Hi everyone, We are thrilled to announce the Gerrit User Summit 2026, taking place on November 9th and 10th.
This year, our event is incredibly special. Thanks to the generous support of Google, we are hosting the summit at their campus in Sunnyvale, California.
The Google campus in Silicon Valley is the birthplace of Gerrit Code Review: hosting the summit at the Moffet park campus makes it a true homecoming—the absolute perfect setting for our global community of contributors, users, and enterprise leaders to reunite, share ideas, and shape the future of code review right where it all began.
Gerrit meets Jujutsu (JJ)
In addition to our traditional, deep-dive Gerrit sessions, we are excited to expand our horizons this year by co-locating the event with the JJ (Jujutsu) user group USA.
Gerrit and JJ share a deeply aligned vision for the future of Change-based version control and a workflow that is ready for today’s requirements for Human + AI agentic workflows. We can’t wait to explore these synergies, showcase future integrations, and discuss how we can push the boundaries of developer productivity together.
REGISTER AND JOIN THE SUMMIT
We want to hear from you! Whether you are a long-time core contributor or a Gerrit / Git SCM administrator working on the enterprise scalability of your infrastructure, your voice matters, we would like to hear your story!
🎙️ Submit a Talk: The Call for Papers (CFP) is officially open. Share your success stories, unique workflows, and innovative ideas. Submit your proposal on Sessionize.
🎟️ Register & Updates: Secure your spot and find the latest agenda updates on our official website: gus26.gerritforge.com.
💻 Post-Summit Hackathon
The summit will be immediately followed by a 3-day Hackathon reserved for maintainers or long-time contributors. We are incredibly grateful to Nvidia for organising and hosting this at their nearby offices. More details and logistics will be shared on the maintainers’ mailing list in due course.
We look forward to seeing you all back again in Sunnyvale.
Daniele Sassoli – Gerrit Contributor and Community Manager Luca Milanesio – Gerrit Maintainer, Release Manager and member of the Engineering Steering Committee
It has been a hectic and productive year for ourselves at GerritForge and the Gerrit Code Review Community.
We want to take this opportunity to recap some of the milestones of the 2019 and the exciting perspectives for 2020 and beyond.
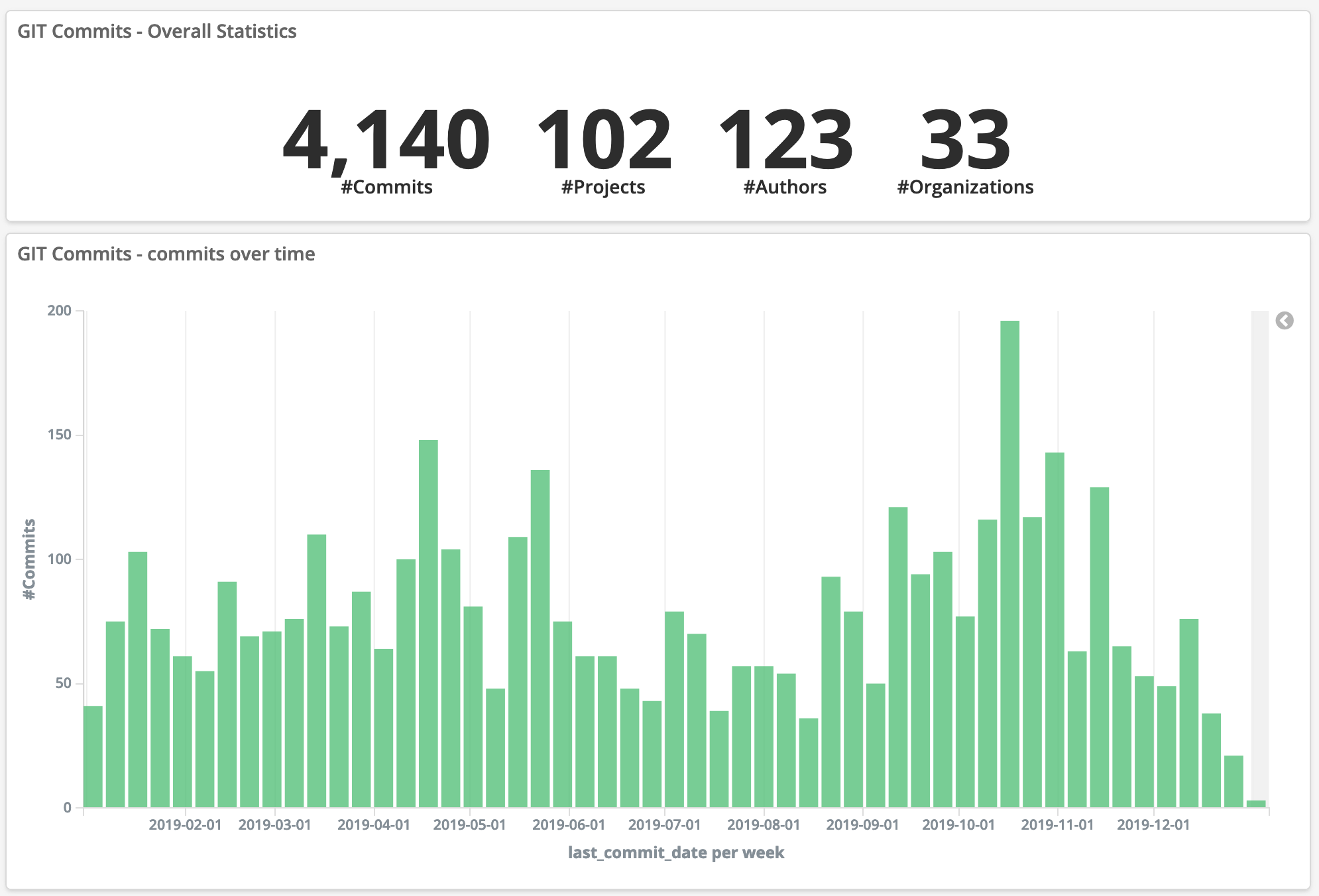
Gerrit Code Review, 2019 in numbers
Gerrit had over 120+ contributors from all around the world coming from 33 different companies and organisations, which is excellent. There is a robust 6% increase in the number of commits (+231 commits) but a reduction in the number of contributors (-7 authors).
With regards to the overall trend of commits during the year, the success of the Gerrit User Summit 2019 in Sunnyvale is visible, with an increase of the rate of commits around October/November.
Top-three projects of the 2019
Gerrit (1,626 commits) is, of course, the most active project. However, it is visibly down in terms of number of commits from 2018 (-19%). That is a consequence of the shift of focus to the other two key components listed below, which are available as plugins and then not accounted for the overall gerrit core repository statistics.
Checks (315 commits) is the brand-new 1st class CI integration API for external build systems, such as Jenkins and Zuul. It is incredible how in just 12 months it has become robust and fully mature. It is currently used for the validation of all changes on the Gerrit project.
Multi-site (234 commits) is the long-awaited support for Gerrit that everyone has been waiting for years. It is finally available for all active and supported versions (from 2.16+ onwards).
Top-three companies contributing to Gerrit
Google is, with no surprise, still the top contributor of the Gerrit project overall. It is basically stable from 2018 (around 43%) as a confirmation of the continued commitment to the project.
GerritForge is growing significantly in the contribution to the project, with exactly half of the contributions of Google. This is a significant result from 2018 with a 7% growth of involvement.
CollabNet is sliding to the 3rd position (it was 2nd in 2018) with a 3% decrease of contributions. As noticeable mention, however, David Pursehouse from CollabNet is still the number #1 maintainer in terms of number of commits.
Even if it is outside the top#3 contributors companies, SAP deserves a special mention for its continuous involvement in the JGit project, which is at the basis of Gerrit engine, and its fantastic engagement in improving the Gerrit CI system and integrating it with the checks plugin.
Top-three achievements from GerritForge
The outstanding results of contributions of GerritForge in 2019 have been focused on three major topics.
Gerrit multi-site, released and production ready
We released the Gerrit Multi-Site plugin, allowing seamless balancing in a distributed environment, a technologically highly advanced development, crucial for very distributed companies. See https://gerrit.googlesource.com/plugins/multi-site for more information.
Gerrit User Summits in Europe, USA and streaming
We successfully organised and executed the Gerrit User Group in Europe and the US. The event was very well received by the community with an overall attendance of some 87 on-site and 38 in streaming. Have a look at https://gitenterprise.me/2019/12/23/gerrit-user-summit-survey/ for interesting feedback on those from the attendees.
We opened our own local office in Sunnyvale, in the heart of Silicon Valley. A crucial move to better serve our ever-expanding US customer base.
Gerrit Analytics for the Android Open-Source Project
We kickstarted the Gerrit Analytics for the Android open-source project initiative: after the successful adoption of the automatic collection of code metrics on the Gerrit project (see https://analytics.gerrithub.io) the Android team asked GerritForge to start working on extracting the same metrics from their code.
What’s coming in 2020
Gerrit v3.2 is currently under development and it is planned to be released around April/May 2020. It represents a major milestone for the Gerrit project with the support for Java 11 and large JVM heaps, up to hundreds of GBytes. Gerrit v3.2 is definitely the release that everyone that has a big repository (mono-repos) should target as next upgrade. See the Gerrit .roadmap at https://www.gerritcodereview.com/roadmap.html for more details about the planned features.
More work and improvements on the checks plugin, with the aim of fully integrating it into everyone’s user-journey and their CI/CD pipeline. Our first blog-post of 2020 will be how to use Jenkins and Checks plugin together with GerritHub.io.
Multi-site and HA will become more integrated with Gerrit, with the aim of moving parts of their technologies (e.g. global ref-db) into JGit and thus used in Gerrit core.
The Gerrit User Summit 2020 will continue the experiment of cross-pollination with other communities, after the success of the interactions with the JGit and OpenStack communities in 2019. Bazel is the next target, as it is used as the de-facto standard build system for Gerrit and its plugins.
Again, Best wishes from your friends at GerritForge and looking forward to a continuing successful partnership in the coming years.
Luca Milanesio Gerrit Maintainer, Release Manager and member of the ESC.
The 2019 has been an exceptional year, with the introduction of the next generation of Gerrit Code Review v3 releases and the largest ever Gerrit User Summit in the whole history of 11 years of the project.
As a community we want to improve even further and make the project and the community even better. Collecting metrics has been key for the improvements of the Gerrit product and its performance and, similarly, collecting feedback from the community events is the key to grow and increase the participation and sharing of the experiences about Gerrit Code Review.
Survey results
We have run a survey directed to all of those who have attended the two Gerrit User Summits this year, in Gothenburg and Sunnyvale. See below the executive summary of the results.
Did you achieve your objectives at the Summit?
All of the attendees achieved their objective, which were different for the people, depending on their position and role in the community.
Getting the latest news of what’s happening in the Gerrit community and open-source product
Meeting the existing members of the community and welcome new contributors
Networking with the other Gerrit admin and users around the world
Influencing with ideas the future Gerrit roadmap
Overall, how would you rate the event?
Over 76% of the people rated the event very good or excellent. However, as we strive for improvement, there is a substantial 24% of of people that are looking for a better event next year.
What did you like/dislike?
The positives of the event have been:
Presentation of the Gerrit roadmap and associated discussions
Successful mix of topics, including Zuul and JGit
People, atmosphere, friendship and networking
High quality of the talks and content
The not so positive sides where:
The summit covering the weekend
Too focused on Gerrit contributors and admins, no space for users
There was too much people for the chosen location
The talks and discussions went over the planned schedule
How organized was the event?
89% of the people considered the event very well organized, whilst 11% are looking for improvement, possibly with a bigger venue and better timing.
What topics would you like to see covered next year?
Evolution of the User-Interface, roundtable with developers, user-journeys
Migration talks and discussions
CI/CD integration
Monitoring
Load testing
GitHub integration and pull-requests
Gerrit with large clusters
User-stories on using Gerrit
Would you like to have a workshop next year?
The vast majority of people would like the next year event to be more informative, including a workshop for learning some of the features of Gerrit Code Review.
What would be the best time for the Summit next year?
For the majority of people (75%) the best time for next year event would be two days during the week, rather than having it again over the weekend.
Thanks everyone again for attending the Gerrit User Summit 2019 in Gothenburg and Sunnyvale, and thanks to GerritForge, Volvo Cars and Google for sponsoring it. We are looking forward to seeing you next year.
The second presentation this week from the Gerrit User Summit 2017 is about PolyGerrit, the new Polymer-based UX for Gerrit Code Review, officially feature complete for Code Review in Gerrit Ver. 2.15.
I am going to talk about the development of PolyGerrit, why we are making PolyGerrit and what we’ve done over the past two years.
Arnab is going to present a new visual design we are going to start rolling out to googlesource.com, and to the next release of Gerrit.
Dustin is going to give some findings from the user research on the survey I believe that many of the people in this room may have received the questionnaire on Gerrit and have responded.
Established November 2015
commit ba698359647f565421880b0487d20df086e7f82a
Author: Andrew Bonventre <andybons@google.com>
Date: Wed Nov 4 11:14:54 2015 -0500
Add the skeleton of a new UI based on Polymer, PolyGerrit
This is the beginnings of an experimental new non-GWT web UI developed
using a modern JS web framework, http://www.polymer-project.org/. It
will coexist alongside the GWT UI until it is feature-complete.
That is the very first commit we did on the PolyGerrit project, it was founded by Andrew Bonventre from the Chromium project and the commit message summaries up pretty well.
The idea is to replace the existing UI based on Google Web Toolkit (or GWT) and replace with a new UI built on modern frameworks with straight HTML and JavaScript. Part of the innovation was just not to renew the UI and make it better but also for the Chromium project move to Gerrit.
Based on the Polymer Project
Polymer is pretty essential to PolyGerrit, and that’s why is part of the name. The Polymer project is not a framework but rather a collection of libraries and tools and components that have been developed by Chrome at Google. The idea is the build beautiful web applications on top of the standard web platform. Some critical aspects of the web platform that we use are web components which are built on top of templates that you can import into your HTML file and shadow DOM which is a way of encapsulating your stylesheets into your templates so that you can build reusable components.
Another significant aspect of the Polymer project is the collection of custom elements. They are organized into groups and given chemistry names. We use iron elements pretty heavily; they are the basic building blocks for HTML.
We are starting to use elements from the paper collection which are higher level UI elements that introduce material design. They look nice, they are high level and reusable elements. They let us focus on building code-review without having to rebuild everything from scratch.
Q: Can you explain a bit more on what material design means?
A. (Arnab) Material design is a new design language that Google came out of it in 2015. It’s a library of all the modern components with great look and feel.
Material design elements come with a lot of features like animations and smooth transitions which makes your UI more dynamic, it’s hard to show in slides all that dynamism.
Current status of PolyGerrit
We have been working on PolyGerrit for two years now, and in that time we got a lot of contributions from outside the project, we have a few dozens of contributors, checked in thousands of commits, and we closed almost a thousand issues from our issue tracker.
As far as I know, there is no other significant deployment of PolyGerrit outside of Google and GerritHub.io, but we have been having used in Google for a while, and we see 10k code-reviews a day involving PolyGerrit, at least on a workday. We have got a few major OpenSource projects using it, Chromium has recently transitioned to PolyGerrit, and brings up almost 2000 developers.
I’ve put some other recognizable OpenSource projects like GoLang and also the Gerrit project itself, where we configured gerrit-review.googlesource.com to use PolyGerrit by default. That helps us get early feedback on the functionality and the design of PolyGerrit.
Chromium migration to PolyGerrit
What about Chromium? It is a significant milestone for our Team, and I also think for the Gerrit project. The Chromium project has a very complex system for checking their code and for builds. They have built the system themselves and they used it to run their code-review system them as well based on Rietveld. Unfortunately, that is a sort of unmaintained instance of Rietveld running on AppEngine they did not want to use anymore and also it wasn’t scaling very well for them. There were even commits that they couldn’t review on that system because they were too large.
So a lot we’ve been working at that time, it was allowing Gerrit to come to a state so that Chromium could use it. Part of that was building a nice UI, and part of that was taking features they have been enjoying in Rietveld and bringing them over to Gerrit. Some of them are small things like user account statuses, so that you can tell people that you are not in the office and you can’t do code reviews this week, or having descriptions to your patch-sets so that you can explain what this revision means.
And also they’ve built a lot of new customizations, and they got us flush out a plugins API, and I’ll show one example here. So Chromium has a pretty heavyweight CI system because they have to build Chromium for a lot of different platforms and different architectures and they have a lot of incoming commits. So they need to find a way to verify that a commit that is coming into the code, actually works and in which order to check in those changes, so that is not breaking the build.
One thing that they’ve built for PolyGerrit is a plugin to add these elements to the screen for visibility to what’s going on in their system. The builds that are running for their commits, their status, often the flaky, so that by clicking on these you can see the output of the build. You can also use this UI to start a particular build and chose which architecture you want to run on or re-run things that failed. I think we should be building better integration to Gerrit for these sort of things because those are what big and small projects need, but it is cool that we can do these things with plugins as they are now.
What’s new in Gerrit 2.15 for PolyGerrit
Gerrit 2.14 was the first release that included PolyGerrit but it is just a sort of experimental preview, but that did work well out of the box. Since then, we have fixed a lot of bugs and added more features, we have converted the entire project to ES6 which for JavaScript developers makes their life so much easier and also makes the project more attractive to other contributors.
We made a lot of performance improvements in the application. For example, sometimes we have commits that have thousands of files, and we have to have a way to display them intelligently, we cannot just throw them on the screen. We needed a sort of new navigation for these kinds of things, and we have adapted PolyGerrit to work with any variety of commits of different shapes and sizes.
Some specific things we added that are kind of cute. PolyGerrit offers a reply dialog to manage your reviews, reply to comments, vote on labels, and submit that all as a single batch operation. We added some nice features to this reply dialog since Ver. 2.14, one is being able to preview how your reply will be formatted. Not just to show you how your answer is going to look like but now it renders in the same it would end up in the e-mail because we have HTML e-mails.
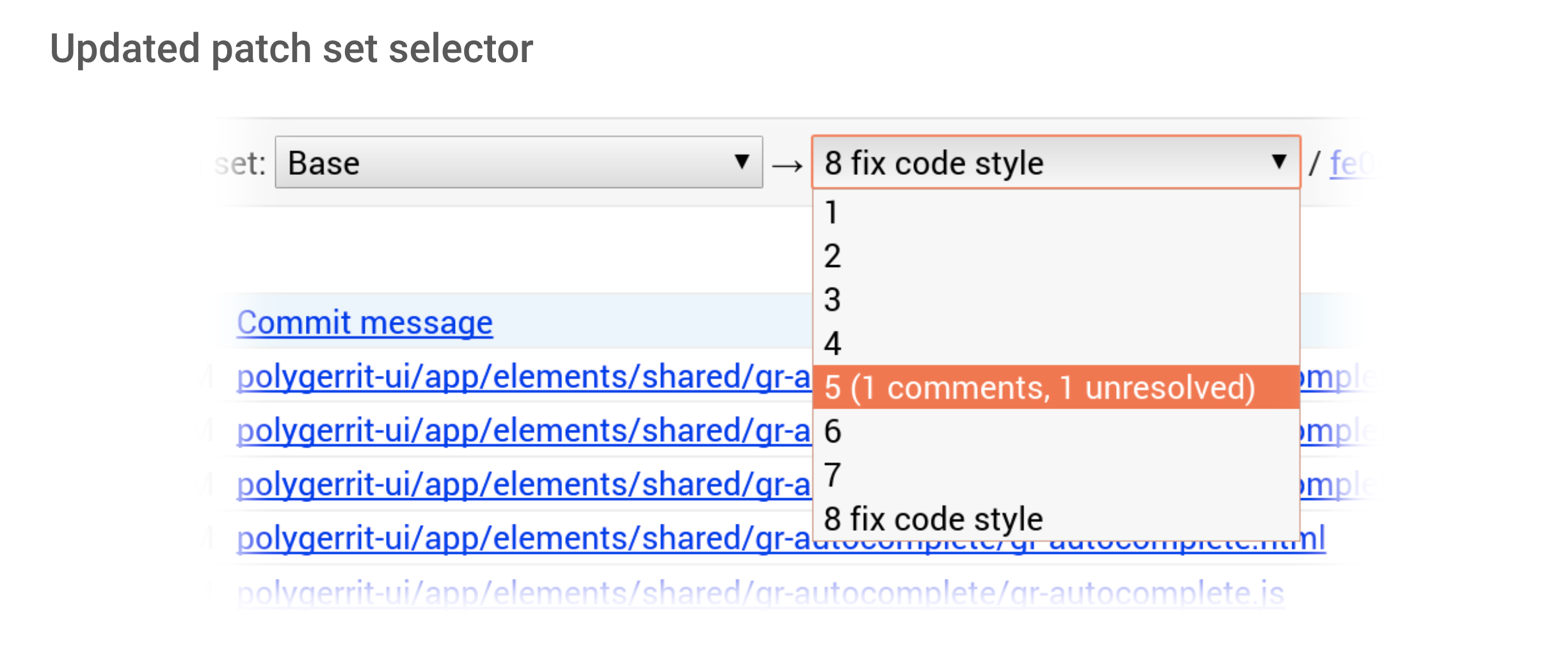
We have also reorganized how voting buttons are arranged, there is this beautiful vertical alignment, and you can see the labels that give you the meaning what +1 means for that label. We have a slightly updated patchset selector. That is important because one of the things people struggle with it is navigating a code-review. If there are more patches, understanding where the comments are can be challenging, because of comments land on different patchsets.
We also introduced the feature of resolvable comments, so that you can mark a comment as fixed or done and we can track that for you. You can see that on some patchsets there are some comments you haven’t reply to yet or has a review, and you can verify that everything has been addressed.
The PolyGerrit Admin UI
Another major area that we have been working at is one of the significant features that PolyGerrit has compared to the old version: the admin UI.
A lot of our users had to switch back and forth to do the admin work. We’ve been building up this part of the application. We have rearranged that a little bit, we changed the title by clicking on the browse link on the top menu. Our idea is that you can get to this like the project home page for a repository, where you have to check out instructions and is also the entry point for administering the project.
We have almost all the primary forms for managing groups and projects completed. We have also released a read-only version of the sophisticated project access rules editor. It is read-only mode because we don’t want anybody to risk losing their project.config because of a bug in this: project.config tends to be a very security sensitive thing.
What’s next for PolyGerrit.
We are still working on replacing the GWT UI; we’re getting close. One of the significant features remaining is in-line edit. We’ll be working on that over the next few months, as long as the long tail of the specific missing pieces of the UI. And then we are going to roll out a new visual design which Arnad will be talking about shortly.
We also want to do in the longer term more significant changes to the UI of Gerrit, to show how accessible is to the users, because when people learn how to use Gerrit they love it, but the initial learning curve is a bit difficult at the moment.
PolyGerrit UX New Look (Arnab Banerjee, Google)
We are working on a new look; I’ll just be giving you a quick glimpse of what it looks like. We know that Gerrit and PolyGerrit work very well for the users, but we want to improve its usability as well as the status of the tool.
For improving usability we think there is a long process. We don’t want to break what’s already working for you, and that’s why it will be more an evolutionary process based on user-research and feedback.
However, we started by looking at the aesthetics of PolyGerrit and giving it a new look. A few critical goal that we had is that design should represent what PolyGerrit is and stands for, having a more contained group of information in a way that you know exactly where to find a particular group of information. Also more consistent UI behavior across the board: as soon as you look at the component you see what you can expect what the element is supposed to do. Also, we want to introduce a more up-to-date style of components and fonts, which means: material design.
What should drive the experience we want to create is what we really want to achieve with PolyGerrit.
Confidence: we want you to be confident with the code you are submitting and is going out there.
Scalability: we want PolyGerrit to manage the small as the significant and more complicated change.
Efficiency: we want to increase the efficiency of your team as making the code review process more efficient.
Intelligence: PolyGerrit should be smart enough to do all the repetitive task that you otherwise would have had to do manually. Wisdom: PolyGerrit should be mean to share the knowledge on the team.
PolyGerrit is Blue
One color that captures all of that very very well is blue. So we picked blue and made the primary color of PolyGerrit.
That is going to be the default primary color but you can change it for your team.
That is the new and refreshed look of PolyGerrit.
There are three distinct layouts for PolyGerrit:
The change screen
Dashboards
Admin screen.
PolyGerrit new Change Screen
The change screen is the most used screen in PolyGerrit, so we thought why not start by giving this a new look.
For this presentation, I will just talk about how the new PolyGerrit style works on it. Let’s talk about the visual elements on this page and look at it with a little bit of detail.
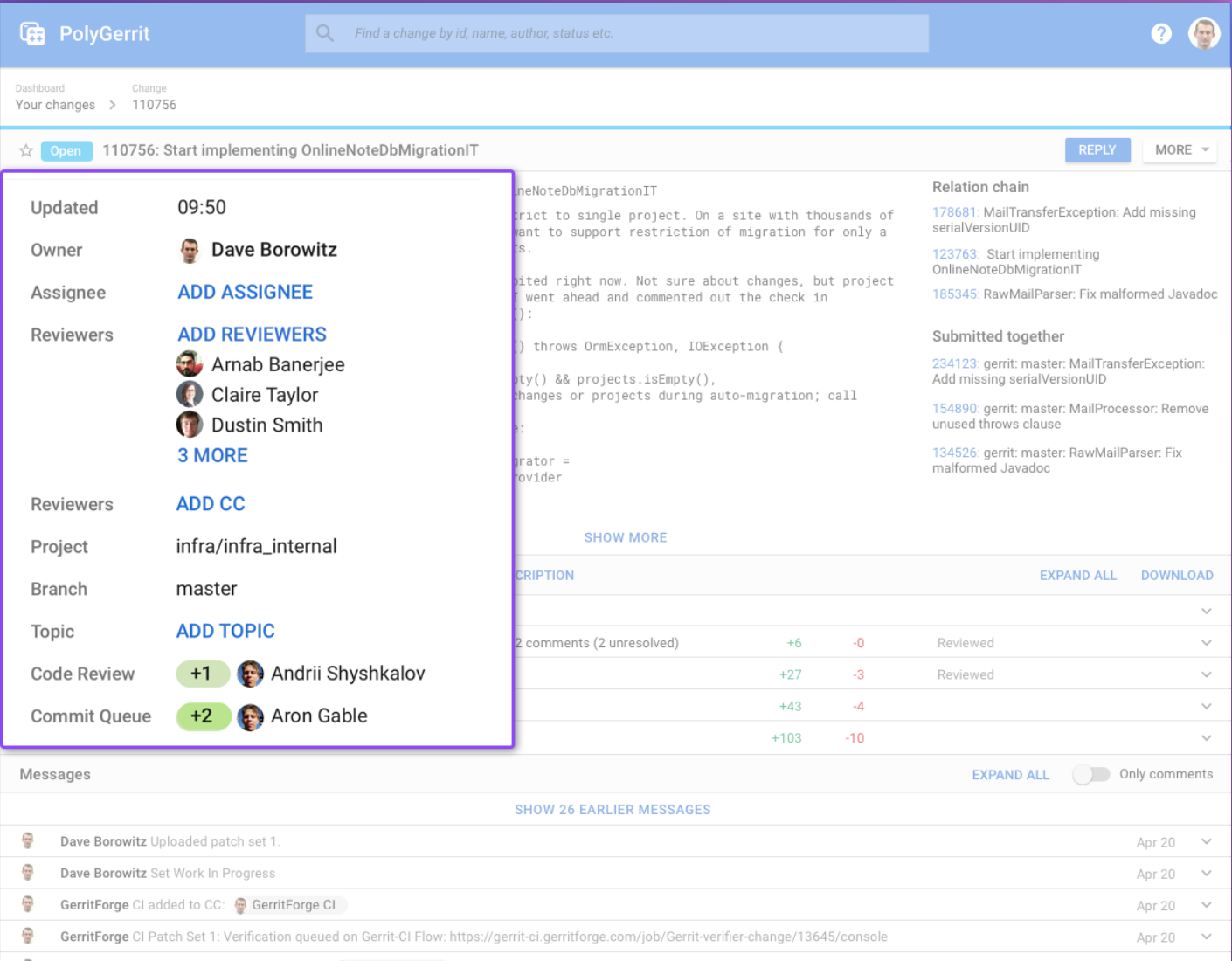
One of the things we have added in PolyGerrit is the breadcrumb where you can quickly jump back to wherever you came from. The next is the status, and now we have a clear status indication of the change so that just looking at this state you can understand if the change is it is closed or opened, and the color line adds to this the indication of the change.
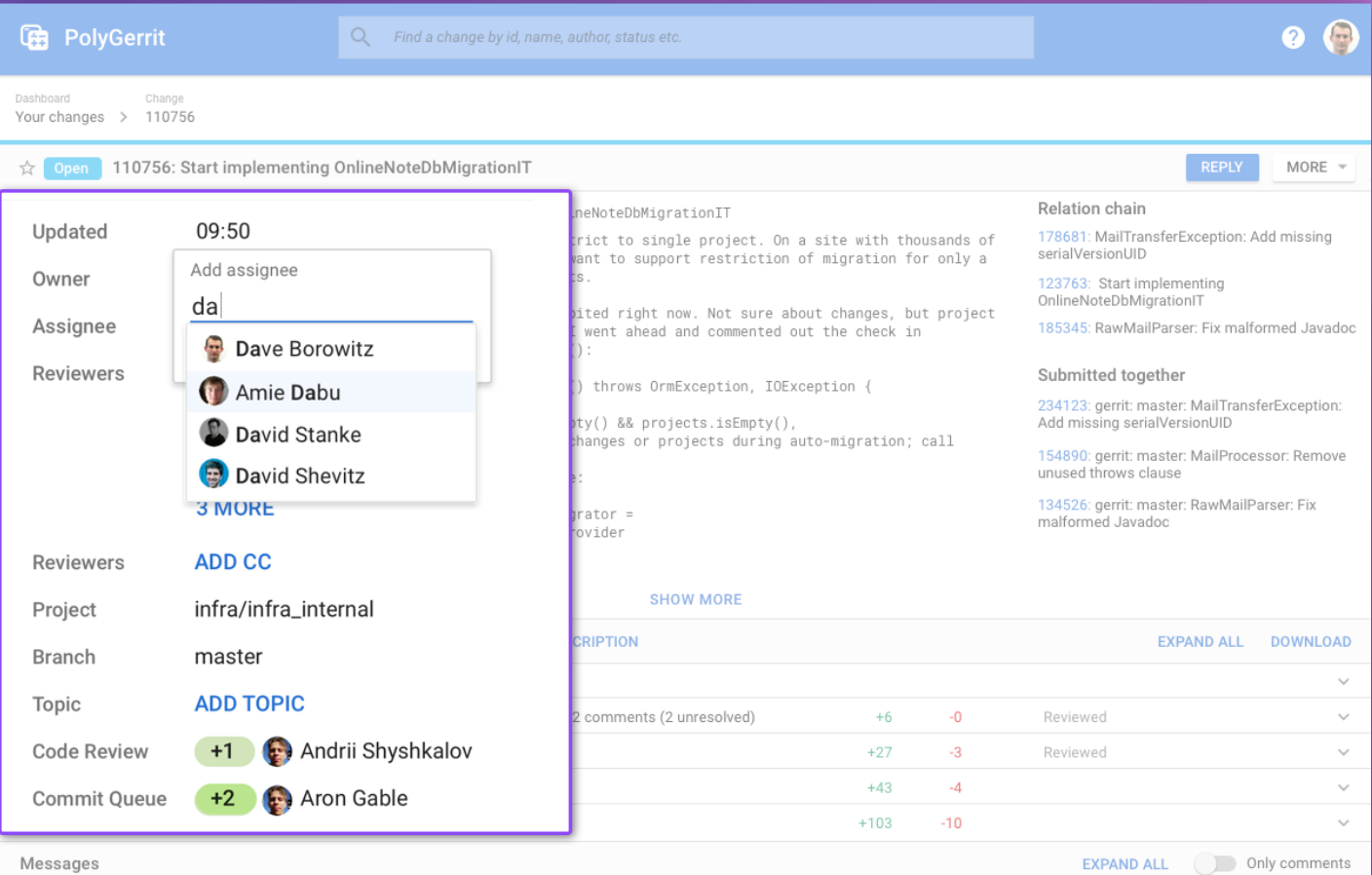
Let’s talk about the meta-data of this page, we have now a much more visual structure of spaces, fonts and colors and actions that are now material flat buttons, and they are different from links, which will be all caps and different fonts altogether. So visually you see the difference in what will take you to another space and what will take action. When you click on add assignee, you get this in-line box which let you add assignee, and this is just a more elegant way of putting inline data, it just makes the action so much more clear.
When you click save, you can see the assignee name populated and assigned to the assignee label.
Once you start typing will just suggest the names while you are typing and topics also work in the same way.
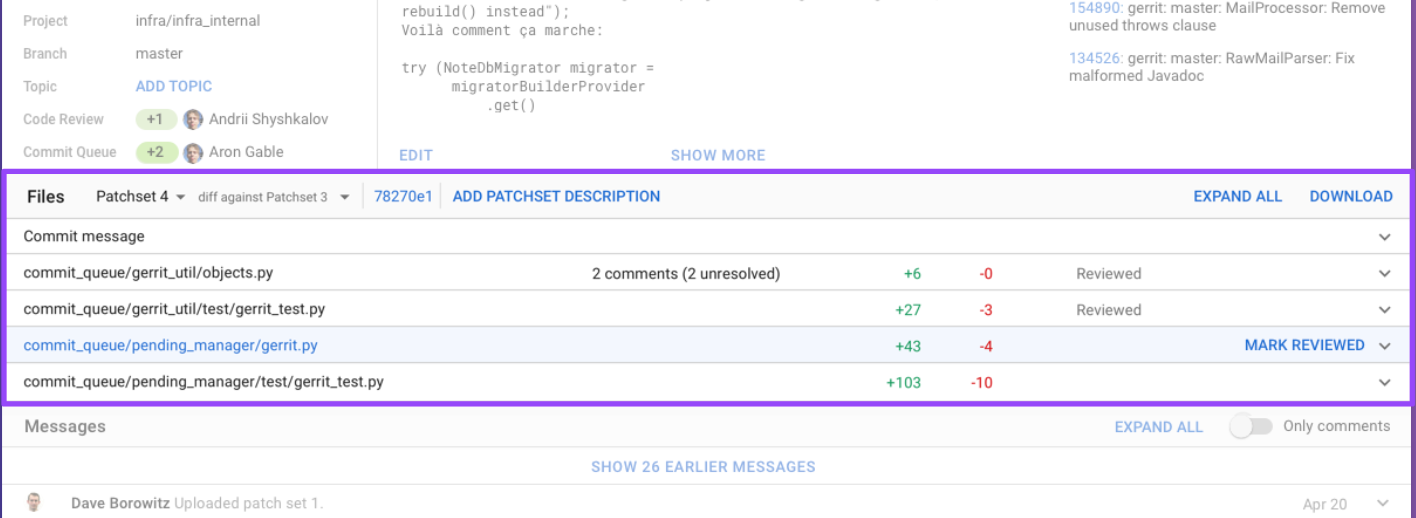
Now coming arguably to the most used section of this page which is the files table, and you may notice these two header rows, the file heading and we just combined the information of these two rows into one row.
Let’s look at the elements of this particular section. The first part is the patchset selector. If have both the selected patchset as well as the original patchset, you can see them together side-by-side, so that you don’t have to look all the way to the right to select the referenced patchset.
Once you click on the patchset dropdown, you have a different layout for this different drop-down menu. On the left side you can see the patchset as well as the patchset description, and on the right side, you can look at the comments and the unresolved comments. That makes scanning through this list so much more comfortable, especially if this list is long.
Then adding patchset description also works in the very same way. It just shows the inline edit box, and you just enter the patchset description and say “save.”
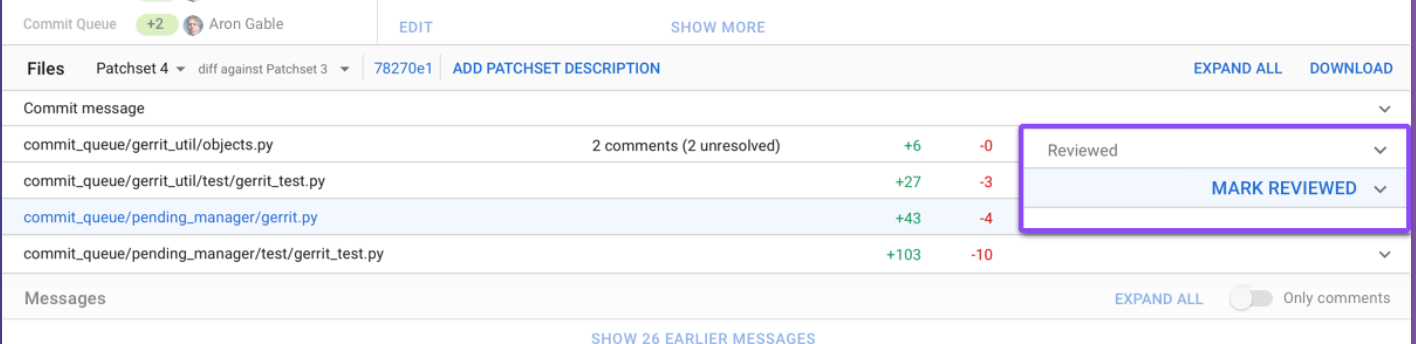
Now we have a separate interaction for marking the file as reviewed when you hover on this rows. The mark reviewed shows up on the right-hand side, when you click it you can see a column on the right-hand side of the mark as reviewed and when you click review this text shows up a toggle button.
On the top-right, we have now the table actions, and we just have two actions by default. The first action is “expand all” and the other is “download.” If you click on expand all you see this diff view expanded and you see some icons that appear on the top. So the “expand all” button changes into “collapse all” and you can change from side-by-side to unified diff-view or even change your diff-view preferences.
That is just a tiny step towards what we can do and is just the tip of the iceberg, and I think we’ll reach out to you for more feedback and do more user research for really making PolyGerrit a tool that you’d love as code-review tool.
PolyGerrit User Research (Dustin Smith, Google)
I am a user researcher at Google, and my job is to communicate with our users and take what you tell me and distill what we can do and what changes we need to do to our product.
Being an advocate for all of you in the meetings because I am not a developer I am not a designer and my role is mainly to communicate what you need to our developers and feedback them to our designers. I collect feedback and distill your needs. Arnab will come up with new designs, and we will come back to you and say “how did we do based on your feedback?” Then we will repeat that process to infinity, and that’s how research gets integrated into the design.
So if you are not a member of the Gerrit Google Group (repo-discuss) , I highly recommend you to join. You can yell at us there; you can say “I really don’t like what’s going on in the product, ” or you can praise us, whatever you like. At some point, you can send us surveys through there and hopefully not a very long survey that helps us aggregate all your needs.
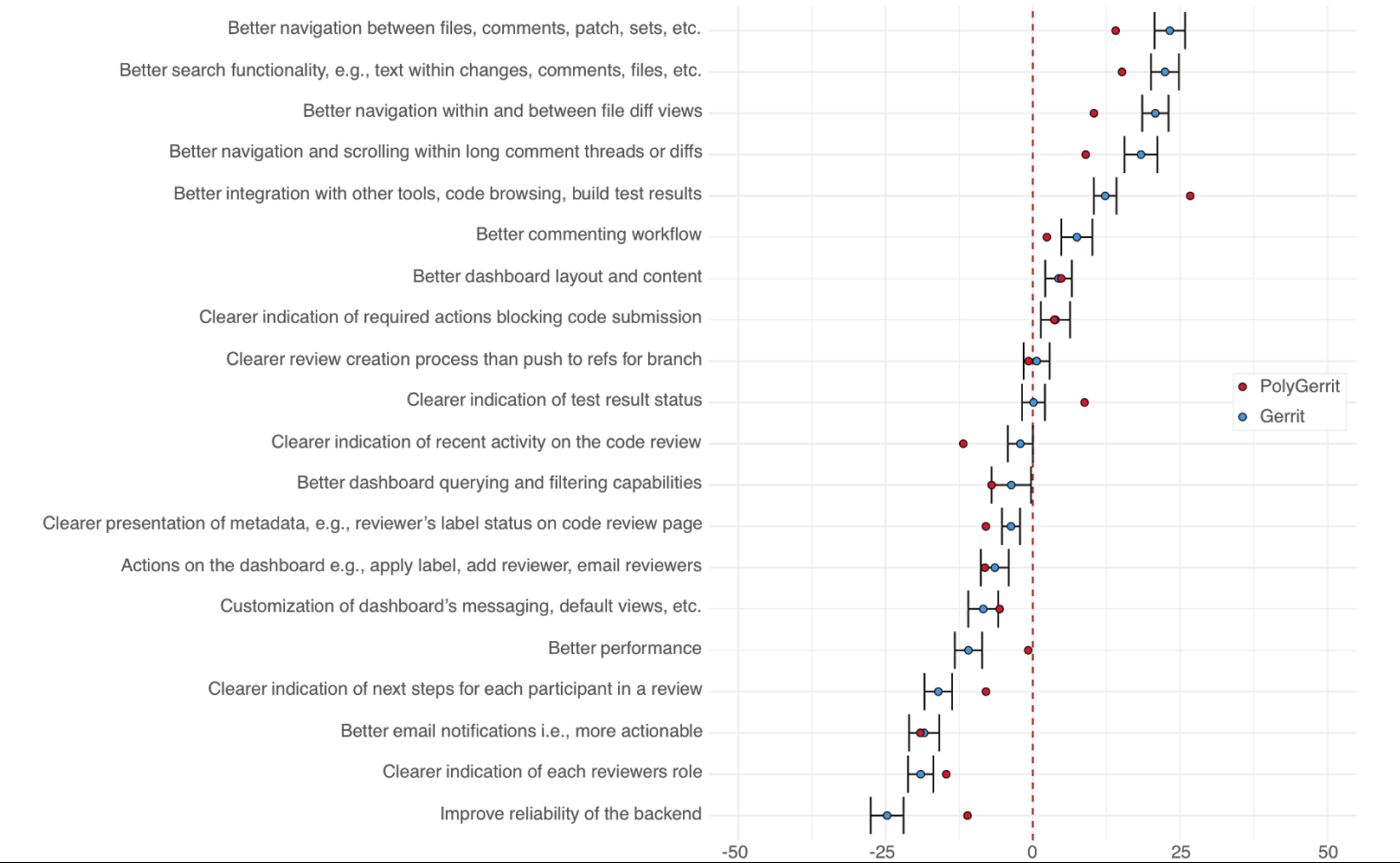
User Survey results on Gerrit Code Review
An example of that we sent out a survey in June and 600 of you responded. We received a lot of nice praise, and that’s great, but we’re also looking at ways to improve Gerrit, and we asked you to rank of what would be your priority.
What you see on the top here is that all the people that answered the survey is interested in improving the navigation of Gerrit, whether it is a patchset navigation, commenting, or other UI navigation. There is also another related to better integration with other tools. We are curing that feedback. Something to keep in mind is that even though there are things at the bottom that are ranked at zero, that doesn’t mean that you don’t want those things but they are relatively listed.
Q (Han-Wen Nienhuys, Google). I am wondering, who is in this group of users you asked because one of the things entirely at the bottom says “improve the reliability of the backend” and then very much at the bottom is “better performance” which is kind of what our Team is continuously worried about. Even yesterday we had a Hackathon and the friends from the Android Team on Sunday morning, and we were all in panic, but I see that “nobody cares about it,” how comes?
A. That’s a fair question, who did we sample? These users were external users of Gerrit, and only 13 of them were PolyGerrit users, so what you’re looking at here, 95% of them are external users. Having said that, why ranking better performance and reliability the lowest, I am not sure how to answer that question.
A. (Gerrit admin from the audience). For us obviously reliability of the backend is important, but the question was “does reliability need improving?” and for us, Gerrit works quite well and we are very happy with it.
A. (Luca Milanesio, GerritForge) I believe that my is very similar to that. First of all, the people you are aking to. You’re not asking Gerrit administrator, but just people that are using as a UI. The people that are using the GUI are saying “reliability is currently 99.99%, do you need to make it 99.99999%? Not really”. What needs improving is what you guys are focused on: usability, discoverability, and leveraging all the power that is out there.
A. That’s a great point and keep in mind that all the items on the bottom of this list don’t mean that people don’t like them just that other aspects that need improvements are ranked above it.
People did not say “I dislike the idea of better performance, ” but more often than not, people selected the options above it before the better performance.
Other highlights from people, maybe people that is one of you, navigation is important “Getting an overview of the change I’m reviewing is hard. When a change is composed of several files, the file navigation feels like a pain”.
We are taking these feedback and then moving forward, and also some complaints about the search itself. The search could be better, for example, “I want to search a commit that includes a particular file.”
And then, integration. I would like more Jenkins integration for passing code coverage reports into Gerrit. If these quotes that I pulled out are jelly with you wonderful, if you like there are things that are missing and you are not being heard, I am the person to talk to. I need to make sure that you are heard. There are also some other options I am going to show you. How many of you are aware of userresearch.google.com?
PolyGerrit Research: call to action
If you’d like to, you can sign up here. What we will do is substantially having a look at the new designs, you can spend an hour with me, maybe 30′ depending on how busy you are, and I’ll show you some new designs, and you’ll get a gift for your time. I am not the only user searcher at Google, and this is not the only product that is supported by this, but I am interested in hearing your feedback about Gerrit and runs studies on here, and you’re welcome to join me.
Today and tomorrow we have a booth that you may have seen already with this banner, and we have a new dashboard design, a new patch navigation system and a new navigation for related changes that we’d loved to have you have a look at. We are not showing them on these slides on purpose because we want you to see the designs and come with a bunch of feedback on your first impression to the UI.
Please come to the booth and talk to any of us, there is Jason Buberel with us (our Product Manager), you’re welcome to come and speak with him as well, and almost all the Googlers here are willing to show some of the new designs.
Questions.
Q. How exactly you come out with a new design, the layout, how to make it better. How do you know that the user experience is better compared to the previous old one?
A. I take what your pinpoints, what you love, and I tell Arnab, and then he comes with a new concept. How do you know if that is better? Typically you generate tasks of what you would usually do with our UI, and we then do a tasks assessment where you see the goal that you go through those tasks and see if they failed. You talk aloud thinking while you go through those tasks and you may say “I really don’t like this new UI” and from that, you do mainly a mini A/B test. You can go through this process for just a few people and you don’t have to build up the entire product that everyone sees.
Q. I remember when a couple of years ago there was the announcement that we are going to have the new PolyGerrit project. We all asked “when the new GUI is going to be available?” and the answer was “six, maybe twelve months.” Now after two years we have something that works that is PolyGerrit, we started using it, and we like it. There are still gaps that are not really on the change screen, which is way better than the old one. I can use it on my Tube in the morning on the mobile phone while the old GUI did not even render or it was so tiny that you could not even see it. The gaps are more on the other parts of the UI. 50% of the users are using Gerrit as a very reliable Git server, have you put on your radar all the other use-cases not directly related to code-review that currently PolyGerrit is not covering?. The on-line editing, the code-browsing, the user-journeys from the code to the review and the way back, integrated search across code and the associated reviews?
A. Something is clearly in the scope of Gerrit, and something is not, but that does not mean we are not interested in it. Source browsing is one example of it, and I don’t think it will be in PolyGerrit but that does not mean that we are not interested in a way to browse source code. We are working on the in-line edit, maybe is not something we looked at the usability of it yet, it is a bit lower on the list of priorities, but are starting with the implementation and Arnad has been helping us with the basic design elements of that. It will be a basic feature at first, but it will look nice and be usable to some extent, and then we iterate.
Q. What about the completely new redesign? Are your efforts directed in completing what is there or are on reinventing everything from the ground up and we have to wait for another two years?
A. We are focused on the immediate terms of completing PolyGerrit because for many technical reasons we want to replace the GWT UI and we want to have more users using PolyGerrit so that we can get feedback to keep going. As we get more and more feedback and more and more iterations on PolyGerrit in the wild, we will come up with a lot more work for us to do. In the near term, we are going to implement what Arnad has presented and while we are doing that Arnad will help us by collecting some more feedback around what you will see at the booth, around the new dashboards and we are going to keep working on that. PolyGerrit is not going to stay static as it is today, it is going to be more iterative process based on Gerrit @Google and the Gerrit master branch. At every release cycle of the Gerrit OpenSource project, we will include some significant improvements on the user experience.
Q. I am just wondering how the new users get represented in your user research. Maybe people coming from GitHub or GitLab but even other people coming from different source control systems such as Perforce or SVN. How do you capture their experience? A lot of us have used Gerrit for a while and understand to a degree, Gerrit. However for other people, at times is a kind of a ping-pong, even though you are a new user for a very short time until you learn Gerrit.
A. On-boarding is definitely on our radar, we take users that have not used Gerrit before, and we ask to perform certain tasks. That is the kind of the recipe: take people that never used the product and working with Arnad on their feedback to make that process smoother.
Q. How many research you have made on the other code-review tools, advantages and disadvantages over Gerrit?
A (Dustin). It is an approach I am willing to take, doing a kind of competitive analysis. I have not started yet, but it is definitely on the roadmap for research.
A. (Jason). If there are other code-review tools that you’ve used and something that worked well, something that Gerrit or PolyGerrit could benefit from their knowledge or usage, please let us know. Nothing is off the table here concerning what we will improve or consider improving. If you used other code review tools, e.g. “hey reviewable.io got this very pretty good thing, you should do something really similar to that”, by all means, please let us know because we are opened to improvements in all areas.
Q. Following-up on this question, there will be talk tomorrow on this, our friends from CollabNet that are contributing to Gerrit Code Review have clients that are using not only Gerrit but even other tools like GitHub and many of them are hearing concerns of people getting lost without their pull requests. Because they are coming from other tools like Atlassian BitBucket, they have the concept that “without a pull request there is no review.” They have as well the misunderstanding that Gerrit forces you to amend the latest commit all the times, which is wrong. Gerrit allows you doing whatever you want. If you want to amend, you can do it; if you want to use feature branches you can do it as well. I remember Martin last year saying that they are using feature branches at Qualcomm and there is nothing wrong with it. CollabNet has developed a very basic UI that allows people that are coming from the pull request workflow to keep on using that paradigm. This UI is a sort of lightweight code review that helps to digest Gerrit gradually. That could be even the key to solve the dilemma raised on a recent discussion in the GoLang project where people asked to stop using Gerrit and instead using GitHub to review contributions. Following the discussion thread, it emerged that Gerrit is “too good” and does exactly what they need while GitHub doesn’t. However, there are concerns about other potential contributors coming from a GitHub experience having to invest 15′, maybe 30′ or even one day of learning of the Gerrit Code Review workflow and a new UI paradigm. They may decide to give up and avoid contributing at all. If the project would move to GitHub pull requests, this problem would just disappear. Are you guys taking into consideration how to make this transition from GitHub smoother and Gerrit easier to understand for those guys?
A. That’s a great question, and as the formal product manager for the GoLang project, I heard from some members of the community of the project that they were relatively unwilling to contribute. We saw this type of disparity from the casual contributors. Those are the people that find a typo in the docs and just want to fix it quickly. With the GitHub UI is nice because they see the problem, they click Fork, edit the code on a single line or merely a single file, and they create the pull-request with a straightforward review process and gets merged and done. You never had to clone the repository, did not have to figure out the authentication bits, and that is simple. You know, whether we want or not to take Gerrit down a path where we want to make these casual contributions super-simple it is something we are open to if that is what the Gerrit community thinks is a significant capability. At the same time, we do not want to displace GitHub with Gerrit, there is a vast community there for a reason, but there are specific workflows like the casual contributors’ workflow that are certainly easier on GitHub and much more difficult for users that are new to Gerrit. It is an area where if we think there is a need for, we should think about it and consider how we may support such a thing. We are open to hearing more feedback on things like that.
A. I just came from the OpenStack developers’ summit in Colorado a couple of weeks ago, and we were having the same conversation regarding onboarding contributors to OpenStack. Most of the people coming from GitHub are having the same hurdle. One of the things that were discussed out there was having some documentation, some quick-start, cheat-sheet, crash course, for people that are familiar with GitHub. It is not just about enhancing Gerrit code to make it more friendly and port the workflow they are used to use but provide content that helps people, coming over.
A. Dave is one of the tech writers at Google who works explicitly with Code Review. If you have a specific part of the documentation set that you think it needs improving or a brand new part of the documentation set that could be useful to new users, come to him and talk today or during the next days. He will be happy to help.
A. I have started already building a spreadsheet, a kind of rosetta-stone of mapping concepts and commands for mapping one to the other and I’ll show you that. That is just one approach, yes, but there are some pros as well.
Starting from this week, we are going to share one video per week of the amazing talks that were presented at the Gerrit User Summit 2017 in London.
In addition to the YouTube recording, we are during the extraction of the text and publishing it together with the relevant pictures taken from the presenter’s slides, so that people can start digesting the content at small bites.
This week talk is Patrick Hiesel’s presentation on how Gerrit multi-tenant and multi-master setup has been implemented in Google.
Gerrit@Google – Patrick Hiesel, Google
My name is Patrick, and I am going to talk about the setup of Gerrit we are running at Google. I wanted to take you on a journey starting with Gerrit that you all know and making it the system we run at Google, step-by-step; and at the end will have a multi-master and multi-tenant system.
Multi-what?
Multi-tenant is the ability to serve multiple hosts from the same single Java process. Imagine like the same JVM task serving gerrit-review.googlesource.com and gerrit-chromium.googlesource.com.
Multi-master is the ability to have multiple Gerrit servers all over the world. You can contact any one of them for reads and writes.
Most systems have read replicas, which is straightforward, but write replicas is where the juicy meat is.
Multi-tenant
We have gerrit-review.googlesource.com, based on OpenSource Gerrit that you can download right now and have it running hopefully under ten minutes. That is core-Gerrit, and it depends on three things:
JGit: for all the Git stuff
Multiple indexes for the accounts, changes, and other stuff
Caches
All these three components are based on the filesystem in one way or the other.
Now you have a friend that is accessing go-review.googlesource.com, what are you going to do?
The most natural solution is to start another Gerrit instance for it. You can have all of them on one machine, you can give them different ports, very easy, and in the end, they’ll be all based on the filesystem.
All those Gerrit instances do not need to talk to each other; they can just be separate instances operating on separate ports. This is not a multi-tenant system, but only different Gerrit instances on the same host.
You can add another layer on top of it: a servlet engine which receives all the traffic, check which host the traffic is for, and just delegate to the individual host.
To take one step further, have that selection filter doing that for you. Gerrit has a daemon that runs all the functionalities. You can integrate that daemon into the incoming servlet filter. When you can get a request for go-review.googlesource.com and I do not have where to allocate it, you can just launch it, instantiate all the objects and then run the traffic from there. Also, unload instances would work in the same way.
The Gerrit server engine and the selection filter can run in a single JVM.
How Gerrit can conquer the world
So you have a master here in Europe, and you have got one friend on the west coast in the US. He says: “Oh your Gerrit is so slow I have no idea why and I wish I could move to GitHub.” You say: “Hold on, I can do better than that!” and so you put a new master for the person on West coast.
So the key to that is the replication and comes in two sets:
Objects that you have to replicate related to all the Git data. JGit is putting objects into the disk, and these are the data you need to replicate correctly and fast.
Other stuff that should replicate and fast to provide a pleasant user experience but it really can be best-effort. That is the indexes and the caches.
If it is okay for your master having a 200/600 msec additional latency, then do not replicate the caches. You can have a cold cache in Singapore or the US, and you can reread them without problems.
For the index, replication can be best-effort, but you should make an effort to replicate them. It is still nonetheless a mandatory requirement. One way to achieve that is to use ElasticSearch, but other index implementations that give indexes replication can be used as well.
Multi-tenant and Multi-master together
We talked about a multi-tenant system and then replicate them globally, so we have now a multi-tenant and multi-master system, actually pretty close to what we run at Google.
That is the stack that we run in total. We have a selection filter and two other filters to decide what the traffic is directed. We are also based on JGit, no magic there, we have index and caches we replicate, all our systems are based on filesystem and BigTable.
Some “magic” happens at the Git layer at Google because that is where all the majority consensus across all the cells. When you are pushing anything that is Git and, with NoteDb, anything that is a review is in the repository as well, the system tries to reach the majority of the cells and write the objects to them. When that is acknowledged, you get a green light on the push.
Majority consensus also means that you have it only in so many cells, but don’t have it on all the cells all the times. Some of the replication is happening in the long tail, by replication events eventually get acknowledged by the cells, and then they get written to all the masters.
Our indexes and caches are also replicated, but some of them are just in-memory and a component that gets replicated on top of BigTable.
Redundancy everywhere.
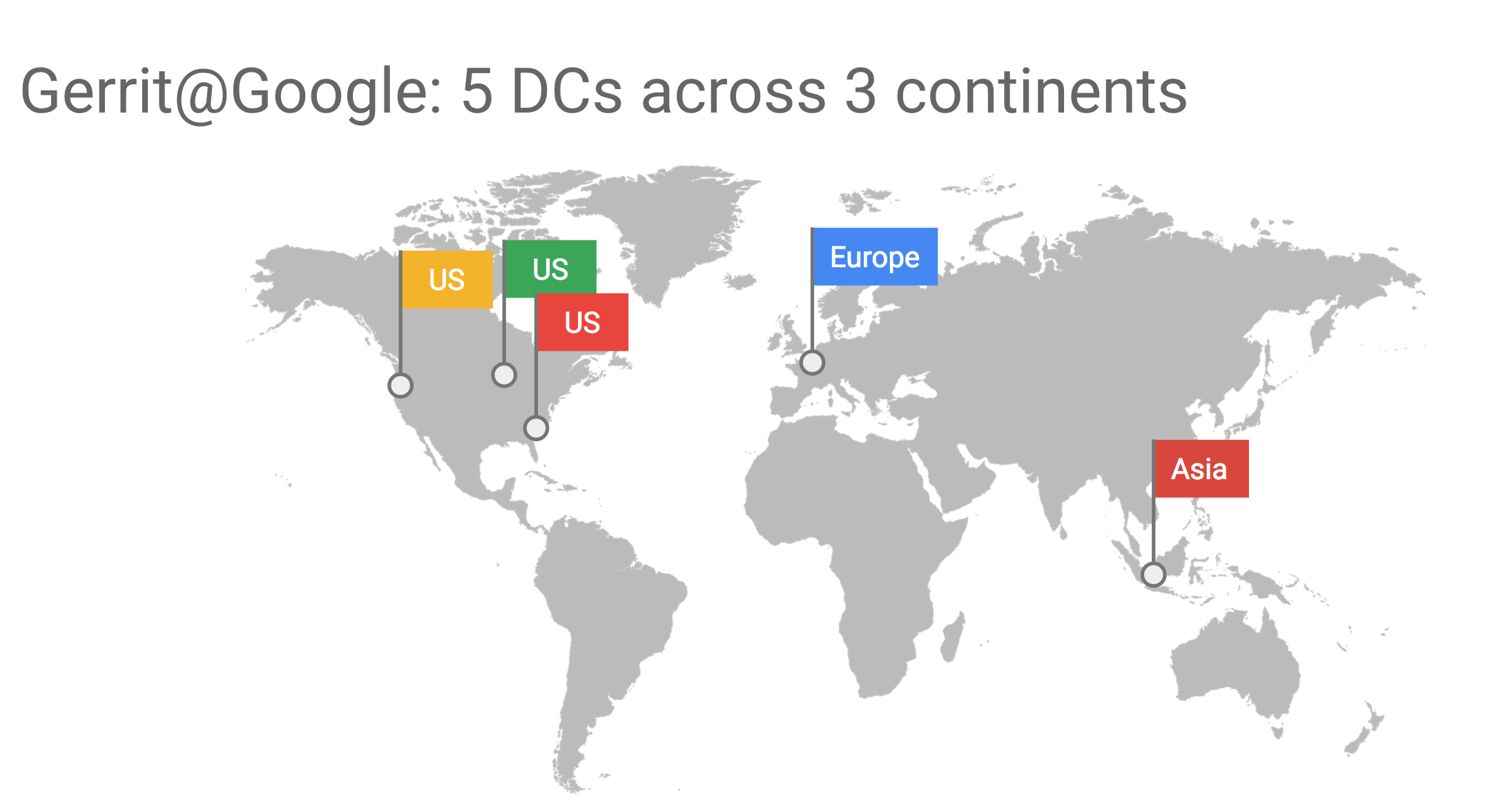
We run five data-centers across three continents (Americas, Europe, Asia-Pacific), with precisely the stack we just saw which gives us a good latency for most of our users worldwide.
Let’s talk about load balancing. We have a system that is multi-master and multi-tenant, and any of the tasks can serve any requests, but just because it can, doesn’t mean that it should.
Maybe it has in cold memory caches, or it is in Singapore, and you are in the US; so the question is what if the biggest machine is not big enough and we want to optimize it?
The idea is that we want to reduce latency that comes out of cold caches and minimize the time the site takes to load.
So you have a request for gerrit-review.googlesource.com, and your instance has a cold cache, and you need to read from disk to memory to serve the request.
You have a fleet of 300 tasks available but you want to serve gerrit-review.googlesource.com from only just five of them. If you serve 300 requests from 300 tasks in a round-robin manner, you pay the latency to load data from disk to memory for every single request. And the second motivation is that you want to distribute the load.
We want a system that can dynamically scale with changing load patterns. We want a system that can optimise the caches, to send a request for a site/repo to the few number of servers and tasks based on two conditions:
serve from one machine as long as it fits on it
server from more machines if you really have to
Level-1 load balancer
In the stack at Google, you saw two load balancing levels. What you see down in the picture is the Gerrit tasks, that contains all the software layers we talked about. We have a user that triggers JSON calls from the browser, with PolyGerrit. The first thing that the JSON request is hitting is the L1 load balancer. The primary routing of your request is by geographic proximity. We have five datacentres at Google; the L1 load balancer picks the one with the lowest latency. When the request goes into the data-center, we have another load balancer which is the one I’ll talk about more, because this is the one where the Gerrit specifics happen.
One thing that L1 is doing as well is managing the spillover of traffic. When a datacentre says “I can handle up to 100 QPS” the L1 load balancer starts redirecting traffic to other datacentres should that threshold be reached.
Level 2 load balancer
Let’s dive into L2 load balancer, we want to know how much traffic we are getting into each Gerrit task, and we want to know in the load balancer where the single request should go, and we want to know that fast!
We added three new components to the architecture:
An element to redirect tasks and provide functionality and can report the load we are handling right now. When I mean load it can be anything: QPS (Queries Per Second), metrics, we just want to know from the tasks: what is your current load? We have a system called slicer, which I am going to talk about in a second and it’s added there in the picture.
A second component we are adding to the load balancer, with a query interface that responds to the following question: “we have a request for gerrit-googlesource.com, where should it go?”. All of that should be done in memory and should be regularly updated with the new elements in the background so that we don’t add another component of latency by having another RPC.
A third part is coordinating everything and is called the assigner, and it takes all the load metrics that we reported generates new assignments and gives them to the query interface.
Introducing the slicer
We have a system that is called slicer. There is a very nice paper that I can recommend, published last fall, that talks about that. It is a load balancer that works on custom keys and can do automatic re-sharding based on new traffic patterns. When your nodes receive more traffic, the slicer will automatically distribute the load or re-shard the whole system. That is a suitable method for local sharding that happens within the data center; we do not use it for inter-datacentre because that is all done via geographic proximity.
The system works with 64-bit keys and gives you a lot of combinations. You can slice the keyspace, for instance, in 400 slices. That gives you 400 ranges, and you can take any of them and assign to one or more tasks. The hostname is my key for instance, and then you hash it, and you end up in the first slice that gets assigned to a single task with an index zero.
What can we do if the load changes? Let’s say that you have key zero that gets assigned to the first range and then the traffic changes. We have two options.
The first option is to assign more tasks, let’s say task 6, and then you round-robin between task 0 and task 6.
The second option is splitting into 600 or 800 slides to get a better grip on each of the keys.
We can also do that, and then we factor our the load for gerrit-review.googlesource.com and go-review.googlesource.com, and we put them into different hosts.
We do that for Gerrit, and one of the things we want for Gerrit is when we have to split per-host traffic with the affinity on the repository. Caches are based on the project, and because gerrit-android.googlesource.com is a massive host served from a lot of tasks, we don’t want all these tasks just to serve all general traffic for android. We want tasks serving android/project1 from here and android/project2 from there so that we optimise the second layer of caches.
What we do is to mangle these keys together based on both host and project. Before, all these chromium keyspace was served from a single host; when the load increases we just split the keys into Chromium source and the rest of metadata. This is the graph that we obtained after we implemented the load balancer. The load we have on each of the tasks in a single data center is represented by a line with a different color. What you can see is that are all nicely aligned, so that each task is serving precisely the same amount of traffic which is what you want.
What if one project is 100 times the size of the others and we are optimizing on queries per second? The system will just burn resources fast. We had that situation in May, we saw the graphs, and we said “all good, looks nice”; however, people were sending e-mails and raising bugs wondering if the system were serving any traffic at all or if it were down completely.
It turned out that Android had a lot of large repositories, regarding the number of references, and the objects. We were just optimizing the queries per second, but some of the tasks were doing just CPU intensive work, where others were happy with it. Some of them were burning CPU in flames, and others were fine.
So we moved out of the per-request affinity, and we modified the per-repository sharding to optimise all of this.
Warm vs. Cold Cache
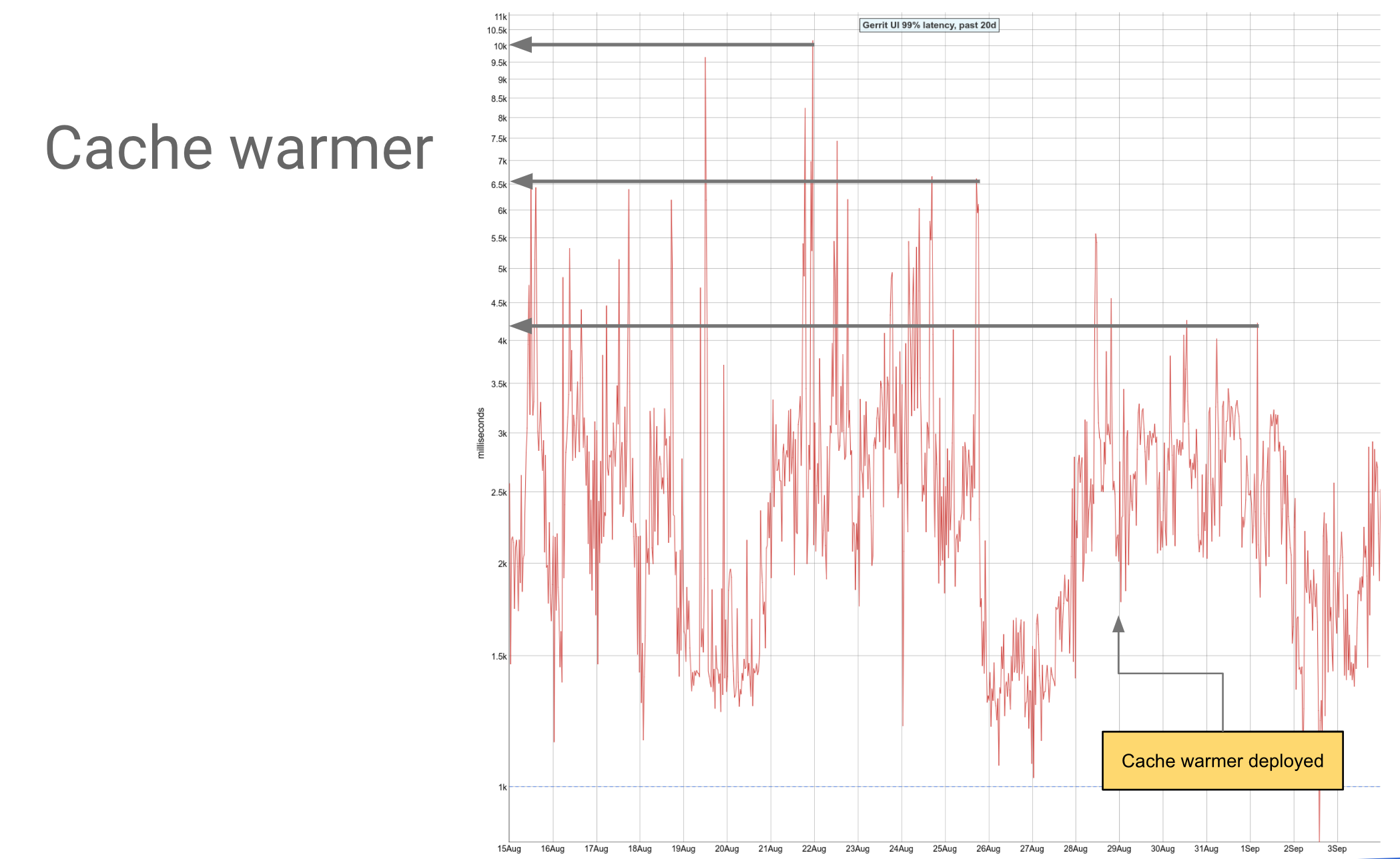
There is an extra in the system that is pre-warming caches. What the load balancer can do for you is to tell you that traffic is changing and I need to reconsider how to split the load on the system. For each of the tasks is going to tell “I’m going to give you traffic for gerrit-review.googlesource.com” with a notice of 30 seconds. That time you can use for pre-warm caches.
That is especially nice if you restart your tasks because all the associated in-memory cache gets flushed. The load balancer tells you “oh, this is the list of the tasks I need” and then you can get them all and pre-warm their caches. This graph shows the impact of the cache warmer on our system, on the 99.9% requests latency, really on the long tail of requests latency. That looks nice because we brought the latency down by a third.
What is a task start dying during peak traffic? Imagine that the load balancer is saying “You’re going to handle this” and two seconds later says “I have to reconsider, you’re going to handle that instead”. Again you’re going to watch your system burning on fire, because you’re serving peak traffic and then you’re running close to 100% CPU. That situation causes the load balancer loading and unloading tasks all the time, which is inconvenient. The way we work around this is to make this cache warming a best-effort activity. You can do it if you’re below 50% CPU when you have time to do fancy things, but when you receive peak traffic, you just handle peak traffic without any optimisation made.
Multi-master and multi-tenant outside of Google
The question is: how do we do that in a non-Google setup?
There are plenty of options.
With the new Gerrit release in 2.15, we introduced to a new URL scheme, which includes the project name in the URL. Previously you had gerrit-review.googlesource.com/c/NNN and there was no way to directly know which project this is for and no way to do that load balancing that we just saw.
What we did in 2.15 is just add the project before that, so that extraction for both host and project can be made in a simpler way. You could do the same even before v2.15 but you needed a secondary index lookup, which most opensource load-balancers such as HAProxy or NGINX did not support. And of course, there are lots of products like Google Cloud load balancer, and others that you can use to achieve the same thing.
Wrap-up
We went through a journey where we took OpenSource Gerrit, we added sites selection and got a multi-tenant Gerrit.
Then we took this multi-tenant Gerrit, added replication and obtained multi-master Gerrit.
And then we took that with load balancing and lots of failures and lots of fixes, and we got pretty much the Gerrit that we run at Google, which brings me to the end of this talk 🙂
Q&A
Q: How strategic is Gerrit@Google? Do you have any other code-review systems? If yes, how is used Gerrit vs. the others?
We have another code-review system for internal use only, and Gerrit is used whenever we are doing OpenSource stuff, so for GoLang, Chromium, Android, Gerrit, and whenever the Google Team wants to collaborate with other OpenSource users, or in general with users that are not sitting at Google.
Historically the source at Google was developed in Perforce, and we ported from that to a home-based system called Piper. Around that, we have a tooling ecosystem which is internal. In parallel to that, Google started to do a lot of projects that have nothing to do with the internal search engine and available outside. What we see is that a lot of projects started at Google from scratch were thinking about “what system should we use?”. Many people said: “well, we’re going just to use Git because that’s what we know and we like, ” and when they needed code-review for Git they ended up with us. Gerrit and Git are very popular inside Google.
Q. You have two levels of load balancer. The first one is the location, and the second one is to decide what to do inside the data-center. What about if a location is off? Maybe is not fully off-line but has big problems, or has a very low-percentage of consensus, and some of the locations have not the “latest and greatest” of the repo. Possibly a location that should be “inconvenient for me” actually has the data I want.
You’re talking about replication layer where you have the objects in one location but not in the other. Our replication latency is in the order of seconds, but it may happen that one location is just really slow in getting the objects. That happens from time to time, and we have metrics that says what the replication lag is accounted for. When it exceeds a threshold we just shut the data-center off, which means cut-off the traffic, the data-center will not receive user-traffic anymore but it will still be able to get the replication done, and when the decrease the objects we need to replicate we can send the traffic again.
Cutting off the traffic is happing at the L1 load balancer where we said “don’t send anything there”.
Q. Do all the tasks have the same setup? Or do have a sort of micro-service architecture inside where some of the tasks are more dedicated to this type of operations and other for another type. Serving data from memory in one thing, but calculating diff change is a different type of task.
Not in general. All of our tasks are the same, except for checking access control permissions. We do not go through the whole Gerrit stack but we have only this little task that knows how the project config works and is going to tell us yes or no.
New and exciting features are coming for this year Gerrit User Summit, with the launch of Ver. 2.15, NoteDb, high-availability, multi-master and much more.
The Summit will take place for the very first time in Europe, London, the location chosen by the community after a public consultation, the 2nd and 3rd of October at CodeNode (Skills Matter).
See below an overview of the topics that will be presented and discussed during the User Summit.
What’s new in Gerrit 2.14.x.
Gerrit v2.14 was released during the last Hackathon in April and has gone through three patch releases. David Pursehouse from CollabNet will give an overview of the new features introduced which would be highly beneficial for all of those who haven’t migrated yet.
Gerrit at Google: Multi-master, Mutli-tenant.
Google is the founder, main contributor and possibly the most advanced user of the Gerrit Code Review: learning from their experience is a unique opportunity to learn and being able to leverage and use the tool at its best.
Patrick Hiesel from Google will go through the insights of their Gerrit Code Review architecture and will provide some of their metrics of scale. In addition to that, he will present some findings from the recent switch of their load-balancing infrastructure and the associated pitfalls encountered.
Google is possibly the only one in the world using Gerrit in a multi-tenant setup, having a unique multi-master installation that serves a constellation of domains and projects, including huge and familiar ones like Android and Chromium.
Standing “on the shoulders of giants” like Google helps a lot in preventing scalability issues as the audience and adoption of Gerrit Code Review grows in large companies: being part of the audience in the talk is a unique opportunity to learn and ask questions directly to the maintainers of their infrastructure.
PolyGerrit: a new UX experience for Gerrit Code Review
Google has invested a lot in reinventing and reengineering the user interface of Gerrit Code Review, which remained mostly unchanged for almost a decade. A new team has been put together in their San Francisco offices with experienced UX developers that leveraged the new Polymer framework of web components.
The result is PolyGerrit, a modern web UX which provides an unprecedented browsing speed and flexible rendering across different devices, including mobile and tablets.
The PolyGerrit Team will be presenting the findings of their user-experience research and show some of the features and insights of the new UX.
Gerrit CI and keeping logs forever.
Gerrit Code Review itself is a large project, involving over 300 developers across the globe and using the most advanced DevOps practices. The CI/CD pipeline has been provided and managed by GerritForge on the https://gerrit-ci.gerritforge.com and Luca Milanesio from GerritForge will present the latest improvements in the pipeline plus an interesting way of collecting and reusing the logs.
Leveraging the logs for identifying the bottlenecks of the CI/CD pipeline is the way to drive improvement. GerritForge leveraged the expertise of his engineers to harvest and organize data and will give it back to the community as powerful dashboards.
Beyond Gerrit.
Gerrit is great. However, it is also quite an important part of a bigger ALM process. Jacek Centkowski from CollabNet will describe how multiple tools can be unified under a single TeamForge umbrella and what are the immediate benefits of it.
What’s coming in Gerrit 2.15
After only four months, we are already close to the v2.15 of Gerrit Code Review, which would be possibly the last one before the step to the v3.0.
Dave Borowitz from Google, principal maintainer of the Gerrit Code Review project, will go through the new features of v2.15 and possibly give a glimpse in what to expect from v3.0.
Mining Gerrit Data to Study Contentious Reviews and Community Evolution
Gerrit Code Review is much more than a tool, it is a way for people working together in companies that are large and mostly distributed across the globe.
Shane McIntosh from McGill University has been running a research lab on this topic. The Software REBELs—a research lab at McGill University—mine code review data to study topics like the impact that code review practices have on software release and design quality. Our more recent work mines code review data to study the reviewing process itself. In this talk, I will describe the results of two empirical studies of data that we collected from the Gerrit instances of the OpenStack project. The first study aims to understand the reviews where reviewers disagree about a patch. The second study follows how the concerns that reviewers raise evolve as the OpenStack community ages and individual reviews accrue experience.
Gerrit Analytics: dashboards, networks, KPI
Gerrit has always been lacking major code analytics features compared to other Git Server tools like GitBlit or GitLab. GerritForge Ltd is filling the gap and adds one important asset to the Gerrit Code Review platform: code review analytics.
We need to harvest and unify the logs and events coming from the different components of the CI/CD pipeline by putting at the center of it the people and teams that are building and discussing the code on Gerrit. The resulting data-lake of information can be later analyzed and correlated to calculate the cycle time of the entire pipeline.
Luca Milanesio from GerritForge will show the new analytics dashboards that are going to be published and provided back to the Team that is developing the Gerrit Code Review project as a precious contribution to the community.
How to extend Gerrit using Scripting Plugins
Gerrit Code Review has a robust set of API that can be used to extend its functionalities and provide a more integrated development workflow for the Teams.
Luca Milanesio from GerritForge will present how to use different scripting tools to extend the capabilities of Gerrit without the need of developing and building a plugin, using Jython, Groovy and Scala.
A new simpler but powerful Gerrit Jenkins plugin
Gerrit Code Review is an essential part of a larger CI/CD pipeline. Most of the times it is used in conjunction with Jenkins, the most popular OpenSource Continuous Integration and Delivery tool.
The integration between Gerrit and Jenkins (Gerrit Trigger Plugin) was developed back in 2010 at Sony and since then has been extended and adopted in thousands of Jenkins installations. However, Jenkins has evolved too and has now a brand new concept and definition of multi-branch pipeline which struggles to be seamlessly integrated with the current Gerrit Trigger Plugin.
Luca Milanesio from GerritForge will present a brand new plugin based on the new Jenkins branch discovery API which works seamlessly with Jenkins multi-branch pipelines and provides a simpler interface with Gerrit by leveraging the new WebHooks.
Diffy with enterprise grade
Since 2012 CollabNet has been working on improving Gerrit integration with TeamForge. Many features have been created to satisfy the needs of enterprise customers. Eryk Szymanski from CollabNet will present features like RBAC, history protection, Git style notifications, quality gates, pull request and code browser which have been implemented on top of vanilla Gerrit.
Q&A with the maintainers
Have you ever wondered why something is working in a certain way? Have you ever wanted to explain any complaint about some parts of Gerrit? Would you give your congratulation to the people that made this project? Would you like to make a feature request or propose new ideas?
This is the moment where you can speak directly face-to-face to the people that are building this project every single day, the Gerrit maintainers.