TL;DR: GerritForge has been dedicating its efforts to organising and managing the Gerrit User Summit in London back in November 2022, in conjunction with the release of Gerrit v3.7. The event has been a great success, with a significant presence on-site and record-breaking attendees on the GerritForge TV youtube channel. It has also committed to its promises to research and improve the JGit and Gerrit scalability to large mono-repos, with tens of millions of objects and refs. 2023 will see the finalisation of these efforts with an increase in development efforts and a new JGit Committer for pushing the platform to a new level of performance and scalability and a new innovating system for collecting and optimising the repository metrics automatically. Stay tuned.
Read the full story here below (9 mins read).
2022 has been a critical year for turning the Gerrit Code Review community and development back on track after the COVID-19 pandemic. At GerritForge, we’ve been working hard to make sure that the development, support, and innovation of Gerrit Code Review continue on its main objectives.
Gerrit Code Review v3.6 and v3.7
We have continued to deliver on the development and release of Gerrit Code Review and its plugins, helping the testing and releasing of versions v3.6.0 (May) and v3.7.0 (November).

Some numbers of the past 12 months’ development contributions by individual committers and companies:
- 3,627 Changes have been merged on 76 projects related to the Gerrit Code Review platform, including JGit
- 113 committers from 42 different organisations
A special mention to the top #10 contributors: Google (Ben Rohlfs, Edwin Kempin, Chris Pouchet, Dhruv Srivastava, Frank Borden, Milutin Kristofic), GerritForge (Luca Milanesio), Wikimedia (Paladox) and SAP (Matthias Sohn and Thomas Dräbing).
In comparison with 2021, we had 25% fewer changes merged but with more contributors coming from more companies, which is a symptom to a very healthy and thriving ecosystem of maintainers.

GerritForge has committed to resuming the face-to-face user summits, which were suspended since 2020.
The Gerrit User Summit 2022 took place in London, UK the 10-11 of November in a hybrid format, with people having the opportunity to participate either on-site or remotely on GerritForge’s YouTube TV channel.
It was a glorious success, with record-breaking attendance from all around the globe:
- 50 people registered to attend on-site, 26 of them managed to arrive despite the London tube strike, whilst the others attended remotely
- 235 people viewed the summit on YouTube with an average view time of 40 mins (one talk)
The summit survey had an outstanding report showing a huge acceptance and appreciation of the event:
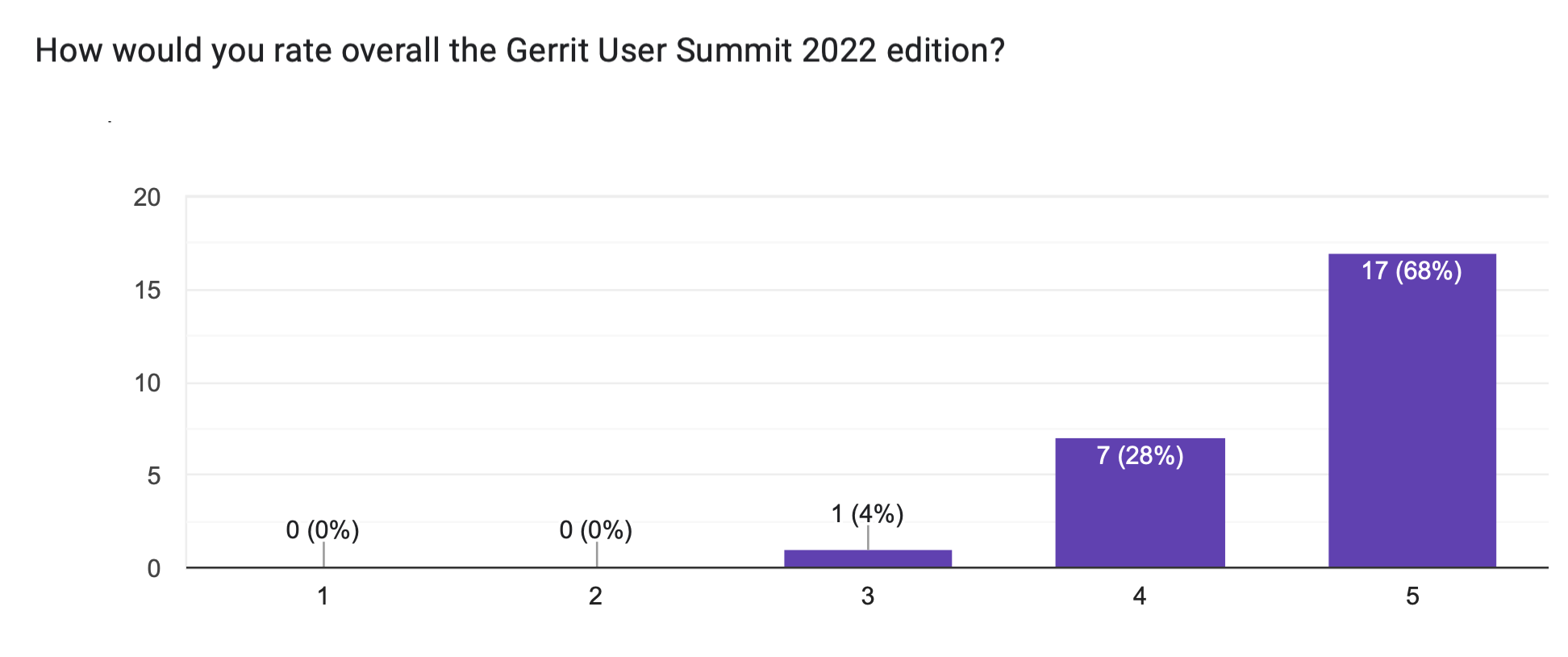
- 82% rated the remote video streaming as “good” or “outstanding”
- 96% rated the quality of the summit as “good” or “outstanding.”
- 100% would recommend the summit to a colleague, with 83% strongly recommending it
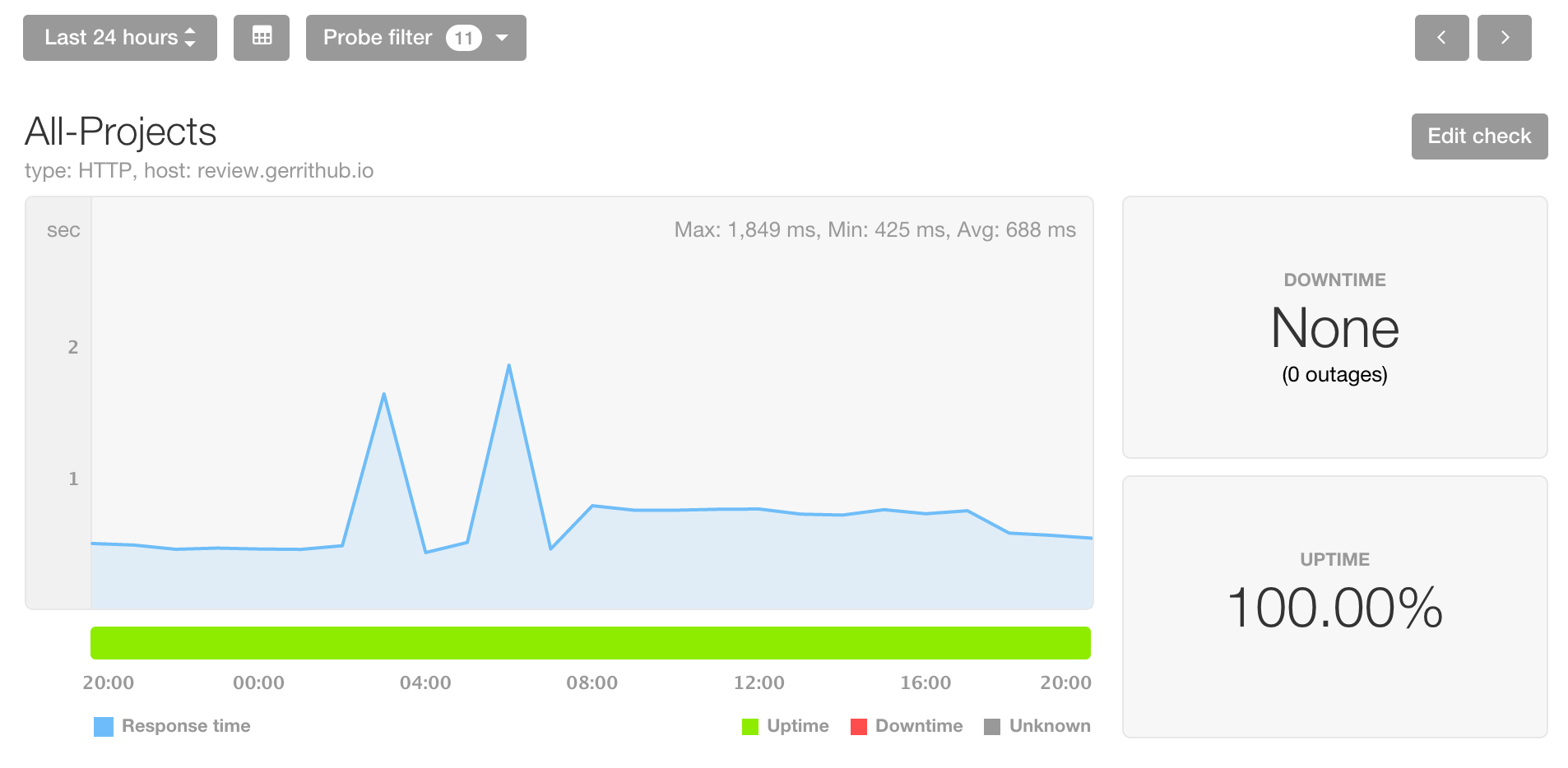
GerritHub.io SLA gets closer to five-nines.
We have been working hard to make Gerrit more stable and resilient throughout 2022, discovering and fixing many issues in the code base and on the multi-site software architecture.
In 2022, GerritHub.io had only six small hiccups for a total of 19 mins of downtime (SLA = 99.997%) over a 12-month period, a 75% reliability improvement compared to 2021.
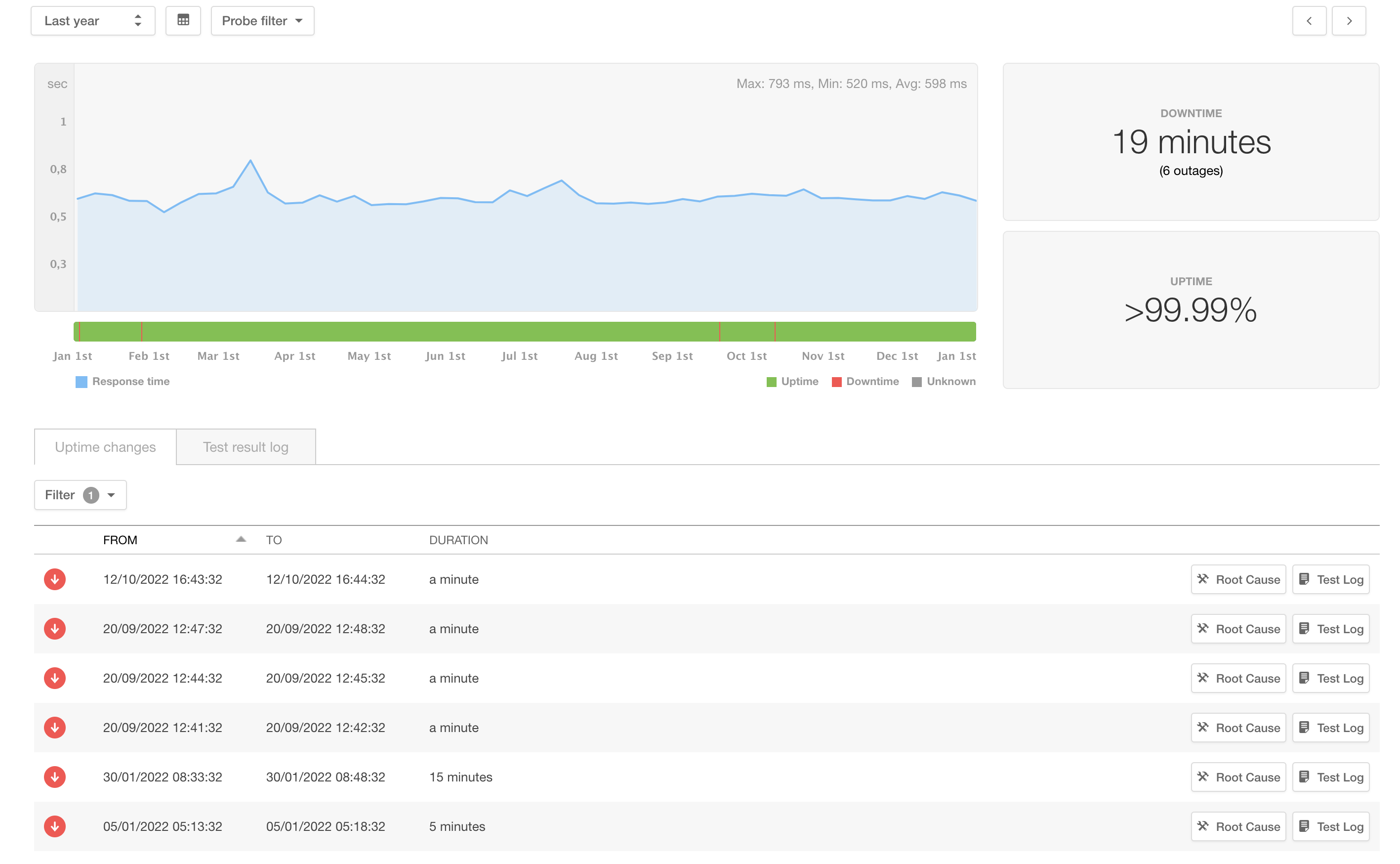
We have run extensive RCAs on the causes of the downtime and identified two leading issues, which are explained in the details below.
The “anonymous unlimited query” hole in Gerrit
GerritHub.io has been subject to a 15 mins outage because of anonymous users being able to bring offline all the sites before the system could auto-recover.
Gerrit allows bypassing of all limits set in the ACLs for running queries by simply adding the “no-limit” parameter.
Returning an arbitrary payload without limits could allow a single user to generate a server-side workload for collecting and building a GBytes-sized JSON payload; unfortunately, that option was available to everyone, including anonymous users making any publicly faced Gerrit Code Review installation subject to deny-of-service attacks.
We have identified the issue, reported and fixed it in Gerrit with Change 333304, which has been included in Gerrit v3.3.10, v3.4.4, v3.5.1, and all v3.6.0 or later releases.
More granular monitoring and alerting
We have lowered the threshold of uptime checks on GerritHub.io to 1 minute, giving us the ability to detect and react immediately to 4 smaller hiccups. We have detected a lack of scalability for some specific higher-load projects. Those hiccups have been responsible for 2 mins of downtime over the 2nd part of 2022. Many more projects are also planning to be onboarded on GerritHub.io; hence we do need to address this project-specific capacity needs.
Scaling Gerrit Code Review and JGit beyond its limits
We have been investing a massive effort in building a test environment designed to stress Gerrit and JGit to its limits and identify all the limitations and bottlenecks that prevented us from scaling further.

Scaling the test repository
We have created over the months some test repositories that increased in every dimension:
- Tens of millions of refs as both refs/changes and refs/heads
- Millions of delta-chains
- Tens of millions of Git objects
- Packfiles of tens of Giga-bytes and packed refs of hundreds of megabytes
For generating a significant load on both client and server side, we have invested more into the aws-gerrit cloud setups and gatling-git performance loading tool.
There were some “well-known” issues and additional surprising ones.
SHA1 complexity and CPU utilization for large entities
JGit has been used SHA1 for identifying uniqueness not just for Git objects but also for other large entities. However, computing SHA1 has become increasingly CPU intensive because of the relatively recent findings about collisions on shattered.io.
We have highlighted two major potential improvements in cooperation with Matthias Sohn (SAP) on the raw SHA1 performance and its application for detecting packed-refs changes on the filesystem.
Commit priority queues
JGit has a custom implementation of priority queues which are intensively used in RevWalk, which has almost quadratic complexity. That isn’t a problem for small to medium chains of commits; however, when the number of commits reaches millions, the performance degradation becomes unbearable.
We have replaced the JGit’s custom implementation with the one provided by the Java JVM library, which has a logarithmic complexity that massively improves its performance with large commit chains.

Unwanted reachability checks
JGit needs to perform a full reachability check whenever a remote unknown client is advertising refs, which makes sense when serving a remote client. However, the cost of full reachability of millions of advertised refs can be a daunting task that may be alleviated if the remote end can be considered trusted.
Fixing JGit bitmaps
Since the introduction of Git bitmap, the whole community has learned how key they are in speeding up the counting and selection during the clone phase.
However, large and unoptimized bitmaps could be so unhelpful for Git that instead of speeding up, they could represent a massive overhead for the system, causing CPU spikes and, eventually, lowering the throughput of the server.
Git bitmaps are compressed using the JavaEWAH library, which is good for memory consumption but evil for CPU utilization: that is the reason why the smaller is best for performance.
We have discovered and fixed a critical issue with the JGit bitmap generation that was causing the inclusion of all commits and BLOBs pointed by annotated tags. Also, we have introduced the ability to inform JGit about the heads that can be excluded from the bitmap, allowing to shorten the creation tens of thousands times (5h generation time for a 2k refs to as little as 60s) and increase its effectiveness by 200%.
Millions of unneeded ref logs
When performing a clone of a repository with millions of heads, JGit created one local reflog file for every remote ref, including the ones there were not actually cloned but just fetched as remote references. This was creating a significant performance gap between JGit and Git, which would instead lazily create the reflog files once they are effectively checked out the first time. Cloning a single branch of a repository with millions of remote refs took around 1h, compared to a few minutes of Git.
All of the findings were included in multiple updates on the following components:
- JGit changes: all fixes were also provided to stable-5.13, the last supported branch for Java 8, which allows benefiting from these improvements for older versions of Gerrit from v2.16 onwards.
- pull-replication went through major performance improvements, achieving a 1000x times faster execution time compared to the traditional replication plugin
- aws-gerrit is going through upgrades for making use of pull-replication plugin, including the support for the bearer token which allows to replicate virtually any repository, including All-Users.git
- gatling-git: we have upgraded the Gatling version and JGit to the latest stable-5.13 to include the latest performance improvements.
- git-repo-metrics: we have introduced a brand-new plugin that allows us to keep under control the major dimensions of a repository and therefore graph their increase over time.

GerritForge goals for 2023
We are definitely not done yet with the performance improvements on Gerrit and JGit: there are still significant improvements to be made, and JGit changes to get merged into the mainstream branches.
We believe we are on track to finalize the job and allow a stable and scalable platform for large Git repositories in 2023.
Finalise what we cooked in 2022 for JGit
JGit has a new maintainer, David Ostrovsky, awarded in 2022 as Git committer of the project. GerritForge’s devs are focused to get more reviews and attention to the JGit performance improvements. We are committed to finalising all the open changes related to large repositories.

JGit multi-pack indexes support
There is still a major gap between JGit and Git when dealing with very active repositories: multi-pack indexes. The proliferation of packfiles would eventually lead to a long and painful search-for-reuse phase for BLOBs which could be cut down 100s of times with a multi-pack index.
Git repository optimiser for Gerrit
We have been working on tracking the live information on the Git repository, thanks to the git-repo-metrics plugin. Wouldn’t it be nice to have a tool that can do something with it and automatically?
We would be doing R&D on how to correlate the repository metrics, the Git audit trail, and the performance data for making AI-based decisions on what needs to be improved on the repository.
This work stream is going to be useful for any Git repository, not just the ones powered by Gerrit Code Review. The ‘git-repo-metrics’ and the repository optimiser would also apply to other products, including GitHub and GitLab.
Gerrit v3.8 and projects-specific change numbers
We will finalise the design document for the transition to project-specific change numbers in Gerrit v3.8. That would allow the seamless migration of projects across Gerrit setups without having to worry about changes renumbering anymore.
Gerrit Code Review testing and GerritForge-certified binaries
GerritForge is spending a tremendous amount of time developing test environments and tools for serving the Gerrit community with more stable releases and improving the quality of its code. We want to intensify the effort and also offer our platinum support customers a unique service that includes the GerritForge digital signature and rubber stamp on the binaries of Gerrit Code Review and its plugins that have been successfully tested and validated for being production-ready.
Stay tuned; more details are coming soon …
GerritForge company forecast in 2023

GerritForge Inc. will finalise its roll-out to the USA, and all contracts and services will be run from Sunnyvale, CA and Europe. Over 2022, 60% of the customers and businesses have already been moved, and the operation will be completed over the course of 2023.
We are looking forward to doubling our revenue figures in 2023 and also our contributions to the open-source community, with a main focus on JGit as the driver of performance growth for Gerrit Code Review.
2023 is going to be an incredible year for GerritForge, Gerrit Code Review, and the JGit community altogether.
Happy New start of the Year 2023!
Luca Milanesio (GerritForge)
Gerrit Code Review Maintainer and Release Manager
Member of the Gerrit Engineering Steering Committee