountain View HQ, the “Git and Gerrit, together again” spirit was electric.
On October 18-19, luminaries from the early days (Scott, Martin, Luca, and many others) reconvened, sharing the floor with the new generation of innovators. The atmosphere was intense, filled with the same collaborative energy of 2011, but focused on a new set of challenges. The core question: how to evolve Git and Gerrit for the next decade of software development, a future dominated by AI, massive scale, and an urgent demand for smarter workflows.
Here are the key dispatches from the summit floor.
A Historic Reunion, A Shared Future
This event was a powerful reminder that the open-source spirit of cross-pollination is alive and well. The discussions were invigorated by the “fresh air” from new-school tools like GitButler and Jujutsu (JJ), which are fundamentally rethinking the developer experience.
In a significant show of industry-wide collaboration, we were delighted to have GitLab actively participating. Patrick’s technical presentation on the status of reftable was a highlight, but his engagement in discussions on collaborative solutions moving forward with the Gerrit community truly set the tone. It’s clear that the challenges ahead are shared by all platforms, and the solutions will be too.
Scaling Git in the Age of AI
The central theme was scale. In this rapidly accelerating AI era, software repositories are growing at an unprecedented rate across all platforms—Gerrit, GitHub, and GitLab alike. This isn’t a linear increase; it’s an explosion, and it’s pushing SCM systems to their breaking point.
The consensus was clear: traditional vertical and horizontal scaling is no longer enough. The community is now in a race to explore new techniques—from the metal up—to improve performance, slash memory usage, and make core Git operations efficient at a scale we’ve never seen before. This summit was a rare chance for maintainers from different ecosystems to align on these shared problems and forge collaborative paths to solutions.
Dispatches from the Front Lines: NVIDIA and Qualcomm
This challenge isn’t theoretical. We heard powerful testimonials from industry giants NVIDIA and Qualcomm, who are on the front lines of the AI revolution.
They shared fascinating and sobering insights into the repository explosion they are actively managing. Their AI workflows—encompassing massive datasets, huge model binaries, and unprecedented CI/CD activity—are generating data on a scale that is stressing even the most robust SCM systems. Their presentations detailed the unique challenges and innovative approaches they are pioneering to tackle this data gravity, providing invaluable real-world context that fueled the summit’s technical deep dives.
Beyond the Pull Request: The Quest for a ‘Commit-First’ World
One of the most passionate debates centered on the developer workflow itself. The wider Git community increasingly recognizes that the traditional, monolithic “pull request” model is ill-suited to the “change-focused” code review that platforms like Gerrit have championed for years.
The benefits of a change-based workflow, cleaner history, better hygiene, and higher-quality atomic changes—are driving a growing interest in standardizing a persistent Change-ID for each commit. This would make structured, atomic reviews a first-class citizen in Git itself. The collaboration at the summit between the Gerrit community, GitButler, JJ, and other Git contributors on defining this standard was a major breakthrough.
This shift is being powered by tools like GitButler and JJ, which are built on a core philosophy: Workflow Over Plumbing. Modifying commits, rebasing, and resolving conflicts remain intimidating hurdles for many developers. The Git command line can be complex and unintuitive. These new tools abstract that complexity away, guiding users through commit management in a way that feels natural. The result is faster iteration, higher confidence, and a far better developer experience.
AI and the Evolving Craft of Code Review
Finally, no technical summit in 2025 would be complete without a deep dive into AI. The arrival of AI-assisted coding is fundamentally shifting the dynamic between author and reviewer.
Engineers at the summit expressed a cautious optimism. On one hand, AI is a powerful tool to accelerate reviews, improve consistency, and bolster safety. On the other, everyone is aware of the trade-offs. Carelessly used, AI-generated code can weaken knowledge sharing, blur IP boundaries, and erode a team’s deep, institutional understanding of its own codebase.
The challenge going forward is not to replace the human in the loop, but to strengthen the craft of collaborative review by integrating AI as a true co-pilot.
A Path to 100x Scale: The GHS Initiative
The most forward-looking discussions at the summit centered on how to achieve the massive scale required. One of the most promising solutions presented was GHS (Git-at-High-Speed). This innovative approach is not just an incremental improvement; it’s a strategic initiative designed to increase SCM throughput by as much as 100x.
The project’s vision is to enable platforms like Gerrit, GitLab, and GitHub Enterprise to handle the explosive repository growth and build traffic generated by modern AI workflows. By re-architecting key components for hyper-scalability, GHS represents a concrete path forward, ensuring that the industry’s most critical SCMs can meet the unprecedented demands of the AI-driven future.
The Road from Paris
The Gerrit User Summit 2025 was more than a look back at the “glorious days.” It was a statement. The Git and Gerrit communities are unified, energized, and actively building the next generation of SCM. The spirit of GItTogether 2011 is back, but this time it’s armed with 14 years of experience and a clear-eyed view of the challenges and opportunities ahead.
(TL;DR) The Gerrit Code Review project has an ambitious roadmap for 2025 and beyond. Gerrit 3.12 (H1 2025) will focus on JGit performance improvements, X.509 signed commit support, and enhanced Owners and Analytics plugins. Gerrit 3.13 (H2 2025) aims to further optimize push performance, UI usability, and plugin updates, including Kafka and Zookeeper integrations.
The k8s-Gerrit initiative will improve Gerrit’s deployment on Kubernetes, ensuring better scalability and resilience. Looking ahead, Gerrit 4.0 (2026/2027) plans to decouple the review UI from the JGit server, enabling alternative review interfaces and improved flexibility.
The development team is prioritizing significant performance enhancements in JGit, the Java implementation of Git used by Gerrit. Key objectives include:
Speeding Up Conflicting Ref Names on Push: This aims to reduce delays during push operations when ref name conflicts occur.
Enhancing SearchForReuse Latency for Large Monorepos: The goal is to improve latency by at least an order of magnitude, facilitating more efficient operations in extensive monorepositories.
Improving Object Lookup Across Multiple Packfiles: Efforts are underway to accelerate object lookup times by at least tenfold, enhancing performance in repositories with numerous packfiles.
Parallelizing Bitmap Generation: By enabling bitmap generation across multiple cores, the team aims to expedite this process, contributing to overall performance gains.
Gerrit Core Experience Enhancements
A notable feature planned for this release is the support for X.509 signed commits, which will bolster security and authenticity in the code review process.
Owners Plugin Improvements
Enhancements to the Owners Plugin are set to provide clearer insights and streamlined interactions:
Action Requirements Display: Explicitly showing required actions by each owner at the file level.
Detailed Pending Reviews: Offering more comprehensive information on pending reviews by owners.
Easier Contact with File Owners: Facilitating more straightforward communication with file owners.
Analytics Plugin Optimization
The analytics plugin is slated for improvements to enhance speed and usability:
Repo Manifest Discovery: Native support for discovering repository manifests.
Faster Metrics Extraction: Accelerated extraction of metrics for branches, aiding in quicker data analysis.
Gerrit 3.13 (Target: H2 2025)
JGit Performance and Concurrency Enhancements
Building upon previous improvements, version 3.13 aims to further optimize performance:
Optional Connectivity and Collision Checks: Improving push performance by allowing the skipping of certain checks when appropriate.
Customizable Lock-Interval Retries: Providing flexibility in managing lock intervals to enhance concurrency handling.
Read-Only Multi-Pack Index Support: Introducing support for read-only multi-pack indexes to improve repository access efficiency.
Gerrit Core and UI Experience Enhancements
User experience remains a focal point with planned features such as:
File List Filtering: Allowing users to filter the file list in the change review screen for more efficient navigation.
Headless Gerrit Packaging: Offering a version of Gerrit that serves only read/write Git protocols, catering to users seeking a streamlined experience.
Plugin Updates
The roadmap includes updates to key plugins:
Kafka Events-Broker: Upgrading to support Kafka 3.9.0, enhancing event handling capabilities.
Zookeeper Global-Refdb: Updating to support Zookeeper 3.9.3, improving global reference database management.
Replication Plugin Enhancements
Efforts to simplify configuration and improve performance include:
Dynamic Endpoint Management: Introducing APIs for creating and updating replication endpoints dynamically.
UI Integration: Displaying replication status within the user interface for better visibility.
Reduced Latency on Force-Push: Improving replication latency during force-push operations by applying objects with prerequisites.
k8s-Gerrit
The k8s-Gerrit initiative focuses on deploying Gerrit within Kubernetes environments, aiming to enhance scalability, resilience, and ease of management. This approach leverages Kubernetes’ orchestration capabilities to provide automated deployment, scaling, and management of Gerrit instances, facilitating more efficient resource utilization and operational consistency.
Gerrit 4.0 (Target: 2026/2027)
Looking ahead, Gerrit 4.0 is set to introduce significant architectural changes:
Decoupling Gerrit Review UI and JGit Server: This separation will allow the Gerrit UI and JGit server to operate as independent services, providing greater flexibility in deployment and scaling.
Enabling Alternative Review UIs: By decoupling components, the platform will support the integration of other review interfaces, such as pull-request systems, offering users a broader range of tools tailored to their workflows.
The Gerrit community is encouraged to stay engaged with these developments, as the roadmap is subject to change. Contributors planning to work on features not listed are advised to inform the Engineering Steering Committee (ESC) to ensure alignment with the project’s goals.
GerritForge has confirmed over 2023 its commitment to the Gerrit Code Review platforming, helping deliver two major releases: Gerrit v3.8 and v3.9.
The major contributions combined are focused on the plugins for extending the reach of the Gerrit platform, first and foremost the pull-replication and multi-site, as shown by the split of the 853 contributions across the projects, weighted by the number of changes and average modifications per change.
Pull replication plugin This is where GerritForge excelled in providing an unprecedented level of performance over anything that has been built so far in terms of Git replication for Gerrit. Roughly one-third of the Team efforts have contributed to the pull replication plugin, which provided over 2022/23 a 1000x speedup factor compared to Gerrit tradition factor. GerritForge has further improved its stability, resilience and self-healing capabilities thanks to a fully distributed and pluggable message broker system.
Gerrit v3.8 and v3.9 GerritForge helped release two major versions of Gerrit Code Review, contributing noteworthy features like Java 17 support, cross-plugin communication, importing of projects across instances and the migration to Bazel 7.
Owners plugin Jacek has completely revamped the engine of the owners plugin, boosting it with an unprecedented level of performance, hundreds of times faster than in the previous release, and bringing it to the modernity of submit requirements without the need to write any Prolog rules.
Multi-site plugin The whole team helped provide more stability and bug fixes across multiple versions of Gerrit, from v3.4 up to the latest v3.9.
JGit GerritForge kept its promises in stepping up its efforts in getting important fixes merged, including the optimisation of the refs scanning in Git Protocol v2 and the fix for bitmap processing with incoming Git receive-pack concurrency that we promised to fix at the beginning of 2023.
Migration of Eclipse JGit/EGit to GerritHub.io
The 2023 has also seen a major improvement in GerritHub stability and availability, halving the total outage in a 12-month period from 19 to 10 minutes, with a total uptime of 99.998% (source: PIngdom.com)
The whole process was completed without any downtime and a reduced read-only window on the legacy Eclipse’s instance git.eclipse.org, which was needed because of the lack of multi-site support on the Eclipse side.
What we did achieve from our goals of 2023
JGit changes: we did merge 22 changes in 2023, most of them within the list of our targets for the year. One related to the packed-refs loading optimisation was abandoned (doesn’t get much traction from the rest of the community), and the last major one left is the priority queue refactoring still in progress on stable-6.6. Also, thanks to the migration of JGit/EGit to GerritHub.io, David Ostrovsky managed to get hold of its committer status and will now be able to provide more help in support in getting changes reviewed and merged.
JGit multi-pack index support: we did not have the bandwidth and focus to tackle this major improvement. The task is still open for anyone willing to help implement it.
Git repository optimiser: we kick-started the activity and researched the topic, with Ponch presenting the current status at the Gerrit User Summit 2023 in Sunnyvale CA.
Gerrit v3.8 and project-specific change numbers: the design document has been abandoned because of the need of rethinking its end-to-end user goals. However, we found and fixed many use cases where Gerrit wasn’t using the project/change-number pair for identifying changes, which is a pre-requisite for implementing any future project-specific change number use-case.
Gerrit Certified Binaries: the Platinum Enterprise Support for Gerrit has been enriched in 2023 with the certified binaries programme, with enhanced Gatling tests and E2E validation using AWS-Gerrit. Many bugs have been found and fixed in all the active versions of Gerrit; some of them were very critical and surprisingly undiscovered for months.
GerritForge Inc. revenue targets in the USA: the revenues increased by 50% in 2023, which was slightly below the initial expectations but still remarkable, despite the latest economic downturn of the past 12 months. 100% of the business has been transferred to the USA, including the GerritForge trademark and logo and we are now ready to start a new robust growth cycle in 2024 and beyond.
Looking at the future with AI in 2024
The recent economic news in the past 6 months has highlighted a difficult moment after the COVID-19 pandemic: the conjunction of the cost of living crisis, rising interest rates and two new major wars across the globe have pushed major tech companies to revise their small to medium-term growth figures, resulting in a series of waves of lay offs in the tech sector and beyond.
Whilst the layoffs are not immediately related to a lack of profitability of the companies involved, it highlights that in the medium term there will be a lot fewer engineers looking after the production systems across the company, including SCM.
SCM and Code Review are at the heart of the software lifecycle of tech companies and, therefore, represent the most critical part of the business that would need to be protected at all costs. GerritForge sees this change as a pivotal moment for stepping up its efforts in serving the community and helping companies to thrive with Gerrit and its Git SCM projects.
How do we maintain SCM stability with fewer people?
Gerrit Code Review has become more and more stable and reliable over the years, which should sound reassuring for all of those companies that are looking at a reduced staff and the challenge of keeping the lights on of the SCM. However, the major cause of disruption is represented by what is not linked to the SCM code but rather its data.
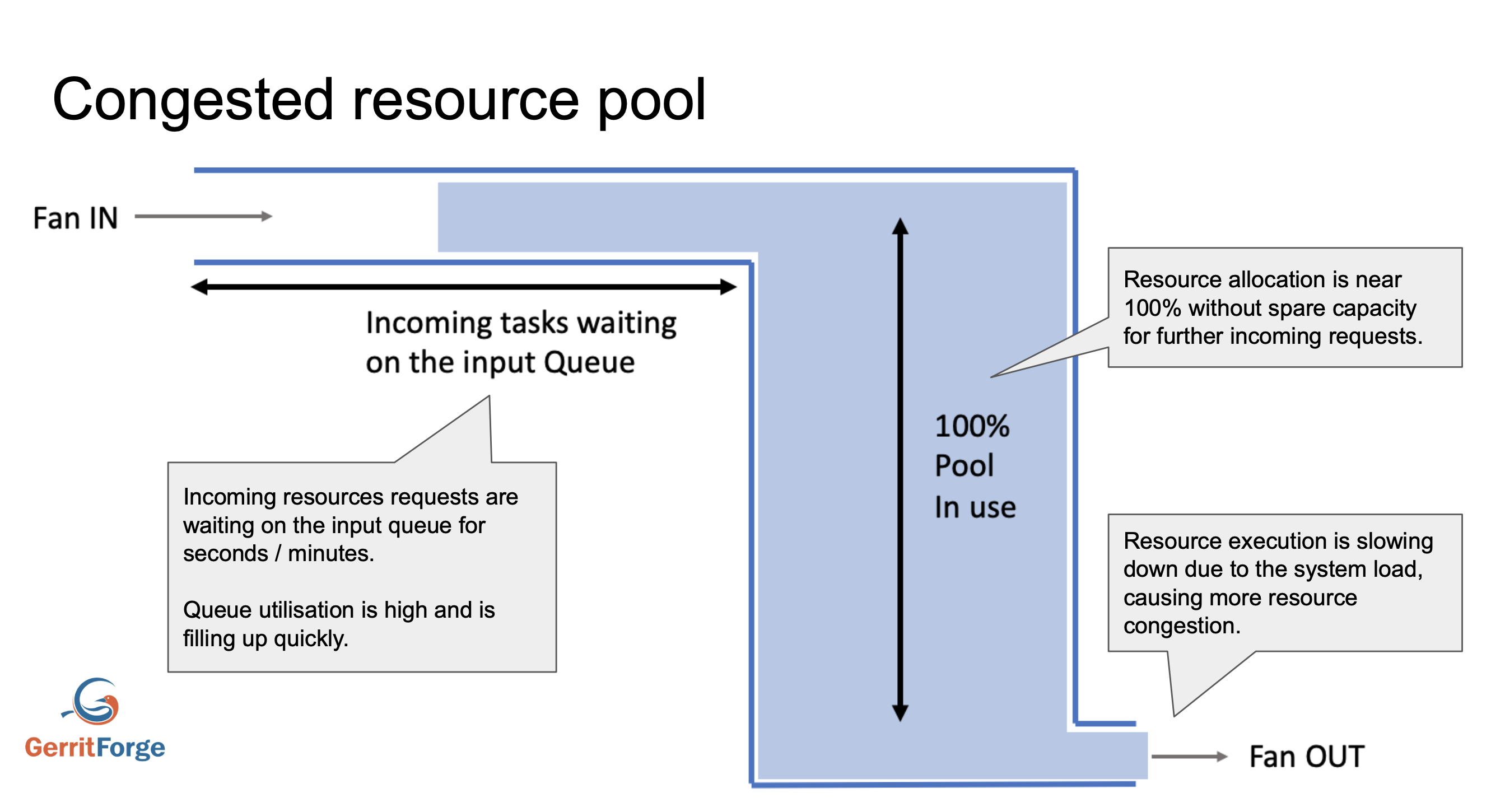
The Git repositories and their status are nowadays responsible for 80% of the stability issues with Gerrit and possibly with other Git servers as well. Imagine a system that is receiving a high rate of Git traffic (e.g. Git clone) of 100 operations per minute, and the system is able to cope thanks to a very optimised repository and bitmaps. However, things may change quickly and some of the user actions (e.g. a user performing a force-push on a feature branch) could invalidate the effectiveness of the Git bitmap and the server will start accumulating a backlog of traffic.
In a fully staffed team of SCM administrators and with all the necessary metrics and alerts in place, the above condition would trigger a specific alert that can be noticed, analysed, and actioned swiftly before anyone notices any service degradation.
However, when there is a shortage of Git SCM admins, the number of metrics and alerts to keep under control could be overwhelming, and the trade-offs could leave the system congestion classified as a lower-priority problem.
When a system congestion lasts too long, the incoming tasks queueing could reach its limits, and the users may start noticing issues. If the resource pools are too congested, the system could also start a catastrophic failure loop where the workload further reduces the fan out of the execution pool and causing soon a global outage.
The above condition is only one example of what could happen to a Git SCM system, but not the only one. There are many variables to take into account for preventing a system from failing; the knowledge and experience of managing them is embedded in the many of the engineers that are potentially laid off, with the potential of serious consequences for the tech companies.
GerritForge brings AI to the rescue of Git SCM stability
GerritForge has been active in the past 14 years in making the Git SCM system more suitable for enterprises from its very first inception: that’s the reason why this blog is named “GitEnterprise” after all.
We have been investing over 2022 and 2023 in analysing, gathering and exporting all the metrics of the Git repositories to the eyes and minds of the SCM administrators, thanks to open-source products like Git repo-metrics plugin. However, the recent economic downturn could leave all the knowledge and value of this data into a black hole if left in its current form.
When the work of analysing, monitoring and taking action on the data becomes too overwhelming for the size of the SCM Team left after the layoffs, there are other AI-based tools that can come to the rescue. However, none of them is available “out of the box” and their setup, maintenance and operation could also become an impediment.
GerritForge has a historic know-how on knowledge-based systems and has been lecturing the community about data collection and analysis for many years in the Gerrit Code Review community, for example the Gerrit DevOps Analytics initiative back in 2017. It is now the right time to push on these technologies and package them in a form that could be directly usable for all those companies who need it now.
Introducing GHS – GerritForge-AI Health Service
As part of our 2024 goals, GerritForge will release a brand-new service called GHS, directly addressing the needs of all companies that need to have a fully automated intelligent system for collecting, analysing and acting on the Git repository metrics.
The high-level description of the service has already been anticipated at the Gerrit User Summit 2023 in Sunnyvale by Ponch and the first release of the product is due in Q1 of 2024.
How does GHS work?
GHS is a multi-stage system composed of four basic processes:
Collect the metrics of your Gerrit or other Git repositories automatically and publish them on your registry of choice (e.g. Prometheus)
Combine the repository metrics with the other metrics of the system, including the CPU, memory and system load, automatically.
Detect dangerous situations where the repository or the system is starting to struggle and suggest a series of remediation policies, using the knowledge base and experience of GerritForge’s Team encoded as part of the AI engine.
Define a direct remediation plan with suggested priorities and, if requested, act on them automatically, assessing the results.
Stage 4, the automatic execution of the suggested remediation, can be also performed in cooperation with the SCM Administrators’ Team as it may need to go through the company procedures for its execution, such as change-management process or communication with the business.
However, if needed, point 4. can also be fully automated to allow GHS to act in case the SCM admins do not provide negative feedback on the proposed actions.
What the benefits of GHS for the SCM Team?
GHS is the natural evolution of GerritForge’s services, which have historically been proactive in the analysis of the Git SCM data and the proposal of an action plan. The GerritForge’s Health Check is a service that we have been successfully providing for years to our customers; the GerritForge Health Service is the completion of the End-to-End stability that the SCM Team needs now more than ever, to survive with a reduced workforce.
To the SCM Administrator, GHS provides the metrics, analysis and tailored recommendations in real-time.
To the Head of SCM and Release Management Team, GHS gives the peace of mind of keeping the system stable with a reduced workforce.
To the SCM users and developers, GHS provides a stable and responsive system throughout the day, without slowdowns or outages
To the Head of IT, GHS allows to satisfy the company’s needs of costs and head count reduction without sacrificing the overall productivity of the Teams involved.
GerritForge’s pledges to Gerrit Code Review quality and Open-Source
GerritForge has provided Enterprise Support and free contributions to Gerrit Code Review for 14 years, pretty much since the beginning of the project. We pledged in the past to be always 100% Open-Source and do commit to our promises.
For 2024, GerritForge will focus on delivering its promising Open-Source contributions to the stability and reliability of Gerrit Code Review, with:
Support for the Gerrit Code Review platform releases, Gerrit v3.10 and v3.11
Free support and development of the Gerrit CI validation process, in collaboration with all the other Gerrit Code Review contributors and maintainers
Free Open-Source fixes for all critical problems raised by any of its Enterprise Support Customers, available to everyone in the Gerrit Code Review community
Free Open-Source code base for the main four components of the new GHS product, following the Open-Core methodology for developing the service.
With regards to the initiatives that we started in the past few years, including pull-replication and multi-site, we believe they have reached a maturity level that would not need further major refactoring and extensions in 2024. We will continue to support and improve them over the years, based on the feedback and support requests coming from the Enterprise Support Customers and the wider Gerrit Open-Source community.
GHS AI engine and dogfooding on GerritHub.io.
GHS will have a rule-based AI system that will drive all the main decisions on the selection and prioritisation of the corrective actions on the system. As with all AI systems, the engine will need to start with a baseline knowledge and intelligence and evolve based on the experience made on real-life systems.
GerritForge’s commitment to quality is based on the base principle of dogfooding, where we use the system we develop every single day and learn from it. The paradigm is on the basis of our 14 years of success and we are committed to using it also for the development of GHS.
GerritForge has been hosting GerritHub.io since 2013, and tens of thousands of people and hundreds of companies are using it for their private and Open-Source projects every single day. The system is fully self-serviced; however, still relies on manual maintenance from our Gerrit and Git SCM admins.
We are committed to starting using GHS on GerritHub.io from day 1 and use the metrics and learning of the systems to improve its AI rule engine continuously. All customers of GerritForge’s GHS service will therefore benefit from historic knowledge and experience induced by the the learnings and optimisations made on GerritHub.io for the months and years to come.
GHS = Git SCM admins humans and AI-robots working together
GHS will revolutionise the way Git SCM admins are managing the system today: they will not be alone anymore, juggling a series of tools to understand what’s going on, but they will have an intelligent and expert robot at their service, driven by the wisdom and continuous learnings made by GerritForge, at their service every single day.
We expect a different future way of working in front of us: we are embracing this radical change in how people and companies work and making GHS serve them effectively and in line with our Open-Source pledges.
The future is bright with GerritForge-AI Health Service, Git and Gerrit Code Review at your service !
Luca Milanesio GerritForge CEO Gerrit Code Review Release Manager and member of the Engineering Steering Committee
Dear fellow Gerrit User, We are pleased to announce that GerritForge will be organizing this year’s Gerrit User Summit and Hackathon in hybrid mode: face-to-face and online.
Gerrit User Summit is the event that brings together Gerrit admins, developers, practitioners, and the whole community, in one place, providing attendees with the opportunity to learn, explore, network face-to-face, and help shape the future of Gerrit development and solutions.
After two years of remote meetings and virtual conferences, this year, we are back face-to-face at CodeNode in the heart of the vibrant City of London.
The dates will be: Nov 7th to 9th – Hackathon Nov 10th to 11th – User Summit
Shortly we will be publishing the full schedule and logistics for the event. I look forward to meeting all the community’s friends, face-to-face or virtually, again during the Hackathon & Summit.
Thanks for being a part of the Gerrit community, and we look forward to seeing you in November.
Luca Milanesio Maintainer, member of the Engineering Steering Committee, and Gerrit Code Review Release Manager
After two years of remote events and three COVID-19 waves, we are finally back for a new face-to-face hackathon, talking about the future of Gerrit Code Review and coding new and innovative solutions for making Gerrit better, faster and more scalable.
Dates and schedule
The Gerrit hackathon will start on the 9th of May at 9:00 AM for five consecutive days, and will have a daily schedule from 9:00 AM to 7:00 PM BST, with networking and catch-up in the evenings.
For the remote attendees on the US/Pacific time-zone, the schedule will be daily between 7:00 AM to 11:00 AM PDT, which allows 4h of remote interaction with the hackathon in London.
Who is invited to attend the hackathon?
As with every Gerrit hackathon, we have a restricted audience: Gerrit maintainers and contributors are invited to join. We have 10 seats available on-site and 15 seats available remotely, which would allow plenty of people to collaborate and discuss.
The “Alphabet” meeting room of the hackathon
To register to the Gerrit hackathon, add your name and role (“Gerrit Contributor” or “Gerrit Maintainer”) to the attendees sheet. All Gerrit maintainers have edit permissions to the document whilst all other contributors can request permission to edit if they are willing to attend.
Where is the hackathon taking place?
GerritForge will host the Gerrit Hackathon at Huckletree West, Mediaworks, 191 Wood Ln, London W12 7FP. We will be staying at the “Alphabet” meeting room, with a dedicated 10-seats and roundtable, a full-size wall-mounted whiteboard and a permanent online connection and wall-attached screen to interact with all the other remote attendees.
Huckletree West
Huckletree is a creative workspace in West London, based in the heart of White City Place, a thriving new business and cultural district. Alongside the neighboring BBC Studios, Net A Porter Group, and RCA School of Communication, Huckletree West is part of a bold new chapter in the rich creative history of the neighborhood.
For all remote attendees, there will be the ability to connect remotely and interact with the rest of the team on-site during the hackathon hours.
White City and local accommodations
Huckletree West is close to the WestField Shopping Centre in White City, which includes 289 stores, 95 restaurants and Cinemas with 20 screens and almost 3,000 seats.
White City has excellent connections to all parts of London through the London Underground network (Central, Hammersmith&City and Circle lines) and Overground trains, which allow to reach all other parts of the city.
WestField shopping centre – White City
You can look for any Hotel or other accommodation (B&B or Hostels) in other part of London which is covered by the London Underground connections. However, if you are willing to stay local, there are many choices of Hotels and B&B starting from £80/night. See below a list of accommodations nearby White City:
The UK has left the European Union the 1st of January 2021, all travellers from EU needs to follow the new rules for business trips. You can check if you need a VISA using the UK Government site and what is the required documentation and insurance required to show at the UK Border.
COVID-19 restrictions
The UK is set to end all COVID-19 restrictions by March 2022, which means there aren’t any vaccination or testing requirements for the attendees to the hackathon. We advise everyone attending face-to-face to take extra precautions and take a lateral-flow test (LFT) or antigen test before traveling to the hackathon, even though it is not required by law or regulations.
Please note that face covering are still mandatory whilst travelling by airplane, train or underground and during taxi rides.
We are excited to meet again the community of Gerrit Code Review maintainers and contributors after so many months. Come and join us in London this year and we can innovate again and help shaping the future of the Gerrit project, together.
Luca Milanesio, GerritForge Gerrit Code Review Maintainer Gerrit Code Review Release Manager Member of the Engineering Steering Committee of the Gerrit Code Review Open-Source project
Join the Gerrit Community tomorrow and Friday from 8 am PST for everything related to the Gerrit Code Review Community.
Gerrit provides web based code review and repository management for the Git version control system. Whether you are experienced or new to Gerrit, you should know that it provides a framework you and your teams can use to review code before it becomes part of the code base. Come and take this chance to join and learn about Gerrit Code Review.
Find here the full schedule of the sessions you will have access to.
The Gerrit Community is happy to announce the Gerrit Virtual User Summit 2021, THE event of the year for everything related to Gerrit Code Review and the trunk-based development pipeline.
A Virtual Summit
The Gerrit User Summit 2021 will be held online only, to allow most of the community around the globe to attend and share their experience and ideas, and avoid the problems with the travelling restrictions due to the COVID-19 pandemic.
The 2-day User Summit is open to all the members of the community as well as those that are willing to learn and adopt Gerrit Code Review in their development process.
This week we are honored to publish the amazing talk of Gerrit Ver. 2.15 presented by Dave Borowitz, the “father” of NoteDb review format. It is the very first time that a full roadmap of the migration from the traditional ReviewDb (a relational DBMS) to NoteDb (a pure Git notes-based review store) is drawn and explained in all details.
First steps with Gerrit Ver. 2.15 using Docker
For all of those who want to experiment what Dave has presented at the Gerrit User Summit, there is a Gerrit Ver. 2.15 RC2 Docker image already published on DockerHub on https://hub.docker.com/r/gerritcodereview/gerrit.
See below the simple instruction on how to start a Gerrit 2.15 locally and playing with it.
Open your web-browser at http://localhost:8080 and you will automatically get into the plugin manager selection. At the moment only the core plugins are available, so you can just click on to top right “Go To Gerrit” link.
As soon as Gerrit 2.15 will be officially available, you would be able to discover and install many more plugins on top of your installation.
Step 3 – Create a new Repository
Click on the new top “BROWSE” menu and select “CREATE NEW”
Then insert the repository name (e.g. “gerrit-playground”), select “Create initial empty commit” to True and click on “CREATE“.
Step 4 – Clone the repository
From the repository page select the “HTTP” protocol and click on the “COPY” link next of the “Clone with commit-msg hook” section.
Click on “CODE-REVIEW+2” button on the right toolbar to approve the change and then press “SUBMIT” to merge into the master branch.
What’s new in Gerrit Ver. 2.15
Hi, I’m Dave Borowitz, I work for Google, and I’m going to talk about what is new in Gerrit 2.15. We have a six months release cycle, and it has been around 158 days since Ver. 2.14.0 was released in April, and now, just last night at 10 PM, I have release 2.15-RC0.
Gerrit Ver. 2.15 in numbers
Gerrit Ver. 2.15 is aligned with other recent releases:
2,102 commits
53 contributors from all around the world and different companies
seven new contributors who have never commit before
I don’t know if any of the new contributors are in this room and if they are, thank you, if not I will thank them remotely.
PolyGerrit frontend
There is a bunch of new stuff going on in Gerrit Ver. 2.15, I will talk only briefly about the frontend, because we had an excellent talk from Logan and Arnab and Justin this morning about what’s happened recently in PolyGerrit.
I want to give you my perspective as a developer that is doing mostly backend work. It’s fascinating to have in Gerrit a modern JavaScript environment to develop in because it has been historically difficult for us to attract frontend developers in the project. There are not just enough GWT developers in the world as there are JavaScript developers and I think that the Gerrit project has suffered from a lack of UI attention in the past because of that.
But now we have a whole team here at Google, we have a lot of external contributors, that are happy to work on modern JavaScript, and PolyGerrit has made some excellent strategies of improving the user experience.
PolyGerrit is also usable. Everyone that has been working in software development always has the attraction of starting from scratch and say “how would have done it differently, “: PolyGerrit follows a little bit that approach.
We understand that we have users that are used to a certain workflow and we have to preserve it. However, when you are writing new code, you have the opportunity to learn from your past mistakes and improve things and maybe make it easier to onboard new people.
There is a little bit of preview of what PolyGerrit looks like in Gerrit Ver. 2.15; I had to cut the screenshot last night to make sure that it would be entirely accurate.
You can see that there is a reasonable rate of improvements, even in the last 24h and I hope that we will keep this peace of development.
Backend
From Ver. 2.15 we support NoteDb, and we suggest that you should convert your existing ReviewDb to NoteDb.
What is the motivation for doing NoteDb? Until now the Gerrit administrators had to be DBMS Administrators as well which is a sort of weird feeling: you care about version control and software development workflow, and, for some reasons, you should take care about being a DB Admin?
The idea behind is that we carry on the data historically stored in ReviewDB and we move it directly into the Git repository.
When you create a new change with a patch-set, a topic and all its meta-data, including comments and reviewers then everything gets stored in the same Git repository with the rest of the committed change data. There are several advantages in storing data and meta-data in this way.
You don’t have to worry about two stores that somehow are going to get eventually inconsistent. If you have to make a backup of your Gerrit Server, you have to take a Database dump and then to have a backup of all of your repositories. If you want to have a consistent backup where everything that is stored in the Database exists in the Git repository and vice-versa, you have to do it while the server is down. There is no other way to do it because you may get new records in the database while you are backing up the Git repositories and you would not see that data reflected.
With NoteDb, it’s all in the Git repository, and it is even better because we changed JGit to be able to write to multiple Git repositories refs atomically atomically. This means you can submit a change and also submit the status of the meta-data at the same time. When you upload a patch-set, we update three refs, either all of them succeed, or all of them fail. There isn’t a state where the change was merged in the branch, but the ReviewDb wasn’t updated, that is just no longer possible. That enables us to have consistent backups.
NoteDb provides a very helpful audit log. We had a lot of data issues in the past where could not understand how a change got into a particular state because in ReviewDb you just update a field with ‘X’ and you forget completely that the field was previously with a value ‘Y.’ In Git the model you append commits to a history graph, so you actually store every operation that has ever happened on NoteDb, and that gives you an understanding on how a change ended in the current state.
We are thinking about giving extensibility for new features, and this is a kind of optimistic view about the future, plugins will be able to add new data to NoteDb while it wasn’t possible for a plugin to add a new column to an existing table of ReviewDb. I don’t think that we have any plugins that are currently able to leverage this capability and we do not have any extension for it yet, but the data layer supports it.
Whilst is automatically giving new features such as moving changes between Gerrit hosts without having to throw away code review meta-data.
NoteDb roadmap
We never actually pictured in the past a complete NoteDb timeline, which spreads across five long years.
2013
The very first commit on NoteDb was in December, that was a very long time ago.
2014
We had an intern, and he wrote all the stuff on inline comments in NoteDb.
2015
I wrote a thing that it was at the end a good idea in retrospective, but it was a considerable amount of work. It is called the batch update and allows to have a coordinated transaction across two different data-store with a consistent interface. This period is what I called “rewrite every single line of Gerrit”.
2016 We started migrating googlesource.com; ReviewDb still existed, and it was always the single source of truth in case they got out of sync with NoteDb. Later this year, a few months ago, we moved everything to NoteDb and we don’t use the change table anymore. We have several hundreds of servers nowadays using NoteDb and generated several hundreds of changes to it. That is exciting, we have been running in production for months, and that’s why we believe it could work for other people to run in production.
2017 Last night, we released Ver. 2.15, the first version of Gerrit where we officially say “we officially support NoteDb and we encourage you to migrate away from ReviewDb.”
2018 We are going to release Gerrit Ver. 3.0 and Ver. 3.1. The reason for the name ‘3.0’ is because we will not have ReviewDb anymore. There will still be the code and the ability to migrate from ReviewDb to NoteDb, but you would not be able to run Gerrit on ReviewDb. The Ver. 3.1 is the one I am most excited about because in that version we do not have even to support a migration tool. We will then be able to throw away all the ReviewDb code, and that would make me very happy.
How to migrate from ReviewDb to NoteDb
I mentioned that migration for googlesource.com took us a very long time because we’ve found a ton of issues with our data. We discovered all these things while we were running our migration and we fixed them all.
We developed a system that was scanning all ReviewDb, performed an in-memory migration and then compared the result with the changes stored in NoteDb. One example of a bug was that some subjects were truncated in ReviewDb. The subject is supposed to come from the first line of the commit message. We were comparing the data in Git with the data in ReviewDb and they did not match because they were truncated. If we were to require that all the subjects in NoteDb were identical to the ones in ReviewDb we would have never passed because there was this truncation. We could have patched all the existing data but actually what we did is to consider that if the subject in NoteDb starts with the subject in ReviewDb it was then regarded as valid. There were many more bugs of that flavor.
There were also bugs in the NoteDb code that we fixed; it was not just like all related to not good data; my code was far from being bug-free. The reason why I am talking about how much effort we put in making it right is that I want you to feel confident and not think about that this is a so much scary operation on your data. We tested on ourselves, and we fixed a lot of these bugs, and we are still pretty confident that this is a safe operation.
In Ver. 2.15 there are two types of migration options: on-line and off-line. At Google, we are in an exceptional condition because we are always at zero downtime, but that was useful because it allowed us to write a tool for a live migration from ReviewDb to NoteDb while the server is running.
Migration to NoteDb is pretty much similar to the way you do reindex: there is an online reindex and an offline reindex. You can choose to do it offline, and it will be probably faster, but there will be a downtime. Or you can decide to do it online, and it will be slower, but there will be no downtime.
And then in Ver. 3.0 we only are going to support an off-line migration, following the same paradigm of all the other schema upgrades. If you skip between releases, we force you to do to an off-line update, but if you upgrade just one point release at a time, you don’t have to have any downtime for your schema migration. Similarly for NoteDb if you migrate from Ver. 2.14 to Ver. 2.15 and then Ver. 3.0, you won’t have any downtime.
Q: (Han-Wen) Is this process parallel?
A: It is parallel if you do it offline if you do it online it is using a single thread because we are assuming that your server is mostly busy doing other stuff and that’s why you may want to do an online migration in the first place.
Benefits of migrating to NoteDb
There are a lot of incentives to migration to NoteDb; one is that you have new features such as hashtags and others that we implemented only in NoteDb because they were a lot harder in ReviewDb such as the history of all reviewers on a change. NoteDb manages audit natively while on ReviewDb we would have needed to have a new table called reviewers_audit which would have been much harder to implement.
The robot comments introduced in Ver. 2.14, the ability to remove clutter in your dashboard to mark a change as reviewed, are all features that you only have in NoteDb.
What did we learn from migration to NoteDb?
Writing every single line of code just takes a long time, and Gerrit has hundreds of thousands of lines of code. Shawn Pearce, my manager, and the Gerrit project founder at Google, every time he needs to touch NoteDb related code just says “I don’t even recognize this, ” and he is still the contributor #1 in the project. We changed it almost beyond its recognition.
Everything I’ve said so far is about changes; there are also other data besides changes. Accounts have been unconditionally migrated to NoteDb in Ver. 2.15. Is more a git config file format for the accounts that we store in NoteDb, it is not even actually a Note-space format. The account is now a config file that has your name and your e-mail address and the status, which is a new feature in NoteDb. For instance, my account status says that “I having a talk in England”.
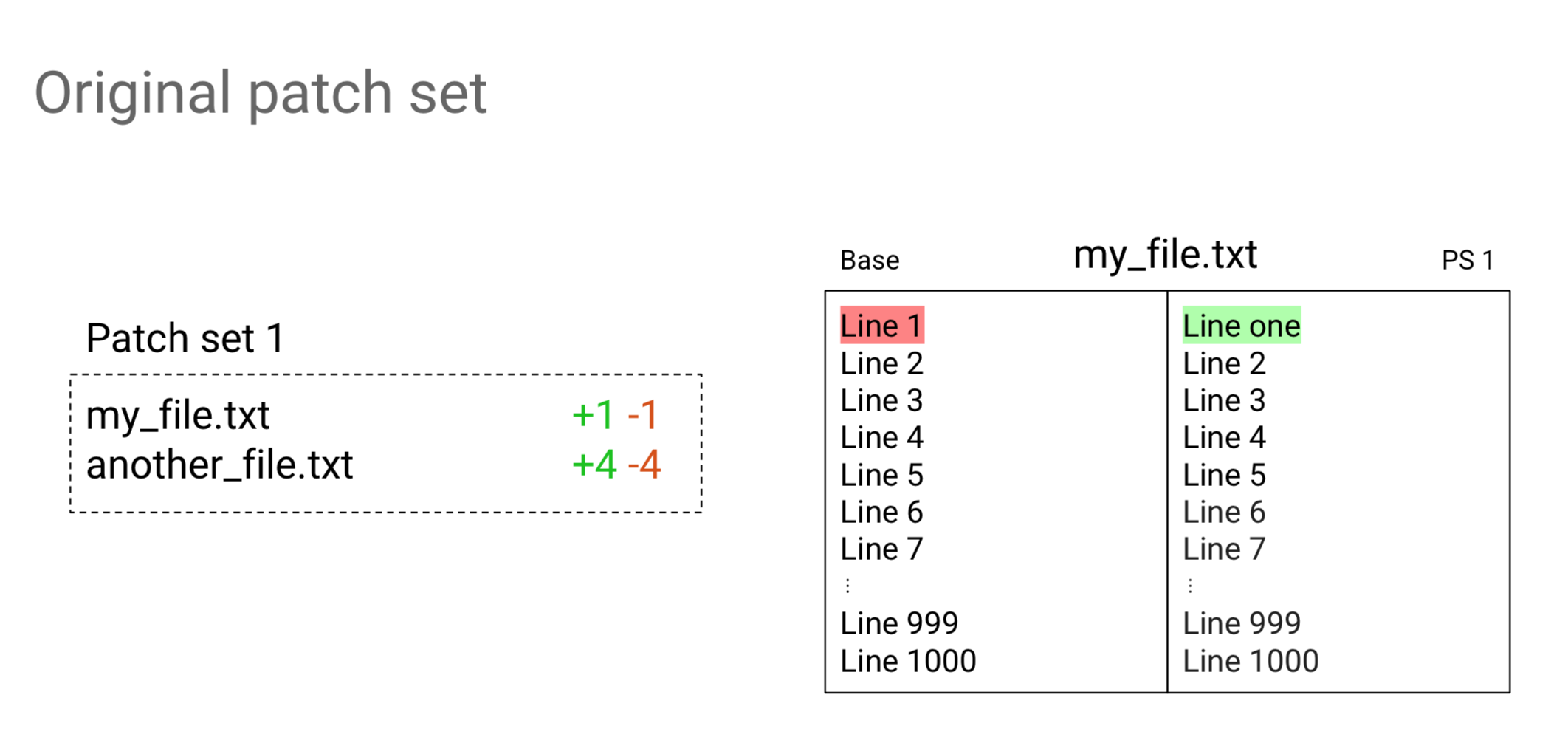
New Patch-set comparison
Hi, my name is Alice Kober-Sotzek, and I work at Google. In Ver. 2.15 we have changed the way we compared patch-sets. Let’s imagine we have just a small change with a patchset and two files on it. In the first file we have only the first line modified, and the file consists of one thousand lines. The second file has four lines changed.
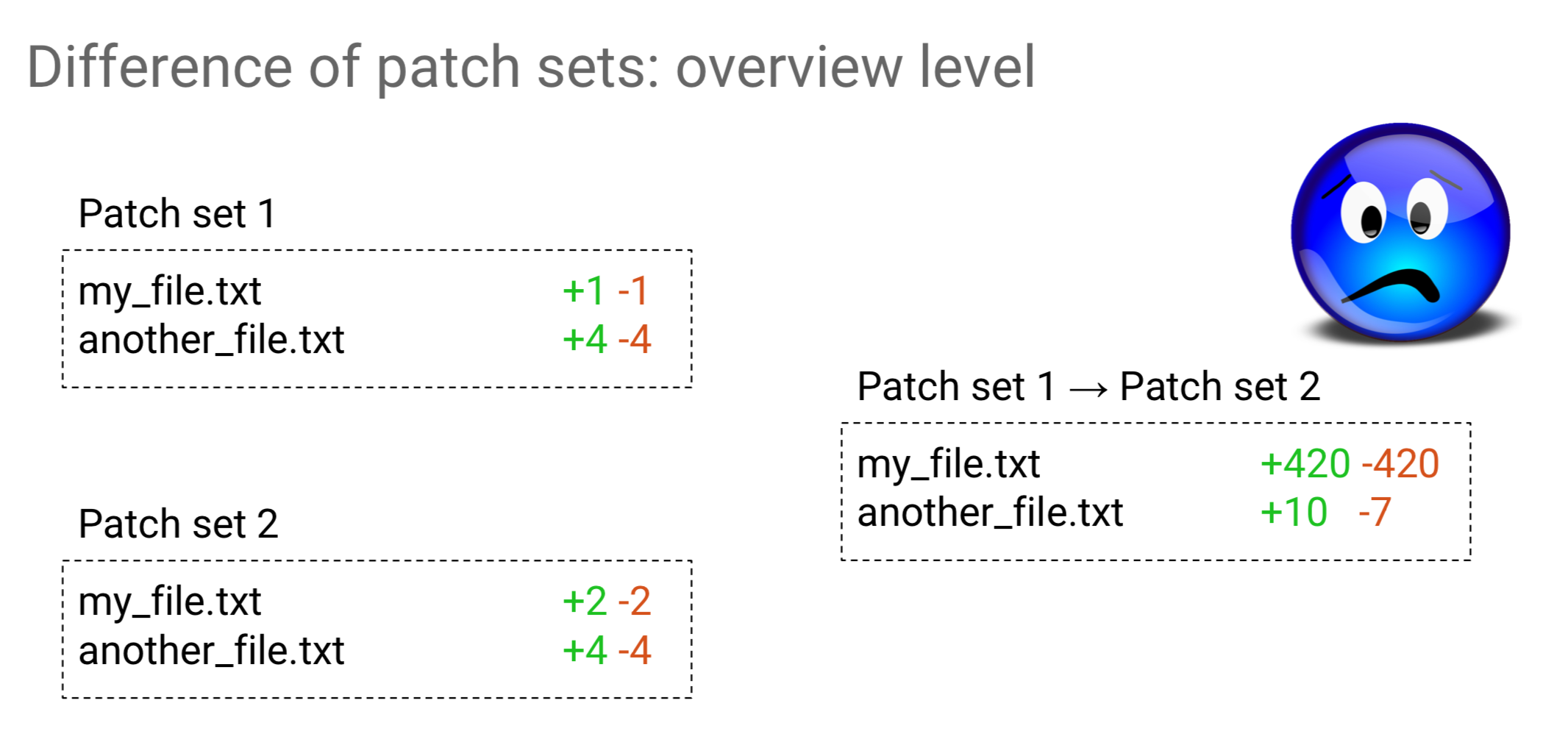
Let’s see what happens now when I rebased it to the latest version of master. If I had now to visualize what the patchset 1 consisted of and patchset 2 consisted of, what would I assume it would be? If I had been the author of the change, I would have expected that only one line would have been changed. Let’s just do it and ask Gerrit Ver. 2.14 what the result is.
What’s happening? Why do I have 420 lines changed in my file and ten additions and seven removals on the other?
That was not even touched on. Let’s have a look at the content of my file and what is in there.
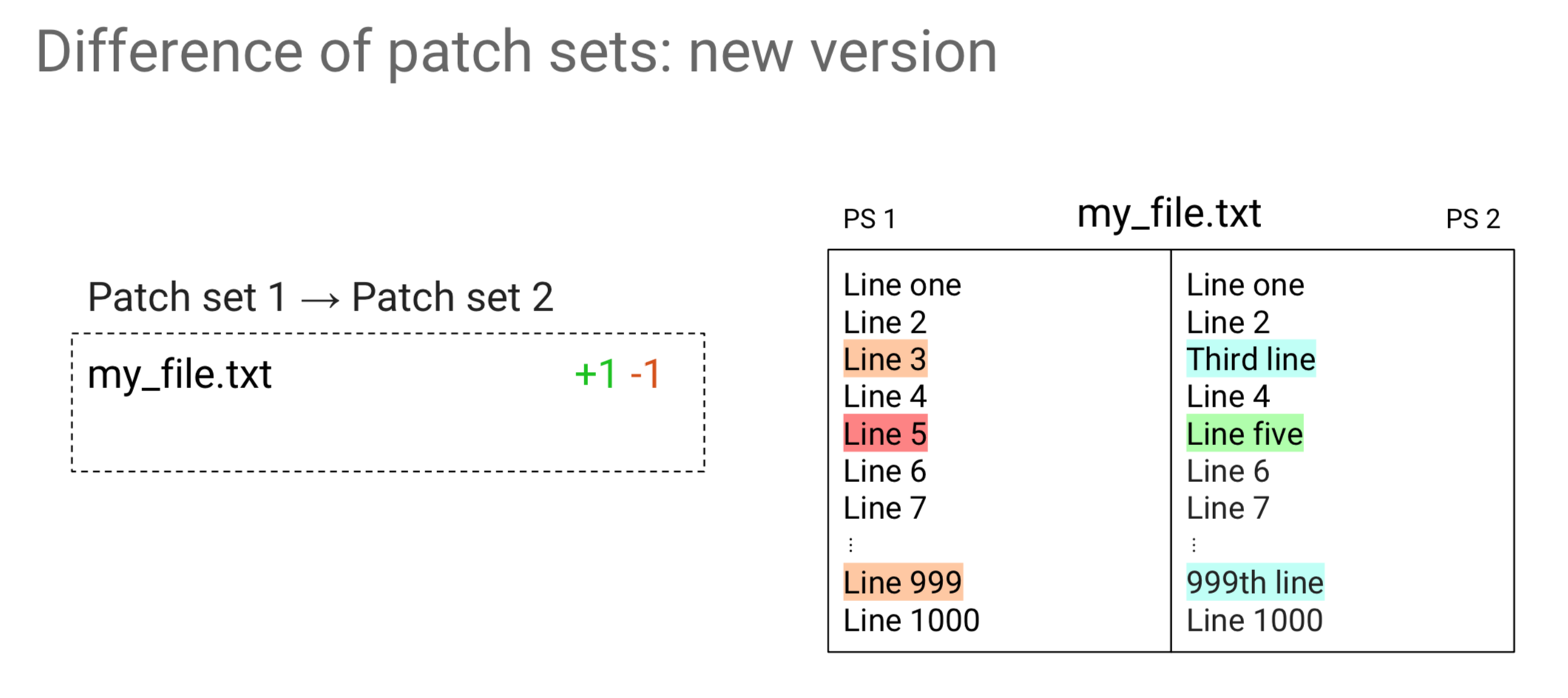
In Ver. 2.14 we were just hiding all the differences due to rebasing, and that was it. In Ver. 2.15 things look different though because we try to figure out what happened in between the rebase. All the hanks that we are sure are added by something else, are displayed in a different color. We have not only red and green but orange and blue as well; these are all the ones that were introduced by other changes that were in between rebase.
This feature only works in PolyGerrit, while in GWT was not shown at all.
Can I rely on that and trust what I see there?
The decision we made is that all the hunks marked with orange and blue are the ones we are sure of and you can safely avoid looking at them because they were the ones that happened because of other changes occurring in between rebase.
The ones marked with red and green, we give no guarantee. They could be introduced by other changes, because of conflicts or may be added by the patchset. With that coloring, it is much easier to look at the things that are important.
Killing Draft Changes.
Some of the people think that draft changes are very much a visibility thing so that only my reviewers can see them. Other people use it like a change is not yet ready for review so that I can leave it as draft change until it is ready for being reviewed. You may even just use the server as a store for your changes; rework the code through the Gerrit in-line edit feature until the code is ready and then come up with an absurd number of patchsets. Nobody wanted any of them, but those are the conditions that we ended up with patchset drafts.
Patchsets could have been even deleted so they would never exist. They could just be kept invisible so that you see a gap, but that could be the current patchset: the UI claims that the current patchset is three, but then I do some other operations that say that this patchset is not current anymore, just because the current one is a draft!
Drafts are a kind of mass fraud; the main reason is that they are colliding all these things into a single feature. In Gerrit Ver. 2.15 we killed drafts. Now you have little small features instead of drafts. You have now “Private Changes” which only you and your reviewers can see. There are Work-In-Progress (WIP) changes, that means that while the WIP flag is set nobody gets notifications about it: you can push 30 patchsets, and the reviewers would not get spammed with 30 emails. Last but not least, we introduced a long ago the Change Edit, which can be used as well in conjunction with WIP Changes.
Marking Changes as reviewed
Another thing that we introduced in Ver. 2.15 is the ability to mark changes as you reviewed it. For instance, the one below is a change screen from my dashboard this morning: some changes are highlighted in bold and those other changes are not. I feel like the bold changes are yelling at me and you have to give me your attention just like in e-mails where bolds means “you need to look at me now.” Gerrit Ver. 2.15 when you are using NoteDb allows you to unbold any of them by just clicking a button on the change screen. Or like in an email you wish to remove some changes from your dashboard entirely. There is a function that allows you remove a change unilaterally from your dashboard that the other cannot undo or ignore it, that just makes the change go away.
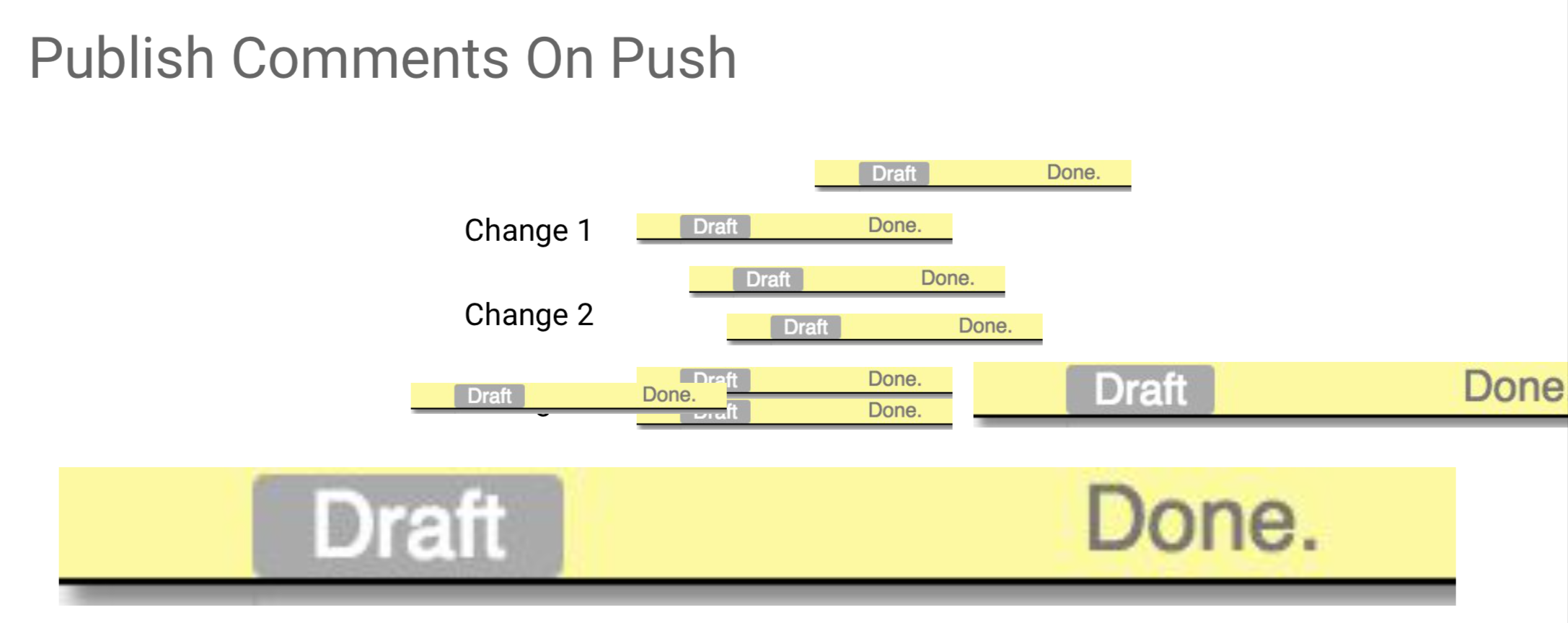
It was annoying that I could not mark them as reviewed manually and it was really irritating that patchsets disappeared. It is really irritating when I received a review with a bunch of comments, I had to say “done, done, done, done” on each one of them.
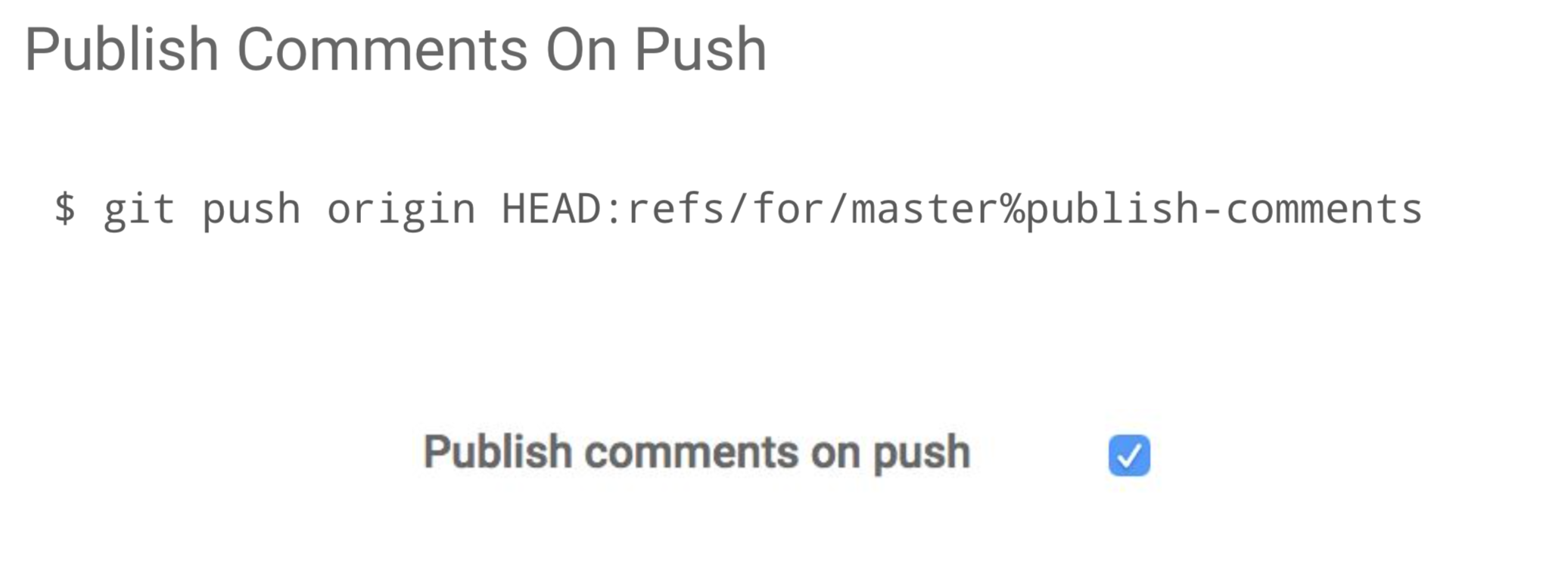
And then when I pushed a new patchset, I just forgot to submit all these drafts comments that say “done”. So I added just a push option that says “when you push, publish comments” and all the draft comments will be published automatically. So instead of clicking on all the patchset on that change and check if in any of the patchset I have any draft and if I do, click send on all of them one by one, I can instead just set an option.
It can be specified by the command line, but it is difficult to remember. So there is a user preference with a checkbox which I really encourage you to select in your user preferences screen and it is only available on PolyGerrit.
CCing a Change under review
When someone is getting a co-worker and they want him to be a reviewer for a change, you get an error saying that your co-worker is not a registered user. We have partially solved this problem by adding a CC with an e-mail address, also only available on NoteDb. There are technical and even product reasons why we don’t want to add them as a reviewer, some of them are related to the accountability related to everyone that is working on that change. So people needs to have an account to be a reviewer, but if people just want to look at it or a mailing list, it doesn’t have to be a real user, you can then just CC any e-mail to a code review if you turn the config option to allow this.
Better error messages.
Another inch that Han-Wen scratched was the introduction of better error messages. Sometimes you do a push, and it fails with a very unhelpful error message that says “Prohibited by Gerrit.”
It turns out that it is not difficult to check if a user does not have a permission then gives permissions error, so we have included a message saying this user lacks this permission. It is not perfect, so it doesn’t say precisely where in the project hierarchy this permission was coming from but at least says “this is the problem”, it tells you not the solution but at least highlights where the problem is.
Robot comments and automatic fixes.
Robot comments are a feature that we believe it will start to rump up in adoption. With NoteDb, you can suggest fixes as well, and then you have a button that says “apply fixes” which creates a change that applies the fixes.
Many more improvements in the bag.
There is a lot of speed improvements in PolyGerrit, so the changes with a lot of diffs will run a lot faster. An admin can delete comments that really shouldn’t be there. We can explicitly keep track that a change reverts another change so that you can search if that change was reverted. It can even tell you if that was a pure revert at Git level only, or if other changes were sneaked in claiming that this was only a revert which happens way too often I think.
There are a better server consistency checks and a new plugin endpoint for dashboards; there is a new URL scheme as described by Patrick and we are now off the page for putting, even more, new features.
The fourth talk of the Gerrit User Summit 2017 edition is Zoekt, an improved fast and secure Code Search engine made by Han-Wen at Google.
One year after its inception, the search engine supports now Unicode v2.0 and is fully integrated with Gerrit ACLs, ready to be used with large enterprise installations.
Say hello to Zoekt, the fast source code search
My name is Han-Wen, I’ve been writing a new source code search engine called Zoekt.
Here is the home page of the search engine and you can see that I am not a Web UI person 🙂
It is running on the public internet on the website hosted by my friends of the Bazel Team.
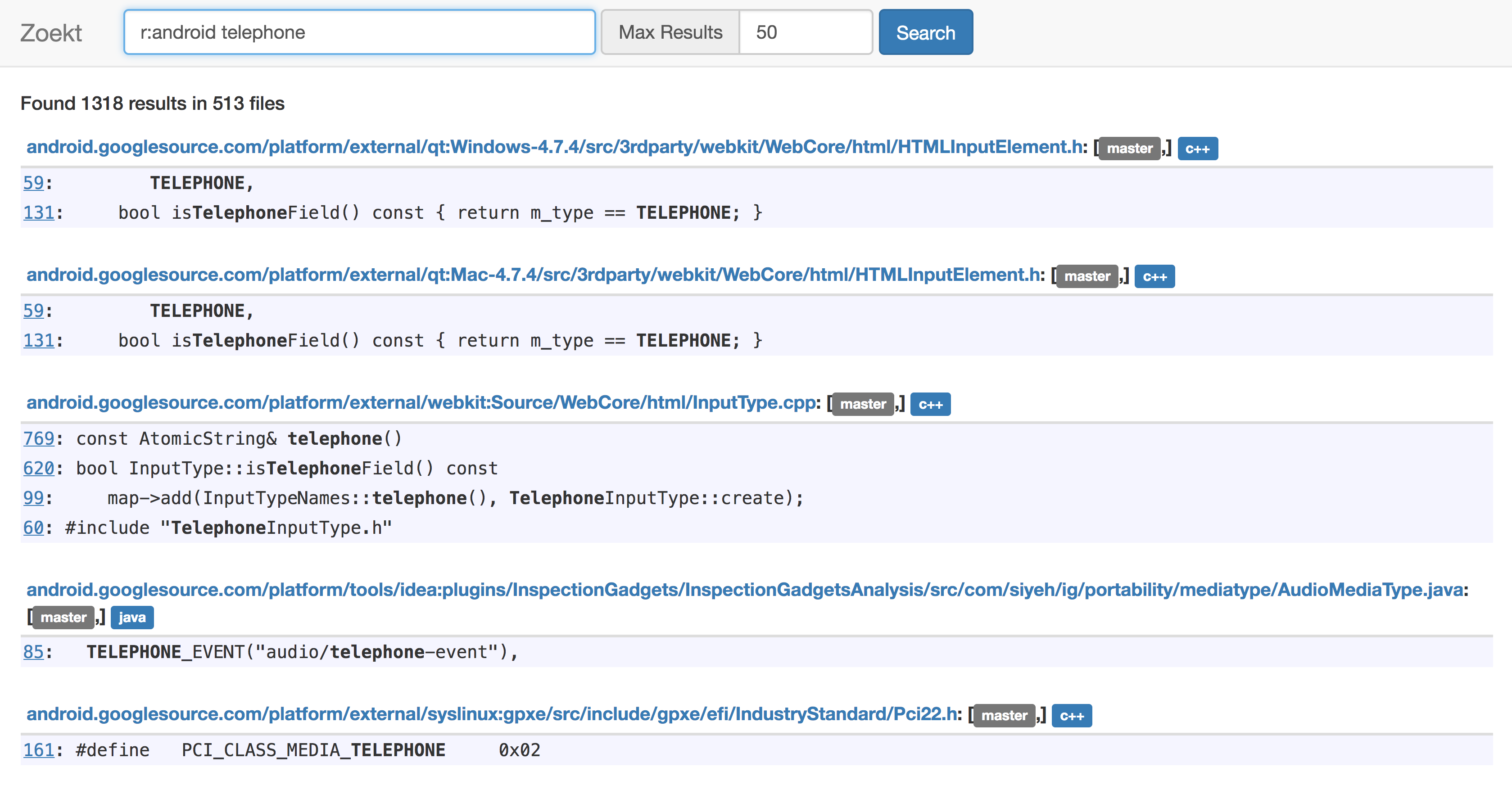
It has a bunch of source code indexed, about 30 GB, which is mostly Google source code. You can search through the Android source code project for things that match “telephone” and get lots of results associated.
Linus Torvalds created the Linux operating system and, as we all know, he has not a very diplomatic use of language. If you want to know where he says “crazy idiot” you can find it in just under 9 milliseconds!
Zoekt is super fast and is OpenSource. You can run it on your server or your laptop, but if you want just to check it out, you can go to this URL: https://cs.bazel.build.
Why I did this?
I work at Google, and I spend most of my time looking at others’ code and trying to understand what is doing. Frequently I have to dig into code that I don’t know, and I have not necessarily have checked out locally. I use the Google internal code search for that, and I missed it when I started to work on Gerrit. Then I thought: “I can fix that, I can just do it on my own.”
Last year I announced this search code site running on the Bazel site and was a kind of the first instance. I have been running it for one year, finding a lot of bugs and things that could break and developed many improvements and I am going to show you some of them today.
The core of a search engine for code is an engine that can find substrings in a large file of text. They can be arbitrary substrings, and most of the code search engine like to search for words. However, if you take the last char of the word away, e.g. you are not looking for “crazy idiot” but only for “craz idiot”, most search engines like ElasticSearch of GitHub won’t find any match.
ASCII vs. Unicode
Zoekt works, but the implementation was initially based on the idea that everything is ASCII and then any char is one byte. In reality, a lot of text is not just ASCII and, maybe, someone from Sweden has the strange “A” with the circle on top. The character is then is no longer ASCII, and you can’t search for any of their names. That is a bummer, and then I thought “well, it kinda works, but it doesn’t really work”. The regex engine uses Unicode for searching, and that leads to bugs, that means things are right there, but you can’t find them.
That happens surprisingly often like, for example, the source code of this project which has Unicode characters because it has some tests about Unicode. Finally, this is just a bug, and to me, this is pretty much like the mountain Everest.
Why do people climb mountain Everest?Because it is there. And why I wanted to fix this bug? Because the bug was there.
Triagrams
Before you can understand what the bug is, you need to understand what Unicode is and how it works so that you can understand why the code was not working before.
The basic idea of code searching is that you build an additional data structure that helps you find things in a large chunk of text.
For example, we have two files, one contains the word “code” and the other contains the word “model”. What we do is split it out into two sequences of three characters, and we record the offsets of each of those group of threes: we call them triagrams. Then we create an index of the triagrams and the associated offsets. If you want to look for “temp 50C max”, you take the first group of three characters which is “tem” and the last group which is “max”. Then you look for this with exactly the distance of 10 characters apart, because with this data structure over here we can do this very efficiently.
So we are looking for the characters “tem” and in the data structure over here we should find something that matches “tem” and you only have to look at one row over here and may to another one row over there. Finding if a string is not there is very quick and, if the string is there, these offsets will give you the position for a real string search.
In practice, you always want to look for things disregarding case. In this case, if you ‘re going to do it case insensitively you can generate all the different flavor of cases, for the first and the last triagram, and then you can do the same strategy again.
What about Unicode?
Unicode, in essence, is a mapping from numbers to meanings, for example, the Unicode number 24991 is the Chinese character “Wen” which is part of my name. So, it is a huge book which is a sequence of numbers mapped to a list of different characters.
The predecessor was ASCII in 1963 where you find the common characters like “abcd”. In 1988 Unicode Ver. 1.0 introduced a space for 65 thousand characters; the people that invented it were not too familiar with Asian languages because it turns out that you can fill a lot of Chinese and Japanese into that but if you want to have all the characters it is a little bit tight on space. In 1996, Unicode Ver. 2.0 introduced a 21-bit space with the ability to represent up to 2 millions of characters, including as well this Egyptian character and the “poo” emoji.
UTF-8 encoding
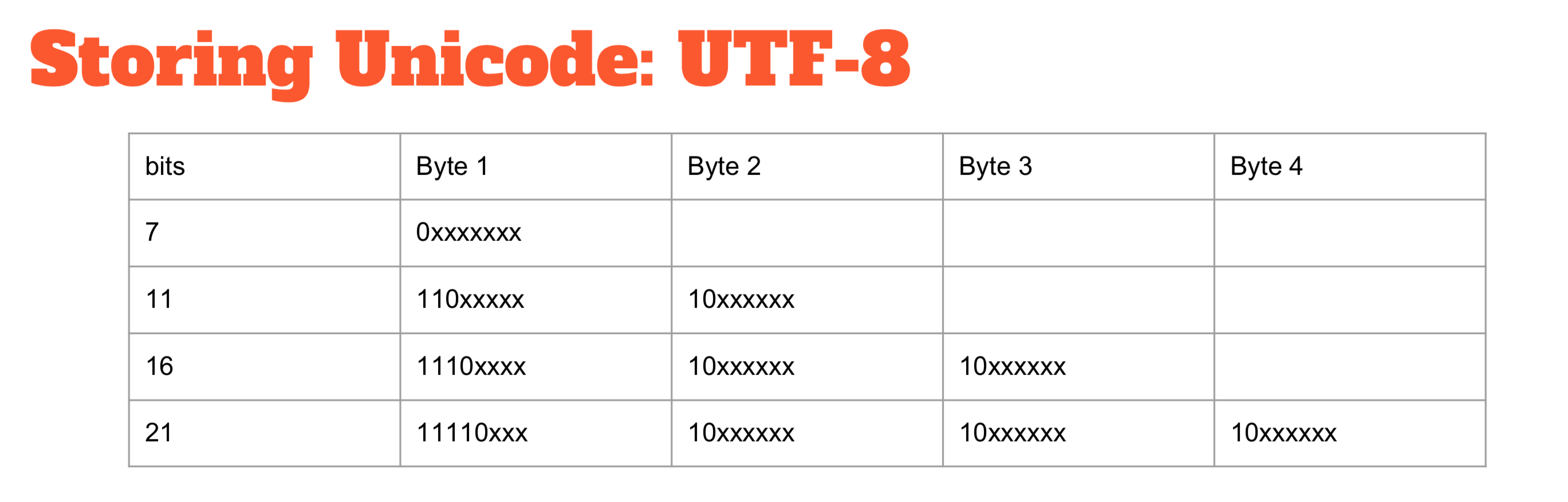
It is important to remember that Unicode is merely a book of numbers and their associated characters. It doesn’t say anything on how you store this data and that is why you need an encoding format. There are different encodings, but the one that has won is UTF-8. It uses a scheme where the ASCII characters have a first 0 bit at the beginning and then 7 bit of data. If you have a character that needs more space, you start using multiple bytes for its representation.
The advantage of this approach is that ASCII stays ASCII. It is nice because the reality most strings are effectively ASCII and then remain ASCII which is a space saving. The disadvantage is that characters can occupy a variable amount of space; if you want to index them you don’t know where the characters start anymore. For most indexing, this is not a big problem, but unfortunately for code search, it is.
Why bother? We can still just make trigrams out of Unicode characters and look for their indexes. This kind of works, except that there a catch. Suppose that you are not searching for the temperature of 50 Celsius max, but you are searching for 323 Kelvin max. So if you are using Unicode, you could be looking for the lowercase k the capital K or Unicode symbol 212A which is the symbol for Kelvin degrees. It turns out that the Kelvin symbol takes 3 bytes, and so if I am looking for the string over here I want to look for “tem” and “max” but what distance do I pick? Because if someone is using Kelvin in Unicode, the distance is 12 but if I use K the distance is 10. The scheme isn’t working anymore.
I changed the triagrams to work with Unicode. I have used 64bit, and the three times 21-bit is 63 which fits nicely and works efficiently for all the offsets regarding Unicode code points.
So if we take the example earlier, we have Egyptian character and the “poo” emoji. So you can still search using this table over here, you can find where concerning Unicode code points the string is. If you want to use the actual comparison you need to find the offset in the file in bytes so that you can start making the real string comparison. So we have an extra table with the offsets with the mapping between the Unicode code points and the corresponding bytes offsets. You can see that the codepoint at offset number 6 is at byte 9, and so, it works!
Zoekt hosted by the Bazel project
I’ve put this on a machine that is hosted by the Bazel project, so it runs on the Google Cloud infrastructure on https://cs.bazel.build. As I work at Google, this is also nice because I can understand what customers go through when they want to use our products. Deploying is always good because when you need to start using your software for real, you then find the actual bugs and the real issues.
Code Search and Security
Of course, Google is a company that takes security and privacy seriously. Zoekt is a project that I do for fun, spending a couple of hours of free hacking time once a week and I don’t want to have any trouble with security.
One way to get into trouble is to set Cookies on your site, and then you’re subject to various laws in various countries, multiple lawyers will talk to me, and I don’t want that.
Another way to get into trouble is to have a security breach. If you do something that compromises the machine and opens it up to bad people, bad people to bad things with it and then other people from Google come to me and make my life difficult, and I don’t want that. Does anybody recognize this image? As a cultural reference, this is an image from “The Matrix Reloaded” where Trinity uses an existing exploit from SSH to access to the power grid of The Matrix. One of my personal goals is also to not be in any movie where the bad guys try to get in: don’t be implicated with bad guys in the film.
Threat model
What do I have that people want to steal from me? In case of a code search engine, if you’d be indexing private code and someone would want to leak that code; in this case this is not a problem since I am indexing Open Source code, so it is all public.
There is an SSL key to keep the traffic going securely so if someone steals that key and can make a man-in-the-middle attack and show source code that subtly different from the real thing and how bad would that be? In my case, this is not a problem because the Google Infrastructure provides the load balancing. You upload your private key into the load balancer, and then the only way to compromise it is hacking your Google account which is very well protected.
There is an access token needed to get the code into the indexing machine for processing. In my case is a GitHub public token, so it is not a big deal if it is getting lost, but possibly Google will get very upset with me if that is getting misused.
Finally, if you can get access to the machine, you can do any of the above. You can use it for other attacks, to mine bitcoins and to do many different bad things. Again, I don’t want these things happening because people come and speak to me, talk to my manager and I don’t want bad things happening to me because of a project that I do for fun.
So, how would you get into such a system? The search engine itself is written in Go, which is a memory-safe language. The worst thing you could do is to make it crash and then it gets restarted again. So no big deal. But there is one part of the search engine that is important which is the thing that provides symbols. When you are looking for something you typically want to have the definition of a symbol. I am using a problem called ‘ctags’ for that, and this is a problem written in C that parses lots of languages. It understands where the identifiers definition are so that I can get better search results.
But CTags is written in C and if someone would have control to the source code that I am indexing could create source code that looks suspicious and maybe exploit some error in this hundred of thousands of lines of C code.
For example, the ANSI C standard says that identifiers can be at most 32 chars. I hope they didn’t do it but suppose that CTags used a fixed buffer size for that and someone creates a commit that introduces this variable that overflows a buffer. Then it may overflow the buffer and try to dial a four pin number: that would be bad.
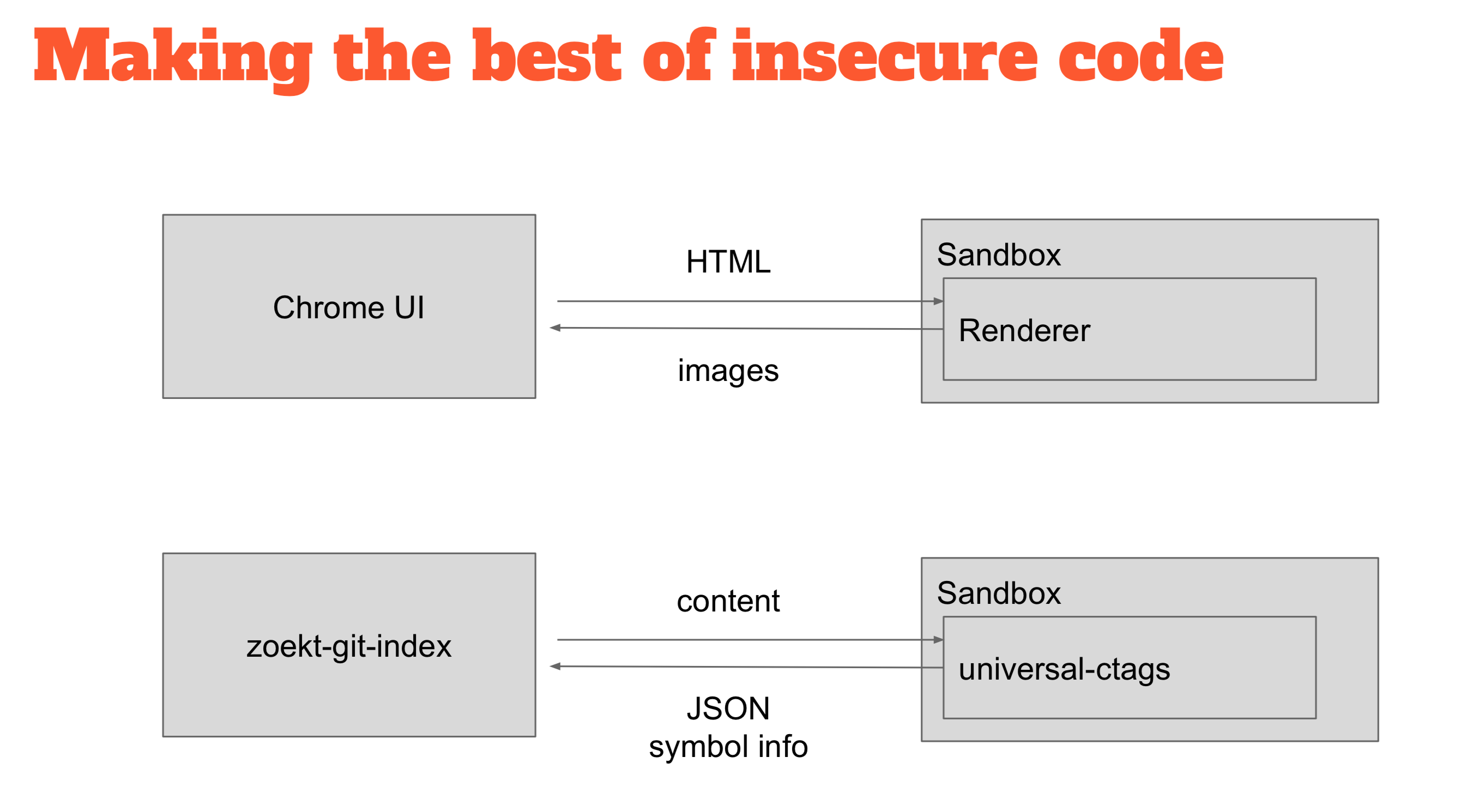
So how do you deal with that? You can take inspiration from other projects, which have the same problem, so Chrome, for example, is one of the most secure browsers out there because it uses sandboxing. So the part that renders HTML which is entirely untrusted is put inside sandbox where they can do almost no damage.
If you find a problem in the renderer that you can exploit, then you’ll find yourself in a place where you cannot do any damage. I have used the same technique for the indexer. I run the untrusted binaries inside the sandbox, I ship the content to the CTags binary, and the CTags binary responds with JSON containing the symbol definitions.
It uses seccomp which is available only on Linux. You start the program by declaring what system calls it can do, allocating the memory, providing the input and you then get the output. When you exit there is as well a system call that, if you can forget to exit from the process, it will automatically kill the sandbox. All of the above is all done by seccomp.
As you can see in this picture, I am now peacefully sleeping because everyone is secure and I don’t have to worry about anything anymore.
Gerrit ACLs
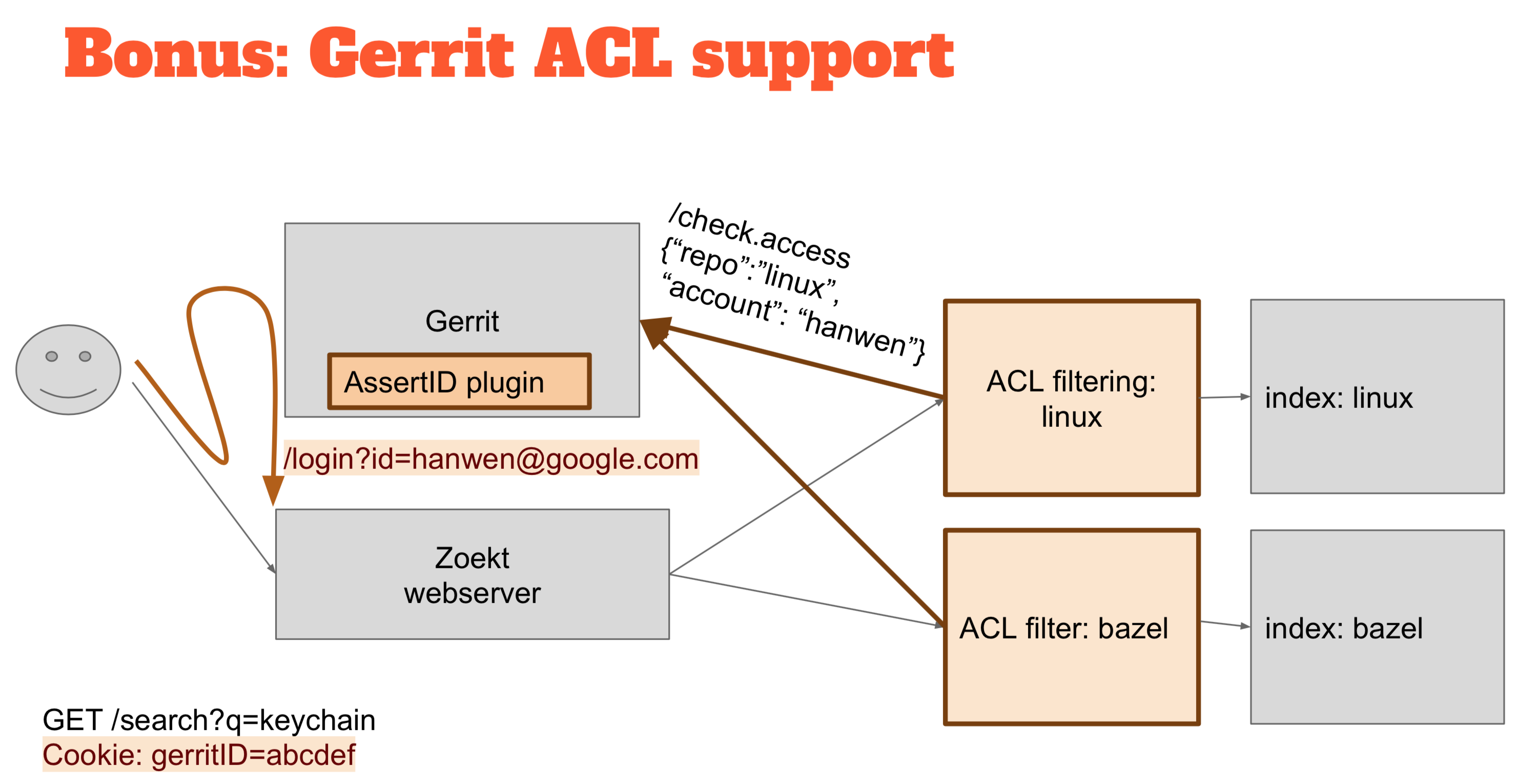
We had a hackathon yesterday, and I have thinking about this idea for a while, and I thought that I would have to go to tackle the Gerrit ACLs integration during those days. The overall ACL model in Gerrit is very sophisticated, so the only way to understand if someone can read a piece of source code is just to ask Gerrit “can this person see this source code?” A component of the solution is an ACL filter in the middle when you contact a web server to search something you typically start on the Web server and then it looks at all the different indexes to ask for a search result.
For the Gerrit support, I’ve put something in the middle that if you want to search for the code, it asks Gerrit if that person has permissions to read that code and to be able to execute the search. If the person doesn’t have the permissions, you just don’t return any result.
Gerrit SSO
So how do you know who the person is? I added some HTML magic that in case you don’t have a specific cookie you go to Gerrit and there is a little plugin that redirects back to the web server. So the plugin knows who you are on the Gerrit domain and using a redirect can tell the Web server your identity.
I am the administrator in Gerrit, as you can see over there on the top, and so if I go to Zoekt, then you can see in the corner that I am an Administrator there as well. That goes very quickly because now runs locally, but in reality, it does a redirect to Gerrit, and then Gerrit sends a redirect back to Zoekt.
If I want to search for things, I can find results in the “secret” repository. So if I now were to log out from Gerrit, there is another redirect to make sure that I am also logged out from the Zoekt, and now if I try to access the search engine I got “how no, who are you?” you have to authenticate.
I can now become another person, logging in as Rebecca; looking at Zoekt, I am Rebecca as well. If I try now to search for the treasure in the “secret” repository, hopefully, it doesn’t work: so “no results” right?
That is how ACL support could work, regarding the overall idea on how to make this work, the piece that goes from here to there was a little bit complicated, but I think it is a decent idea. The plugin in Gerrit that does this redirect is quite hacky, and in a real deployment, you have to integrate to whatever authentication system people have on site.
I don’t know how LDAP works and so if anyone is interested in this and wants to have this, and there to make it work but then need some help on how to integrate with external authentication providers.
Questions
Q: (Martin Fick – Qualcomm) How do you envision this working by knowing Projects and Branches that users can use and be doing in a performant way in case they can’t read most of the information on the server?
A: The ACL filtering can cache that information, and my idea is that all pre-loading of ACLs can be cached to whether the user has access to it or not.
Q: So only at the repository level? Not at the branch level?
A: So this check access endpoint, I added it because we had people misconfiguring their Gerrit server leading to confidential data being leaked. People should test this so I made it so that people can pre-verify that people had no access to it has support for branches as well, but that part has been left off the slides though.
Q: So from a performance standpoint. Suppose you have a large amount of stuff you can’t see, would you be taking into account what you is authorized to see before you run the query?
A: Yes, it happens before the query goes into the index. So if the person has no access to it, you skip the search for the piece of data that person has no access to it.
Q: So if on the other side they have access to a lot of things and a lot of refs, then the filtering may be slow on the frontend.
A: Wow, this is basically what I have implemented in two days. Real life tests would be helpful. I would love people to try out and tell me how well it performs, so, let me know.
Q: So, does that mean that index is done once and access control is done afterward. So that indexing is not dependant on the access.
A: The indexing is usually done off-line on a cronjob because it generates a lot of data. The entire point of the indexing is to make the online search queries very fast and not doing the indexing when the person is looking for the document.