The Gerrit User Summit 2023 took place in-person simultaneously in Sunnyvale, California on September 30th and in Gothenburg, Sweden until October 1st 2023. To accommodate the global community, it was live streamed on GerritForge TV so that individuals in various locations could participate, share their experiences, and contribute their ideas.
If you were unable to attend the Summit, you can find all the presentations and content online . Additionally, recordings of the presentations and Q&A sessions can be accessed on GerritForge’s TV channel on YouTube.
Stats and attendee feedback around the 2023 Summit
Snapshot
- 2 days
- 2 locations
- 84 registrations
- over 70% attendance
- 34 companies
- 16 sessions
- 18 presenters from 8 organisations
Despite the challenges posed by the time difference, the community still got involved showing its commitment.
What is the opinion about the Summit?
A survey was sent to all of the attendees on both locations and even though there was a 30% response rate in USA and 17% in Sweden we delved into the details, and these are the comments received:
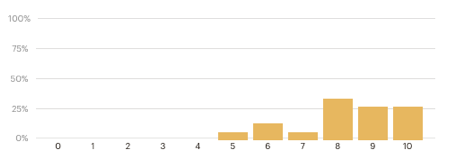
Q1: How would you rate the Gerrit User Summit 2023 edition?


While in USA, 9% of the respondents rated their experience at a 10, 55% rated it at a 9 and 36% gave an 8; in Sweden the great majority rated it with an 8. Where 10 was the highest positive rate, this feedback gives an idea of how satisfied attendees were in general with the User Summit. Understanding individual experiences and perceptions allows us to evaluate the event and identify areas for improvement.
Q2: What did you like the most about the 2023 Summit?
Attendees in California were thoroughly impressed with the technical excellence of the talks at the event and appreciated the valuable networking opportunities. On the other hand, Gothenburg attendees raved about the fantastic space and location of the venue. They found the off-camera discussions, presentations, and Q&A sessions incredibly interesting and enjoyable. Thought the use of Slido for Q&A was highly effective, giving attendees ample time to contemplate and engage with the speakers.
They also loved hearing organisations share their stories and the collaborative atmosphere for creating new design documents and proof-of-concept code. The attendees were left with the impression that the event brought together a multitude of talented individuals who delivered engaging talks. The event left high expectations for upcoming features and created an enthusiastic, positive atmosphere.They truly valued the chance to engage with fellow attendees and found the experience rewarding.
Q3: What did you not like about the 2023 Summit?
Attendees from both locations expressed their concern about the division of the summit into two locations and time zones, which made it challenging to connect with the entire group. While the idea of having simultaneous locations was appreciated, attendees in Gothenburg felt disadvantaged as they were unable to ask live questions to presenters due to the time difference with the USA. It was recommended not to repeat this approach in future events. However, overall, the attendees had a positive experience at the summit. They expressed their wish for Google to attend in the future and highlighted a missing feature in Slide that would allow for the separation of topics in questions.
Some attendees preferred the event to be held on weekdays rather than weekends, as it affected their personal time. Additionally, they expressed a preference for more user/project-driven success stories, as opposed to focusing solely on development and administrative topics. Some attendees also noted that there was a lack of diversity in the companies present. In Gothenburg in particular, they suggested choosing a venue with less noise for dinner to facilitate networking. Lastly, it was reported that the attendance felt to be relatively low especially in Gothenburg where the venue could have hosted hundreds of attendees.
Q4: What was your main objective in attending the Summit?
The attendees had two main objectives in mind: learning and networking. Going into further detail, they expressed various specific goals, including sharing research findings and enticing potential industrial partnerships. They were also keen on staying updated with the latest developments in the Gerrit ecosystem and gaining insights into how Gerrit is utilized within the community. Meeting people face-to-face was highly valued, as it provided a more personal and direct means of communication compared to email or Discord. Additionally, attendees wished to actively participate in the open-source Gerrit community and discover new directions for the product. Some mentioned that they were excited about the opportunity to listen to James Blair. For some attendees, the event offered a chance to reconnect with Gerrit after a period of absence. Some emphasised in the fact that fostering a positive open-source software community was a shared aspiration, alongside the desire to learn about how organisations utilise Gerrit in their processes. Overall, the attendees were motivated to make the most of the event, seeking knowledge exchange and valuable connections.
Q5: Do you consider to have achieved the objective?
A decisive 100% said to have achieved their goal by attending the Summit.
Reactivating the Gerrit community
Given the initiative to create a group of monthly in-person meet-ups (GerritMeets) to revive the community in the Bay Area (CA), in-person attendees at the summit in Sunnyvale, CA, were asked about their topics of interest, if they would attend in person, remotely live or watch the recorded content afterwards, and if they would participate by giving a talk.
Respondents agreed 100% that they would be willing to give a talk. They differed in the mode of attendance, as opinions were evenly divided between attending in person, joining remotely via live streaming, and accessing the recorded content after the meetup. The suggested topics were:
- ‘How to write a scripting plugin in Gerrit’,
- ‘Getting started with pull-replication and multi-site’,
- ‘Research on code review’.
The invitation to these periodic meetings was extended to the global community and when asked for topics of interest, the topic ‘Hacking’ was added.
What’s next for 2024?
- GerritMeets will start every month in 2024, from February. GerritMeets is periodic in-person meetup in the Bay Area, with the intention to live stream, so the global community can join as listener as well as with a talk, so everybody can learn & share knowledge and experience.
- With Gerrit 3.9 been released in November 2023, 2024 will be the year of Gerrit 3.10, in May, and 3.11, in November.
- Gerrit User Summit will be back in the autumn of 2024 with more interesting talks from the community
A genuine thank you goes out to all the participants and presenters who made the Gerrit Virtual User Summit 2023 a great success. We look forward to another exciting and even more engaging get-together next year in 2024!
Yolanda Jasso
Gerrit Code Review – Community Manager