TL;DR
In 2025, GerritForge solidified its leadership in the Git ecosystem by securing TISAX certification and patenting our Git At High Speed (GHS) technology, proving our commitment to enterprise-grade security and performance. However, the rapid industry shift toward “Agentic Software Development” has created a critical challenge: current infrastructures are struggling to convert high-volume AI code generation into measurable business value, often leading to repository slowdowns and inflated costs rather than faster releases.
Our 2026 roadmap directly addresses this “ROI Gap” through a new “Assess, Measure, Improve” framework. We are launching GHS 2.0 to scale Git specifically for AI traffic, introducing server-side autonomous agents via the Gerrit Model Context Protocol (MCP), and deploying cross-platform metrics to monitor Git repository health in real-time. This strategy ensures your SDLC infrastructure not only withstands the load of AI agents but also integrates them securely to deliver the efficiency your investments demand.
2025 in Numbers

Our commitment to the open-source community and our customers is best reflected in the sheer volume of work our team has accomplished over the past 12 months.
Changes contributions to the Gerrit ecosystem
- 748 commits across 43 projects, driving the Gerrit project forward.
- 7 authors contributing consistently to core and plugin development.
- 21 releases delivered, ensuring stability and new features for our users.
- 14 talks given at international conferences, sharing our expertise with the global dev community.
- 9 GerritMeets & Conferences sponsored or organized, fostering a vibrant local and global community.
GerritForgeTV: the live stream of the gerrit community
Our YouTube channel keeps being a central knowledge and stage for showcasing the most recent innovations for Gerrit administrators and developers. This year was no exception; we kept updating it with new and engaging content and keeping it relevant to the latest trends in the Git and VCS world.
- 22 new videos published, staging key international speakers from some of the largest companies in the world, including Google, NVIDIA, Qualcomm and GitLab.
- 126,483 impressions in the last 12 months.
- 807 total watch hours, proving that the demand and interest for high-quality Git and Gerrit technical information and innovation is stronger than ever.
Major Successes & Milestones
GHS: From Vision to Patented Standard
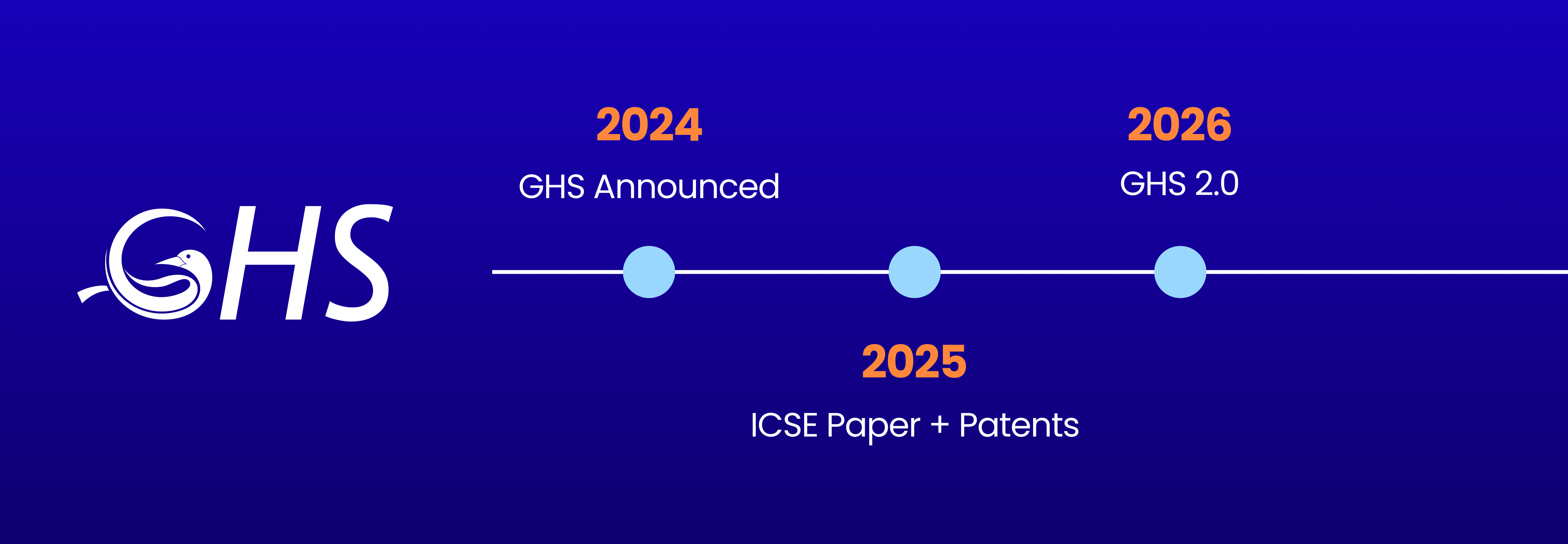
In 2024, we announced Git At High Speed (GHS); one year later, we delivered on the initial promise of groundbreaking Git performance speedups and brought Git performance to the next level. We are proud to announce that GHS has now been officially submitted for US and EU patents. Furthermore, our commitment to scientific rigor led us to present the GHS Paper at ICSE 2025, where it was recognized by the global Computer Science Academic Community as a significant advancement in improving Git SCM performance.
Gerrit community Growth and stewarship
The GerritForge team remains central to the Gerrit project. This year, our team member Ponch was elected as a Maintainer, bringing the total to five GerritForge’s Gerrit Maintainers, on top of that Luca was re-elected to the engineering steering committee, and Dani to the community managers. GerritForge’s deep involvement with the Gerrit Community ensures that our customers’ needs are always represented at the core of the project’s development.
Security and Compliance: TISAX Certification
In 2025, we reached a significant milestone in enterprise trust by achieving TISAX certification, which is key for every software supplier to the modern Software-Defined Vehicles industry. For all industries, security and compliance are non-negotiable. Achieving TISAX certification represents our commitment to the highest levels of these standards.
Product Evolution: Gerrit BSL
For 17 years, GerritForge has operated on a 100% open source model. However, the landscape of software development is changing. Cyber threats and supply chain security compliance require a level of certification and long-term maintenance that the pure open-source model struggles to address on its own.
We introduced Gerrit Enterprise, a subscription carefully designed to shake up the Gerrit ecosystem:
- The “Open-Core” Vision: We have separated the “Gerrit Core”—which remains 100% open source under Apache 2.0—from our high-performance enterprise plugins, which are released under BSL.
- What is BSL? The Business Source License is a “source-available” model. It allows for public viewing and non-production use, but requires a license for commercial use.
- Commitment to release as open source: An essential part of our BSL is the fact that after 5 years, any BSL-licensed code from GerritForge automatically converts to Apache 2.0. This ensures that while we fund today’s innovation, the community eventually benefits too.
- Want to know more? Read the full announcement, which includes the list of plugins and projects released under BSL in 2025.
This move will provide a sustainable path to continue investing in the Gerrit core platform, its ecosystem, and the community events we all rely on to keep the project alive and thriving.
Community Events take center stage

The Gerrit User Summit 2025 has been one of the most successful events in the whole 17 years of the project’s history, thanks to the co-location with the OpenInfra Summit 2025 at the École Polytechnique of Paris and partnership with the OpenInfra Foundation. We saw fantastic participation from partners like the JJ community, GitButler, and GitLab, signaling a more integrated Git ecosystem.
We also had the most successful GerritMeets to date, dedicated to the Code Reviews in the Age of AI, hosted by Google in Munich, reaffirming Gerrit’s vital role in large-scale professional software development and its integration with the latest AI technologies to improve and accelerate the entire SDLC.
Paving the Way with AI
The future of Gerrit Code Review is happening now. In 2025, Gerrit Code Review v3.13 released a suite of new AI features and tools, including the brand-new MCP (Model Context Protocol) server open-sourced by Google. These tools are the foundation for a new way of interacting with code, paving the way for deeper integrations that make software development and code review faster and smarter.
Looking at 2026: the future is now
All the evolutions we saw across major industries in 2025 are reshaping the landscape of Git and the entire SDLC. The introduction of “Agentic Software Development” has created shockwaves across the industry and changed how we interact with and use these tools.
Using AI chats to vibe-code, cooperating and orchestrating AI Coding Agents, and generating and reviewing code automatically put tremendous strain on all the existing machinery that was never really designed to perform and scale at this rate.
All the major companies in the SDLC are looking at developing and leveraging LLMs in their products, adding the AI vibe to their product lines; however, there is a lot of work to do to make this generational transition to AI really work for everyone.
- Productivity vs. Output Gap
AI tools provide significant productivity gains in code generation, code review, debugging, and testing; these improvements do not always translate into faster release cycles. - Developers’ Productivity vs. Actual Changes Merged
Engineers using AI tools are saving time in some of the repetitive coding tasks, such as prototyping and scaffolding. However, the generated code often gets stuck in the validation queue and does not become a valuable company asset until it is properly merged. - The Promise of High ROI from AI
According to a recent Deloitte study, very few AI implementations across the entire SDLC deliver significant ROI. Progress is hard to measure, and the majority of organisations with substantial AI spending still fail to achieve tangible benefits.
Only 6% of projects see returns in under 12 months, whilst most will take at least 2 years of continuous investment. - Agentic AI Future vs. Reality
Agentic AI has been made possible by increased accessibility to the existing knowledge base and SDLC infrastructure by LLMs and promises a full end-to-end automation. However, only a small fraction of companies started using it, and of those, only 10% are currently realizing significant ROI.
GerritForge bridges the gaps between AI innovations and ROI
Our mission in 2026 is to help all organisations achieve the expected ROI from their AI investments by identifying and filling the gaps that hinder the success of their SDLC implementation.
The way forward is to engage with current and new customers and introduce new technologies and innovations into their existing infrastructure.
Assess, measure, improve, repeat.
We do believe that everyone can make progress and, at the same time, do more with the money they have invested in AI. We are truly believers that data is the only truth that can drive progress forward and on which everything should be based.
Our product plans for 2026 are all based on a smarter way to measure and improve:
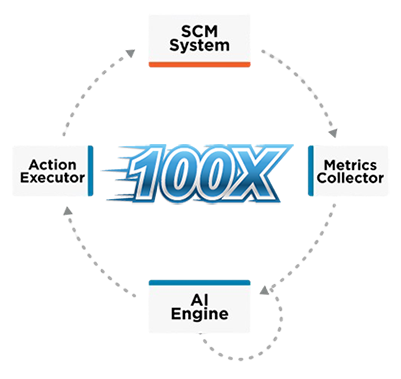
- Real-time metrics collection from Git repositories
We will introduce a brand-new real-time data collector, based on the 3 years of R&D and investments made on repository performance, published at the ICSE 2025 in Ottawa (CA). The new component will be able to detect and advertise any repository slowdown caused by AI.
The component is planned to support GitLab, GitHub Enterprise, Gitea, in addition to Gerrit Code Review, and is extendible to all Git-based SCM systems. - Native integration of Code Review experience with LLMs
Gerrit Code Review v3.14, planned to be released in Spring 2026, will introduce the _”AI Chat”_ with any LLMs. GerritForge will take native support to a whole new level, enabling end-to-end communication and integration with Google Gemini, ChatGPT, and many other popular LLMs.
- Agentic Gerrit Code Review
Gerrit MCP, now Open Source, helps developers improve their client-side integration between Gerrit and LLMs using their own credentials. GerritForge will bring this paradigm to the server-side and enable real-life AI Agents to leverage Gerrit MCP for performing analysis and taking actions autonomously, without sacrificing confidentiality, security, and compliance.
- Scale up and save money with Git, thanks to GHS 2.0
GerritForge is bringing its GHS technology to a brand-new level, with all the experience and learnings in understanding the traffic generated by AI Agents. The new 2.0 will bring new modern actions and an improved learning model that will be able to react more accurately and bring system resources and costs into the ROI equation.
The future of Git, Gerrit Code Review, and the entire SDLC is now. AI has accelerated the race for innovation, adding speed to the competition. GerritForge is there with you, helping to endorse it and ensuring the whole pipeline will scale, and you can really achieve the ROI that makes your company stand against the competition.
Thank you to our team, our customers, and the incredible Gerrit community for making 2025 a year to remember. Let’s make 2026 THE ONE to remember as a turning point for the whole project, the Git ecosystem, and the community.
The GerritForge Team January 2026