The 9th edition of the Gerrit User Summit has ended today: a lot of new features and ideas have been presented and experimented in those four days.
Here is a summary of what happened and a description of the main innovations and presentations at the Summit and Hackathon at GooglePlex in Mountain View – CA.
12th-13th of November – The Summit
Gerrit v2.13
David Pursehouse from CollabNet presented what is coming in Gerrit v2.12 and v2.13.
Gerrit v2.13 has been the biggest version of Gerrit ever, with over 2,600 commits from 83 different contributors. That shows that Gerrit is an OpenSource project with a growing Contributors’ Community, getting more diverse over time.
There have been a lot of new features and improvements introduced. The most significant and noteworthy features are …
Git LFS
Ability to store large files outside the Git repository to an externally pluggable repository, such as HDFS or AWS S3.
Gerrit Metrics
New extension point to extract in real-time the performance data of Gerrit’s internal activity and publish them externally to Graphite, ElasticSearch, JConsole or other similar graphing and monitoring tool.
Hooks
There is now the ability to replace the dated hook system with much more powerful in-process-plugins. Existing hooks are then still supported using the “hooks” core plugin. Gerrit is getting more modular and extensible.
Improved review of Merge Commits.
Gerrit can implement effective “merge-requests” lifecycle on top of regular code review. You can now create feature branches exactly as you do with GitHub or GitLab and then submit only the “merge request” as change for reconsideration.
What’s cooking in Gerrit v2.14
PolyGerrit
After eight years, Gerrit GUI needed a complete revamp and modernisation, to compete with all the other web-based Code-Review systems such as GitHub, GitLab, and BitBucket.
Google has allocated a brand new front-end Team, located in San Francisco, to redesign and implement a brand-new user experience. It is much more than a simple rewrite; it is a complete rethinking of how to get the most of your code review functionality with the optimal utilization of space.
The new UX will be more fluid and adaptable to different sized screens, including tablets and even smartphones. It will be then possible to give a usable GUI even when accessing Gerrit “on-the-road.”
Suggested Reviewers
Gerrit is getting smarter and, by using sophisticated heuristics, it can now understand and sort the suggestions of which are the people that are most likely to be interested in reviewing a change. Gerrit allows saving time in browsing for individuals and contributes to the accuracy of the reviews.
New HTML e-mails interaction with Code Reviews
Say goodbye to long ugly diffs in e-mails, and now you can generate nice and tidy e-mails where all the details are carefully formatted for achieving maximum clarity. Additionally, you will be even able to reply in-line to the comments received via e-mail and Gerrit will be able to capture the message back and insert the feedback as code-review messages into the code carefully.
Robot comments
CI and automated systems can contribute comments to the code, without spamming the overall review discussion flow. That contributes to a much cleaner user-interface.
Google uses automated code analysis tools such as Tricium and ShipShape to capture the most common mistakes in coding and event providing the corresponding suggested fixes. All this feedback will be captured and integrated with Gerrit in the change comments GUI. The Change’s author will then be able to review the suggested fix and apply it with a simple click.
The management of robot commits will be fully operational with the new PolyGerrit GUI.
ElasticSearch Indexes
Instead of using the local Lucene Index, Gerrit would use an external ElasticSearch cluster to achieve maximum scalability and share the index across multiple nodes. That is one of the cornerstone feature needed for a multi-master setup.
A lot of time has been spent in making sure that the ElasticSearch support was aligned with the current Lucene implementation, but unfortunately, it took until v2.14 to fill the gap. Still, there are parts of the index not yet implemented in ElasticSearch, such as the on-line reindexing. Hopefully, the v2.14 will see all those gaps resolved and enable a real multi-master shared index setup.
Atomicity with Change-Sets
Basavaraj Karadakal from Juniper Networks presented a real-life implementation of the “submit whole topic” into his organization. We always said that “topics” require some company-wide naming policy to avoid conflicts and unexpected behaviors: Juniper found the solution by introducing a new concept, the “changeset.”
The name isn’t new to people that have been in the SCM long enough to remember IBM Rational ClearCase. Interestingly Basavaraj used that term, possibly to facilitate the understanding and adoption into the company.
The idea behind change set is to have a single change review “leading” the topic submission, stored in a “tracking repository”. One can understand the list of changesets and their status by querying the “tracking repository”. This feature is fascinating because it allows obtaining a full list of “open topics” inside Gerrit, which isn’t currently available as “out of the box” feature.
The overall implementation of change sets is composed of a set of client wrapper scripts and server-side plugin to orchestrate the review status of the changeset based on the review status of each commit included.
We do foresee a lot of feedback in the community around changesets and topics: the discussion started a couple of years ago and everyone agreed that “something was missing” in the current Gerrit topic concept … possibly the “change sets” are the missing piece of the jigsaw to make the “submit whole topic” a feature ready for production use.
Pull Requests in Gerrit
Since v2.13, Gerrit allows full reviews of merge commits. However, the workflow isn’t visible:
- create a feature branch feature/abc
- commit changes directly to the feature/abc branch, without requesting any review
- once the branch is ready for review, merge into its target branch locally and push the merge commit to refs/for/target-branch
Eryk Szymanski, CollabNet, has presented an alternative GUI to make this scenario, typical of GitLib, GitHub, and BitBucket, more accessible for novice users.
The new Pull-Request GUI is based on two components:
- REST API, different from Gerrit’s native ones
- Pull-Request GUI, not integrated with Gerrit’s GWT or PolyGerrit but available as components of CollabNet’s TeamForge product.
Gerrit Analytics
Luca Milanesio from GerritForge introduced two new plugins in Gerrit 2.14:
- Kafka stream events: to consume stream events and send them to topics
- Project analytics: to crunch data from Gerrit repositories to expose aggregated contributors statistics
The vision of Luca Milanesio, GerritForge, is splitting Gerrit statistics into three dimensions:
- People. What is the list of contributors, maintainers, reviewers? What do they do, how often they commit and which ones are the most active influencers?
- Projects. How repositories are evolving over time and space and what do they need moving forward regarding storage and performance?
- Systems. How is Gerrit behaving concerning CPU, Memory, and Network utilization?
The correlation of the metrics collected in these three dimensions allows putting together the KPI that allows understanding better how Gerrit is used and how to improve its current and future performance.
Additionally, you could use them to reward and promote good practices of code-review and fuel continuous innovation across the teams.
In one sentence, Gerrit Analytics will allow to “uncover the hidden value of your Gerrit Code Reviews”.
Plugins for CI Systems
Martin Fick from Qualcomm Innovation Center gave an overview of three new plugins developed for use by CI systems: the batch, manifest, and task plugins, with some modifications to the Gerrit core needed.
The batch plugin provides a mechanism for building and previewing sets of proposed updates to multiple projects/branches/refs that should be applied together. The focus of batch updates tends to be verification (by CI systems). The batch update service provides the tools to build refs by merging changes to temporary “snapshot” refs, which can then be tested extensively, and finally submitted ”as is.”
That represents a different approach to resolving the “topic submission” problem: Martin’s plugin would work for all Gerrit versions from v2.7.
The manifest plugin provides server-side utilities to operate on, and query information about repo manifests (XML) stored in git projects on the current server. This plugin provides APIs to update values in manifests, and to search for manifests with certain values.
The task plugin provides a mechanism to manage tasks which need to be performed on changes along with a way to expose and query this information. Tasks are organized hierarchically, and their definitions use Gerrit queries to define which changes each task applies to, and how to set the status criteria for each task. An important use case of the task plugin is to have a common place for CI systems to define which changes they will operate on, and when they will do so.
Gerrit CI Pipeline
Gerrit has finally a fully-feature CI Pipeline, thanks to GerritForge who invested time and resources to set up the https://gerrit-ci.gerritforge.com web-site.
During the Gerrit Hackathon 2015, Luca Milanesio, Doug Kelly and Khai Do have put together their ideas and skills to introduce an entirely automated and community-driven Jenkins set-up which allows to automatically generate the build jobs from the YAML files archived in the Gerrit-ci-scripts project.
The magic behind the system is that nobody directly controls the definition and execution of the jobs, but it is the collective contribution and code-review of the YAML files that automatically re-configure the Jenkins instance automatically.
Over 30K builds were executed last year, with an average of over 80 builds per day. Thanks to the Gerrit CI it is now possible to discover which plugins are available and stable on different branches of Gerrit and download the pre-built artifacts with a simple click.
What is still missing is an official “distribution site” of the Gerrit plugins; a place where successful plugin builds are installed on real Gerrit instances, tested and released. GerritForge is investing time and money to fill the gap and will provide a premium service called “Gerrit Central” available as an add-on to existing Enterprise Customers. The resulting fixes coming from this process of plugins validation will be contributed back to the community and will be accessible for everyone.
Gerrit Bazel build: a farewell to Buck
From v2.14 Gerrit is moving away from Buck and, after eight months of work of efforts for migrating the build system, David Ostrovsky has finally announced that the build is green and we are ready to move to Bazel, yeah.
Building Gerrit isn’t an easy task, with 35 repositories, 400K Java + 16K JavaScripts lines of code, over 140 dependencies and a complete JavaScript toolchain based on NodeJS. In addition to that, there are over 100 plugins automatically built with our CI system hosted and managed by GerritForge.
Gerrit started initially with Maven, but it was very slow and clumsy. After the London Hackathon in 2013 the project was successfully migrated to Buck, which promised to be much faster and flexible. However, this choice has driven the project build to a swamp of problems and bugs/fixes needed on top of Buck to make the build work.
As a result, a custom version of Buck needed to be built using Ant for potentially every branch of Gerrit development. The Gerrit project has submitted over 100 bugs to the Buck project over the three years of adoption.
Bazel is an OpenSource build tool based on an internal system used in Google and is much more advanced and stable, offering a simpler installation and an advanced sandboxing capability to isolate builds and results.
Differently from Buck, Bazel promises both speed and accuracy, qualities that were not always present at the same time.
During the Hackathon, David posted a milestone change named “Remove Buck build” which is currently under review. We all hope that the change will be merged very soon and give the final farewell to Buck build, and our thanks for having helped and supported us in our journey for over three years.
Gerrit reviews from e-mails
Patrick Hiesel from Google presented a very innovative feature that extends the ability to interact with Gerrit reviews by just answering to e-mails.
The feature is still in the very early stages of development but the demo showed at the Summit was impressive. When you receive the e-mail notification from Gerrit with the comments of people to your code, you just answer in-line to the e-mail and … the magic happens! Gerrit fetches the e-mail automatically and understands the in-line replies as comments to be added to the reviews.
This new workflow dramatically reduces the cycle time of interactions during the review and represents IMHO the “killer feature” to push Gerrit to the top of the Code Review systems currently on the market.
Let me recap what you have to do currently with Gerrit:
1. Receive a notification e-mail
2. Read the comments
3. Click on the change link
4. Open a browser at the change page
5. Sign-in (assuming that you are using PolyGerrit, it would work on Mobile too)
6. Locate the comment you wanted to reply
7. Click on the comment
8. Click on Reply
9. Enter your Reply
10. Click save
11. Go back to the main change screen
12. Click on Reply
13. Click on Post
… and with the inbound e-mail ingestion in Gerrit it will be:
1. Receive a notification e-mail
2. Read the comments
3. Click on Reply
4. Insert your replies in-line
5. Send
There are issues, though, mostly related to security and trustworthiness of the e-mails as the vehicle for reviews.
We know that e-mails can be SPAMs or can be forged by faking source e-mail addresses. Currently, the prototype shown was only matching the e-mail sender to associate to the reviewer identity, which is fine for the majority of the cases but could raise some concerns regarding compliance.
The reviews coming from e-mails will be appearing with a different style and will be noticeable compared to more secure web-based comments. That would allow judging the comment accordingly and avoid over-reliance on their value.
It has been suggested as well to consider the integration of PGP-signed emails and the matching of the PGP-Key with the one stored in Gerrit for that user: that would be the perfect secure solution to avoid SPAMs or forged e-mails risks. However, Patrick did not commit to implementing the feature at this level for the initial MVP.
Inbound e-mail processing is a feature to keep under the radar as it will cause a wave of adoption of Gerrit because of the speed-up of entire Code Review lifecycle and consequently the time-to-market of the development of projects features.
Keep the conversation flowing with Gerrit at OpenStack
Khai Do, the maintainer of the Gerrit Review at OpenStack, has presented the challenges of managing comments with a large-scale project.
The OpenStack numbers for Code Review are astonishing:
- Nine servers (1 master + 8 slaves)
- 1500 repositories
- 400K changes
- 20K users
- 700 events generated every hour
In addition to the scale of the installation, OpenStack allows third-party to connect to Gerrit using stream events and trigger validation builds. This workflow is code-named TCPI at OpenStack. There are currently 180 registered TCPI which generate *a lot* of messages appended to each change under review.
The overload of information associated with a change makes the “discussion flow” hard to follow in Gerrit: each change is swamped by CI messages which make the overall review unreadable.
Khai has developed a plugin that allows avoiding storing all those messages as regular reviews in Gerrit and collect them instead in a relational database. The overall result is then nicely rendered in a different section of the change, making the review discussion visible and flowing again.
The plugin works out of the box on the current version of Gerrit. Well done Khai.
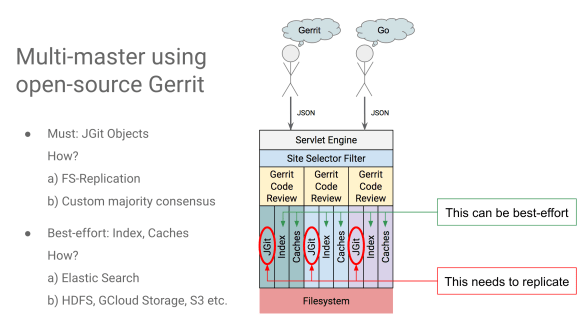
Infinite Gerrit
Haithem Jarraya from GerritForge presented the idea of adopting a much more scalable storage for JGit based on Apache Cassandra. Shawn Pearce experimented the same scenario a few years ago and contributed an initial prototype on GitHub: piggybacking on the same concept, the new experiments are now driven by the need of scaling up Gerrit in space and number of nodes.
Gerrit Multi-Master is getting closer day-by-day, thanks to the joint efforts of all contributors from different points of view:
- Sessions can be externalized to a flat-file to supports sharing across nodes (Qualcomm contribution)
- Indexes and Caches can be aligned across nodes through events (Ericsson contribution)
- ElasticSearch will be soon available as alternate shared indexing engine (Sony & CollabNet contributions)
Haithem now is adding one extra significant piece of the Jigsaw: the ability to have a scalable shared and extensible storage that allows all the master nodes of the cluster to read/write JGit Pack files at maximum speed. Additionally, thanks to Apache Cassandra multi-nodes data sharing and replication. You will be able to dynamically extend and reallocate the size and structure of the storage without impacting the current operations on the Gerrit Cluster.
The Cassandra backend wouldn’t cover the ref-database, which could be implemented with an entirely distributed implementation such as JGit Ketch (still in early development) or a more standard based on Apache Zookeeper.
Accounts and status of NoteDB
The task of migrating all the Code Review meta-data to the Git repository, aka NoteDB, started over two years ago. Edwin Kempin from Google, presented the current status of the implementation, with a focus on the Accounts migration.
In Gerrit v.2.13 there is already a new repository dedicated to the archiving of users, called All-Users. However, some of the information are still stored in Reviewdb, such as the external ids. Accounts will be exposed via REST-API and sensitive information encrypted end-to-end on the repository, using the same technique used for secure.config.
A new “magic ref” concept has been specifically forged for the All-Users use-case: the reference to their branches as refs/users/self. Each user will be able to get its meta-data by only fetching refs/users/self from the All-Users repository; easy isn’t it?
There is still one piece of information that will still stay outside NoteDB: the reviewed flag. The choice was made because of the inherent volatility of the information: NoteDB would have been overkill for a piece of information that lasts a few minutes or maximum hours typically. The default implementation will be H2 but it could be then replaced with something more “multi-master” aware.
What’s left? Gerrit Groups are the very last piece of the jigsaw and then NoteDB will be finally 100% feature complete. Bye bye DataBase, NoteDB is approaching fast!
Zero-Downtime Gerrit Upgrades
Luca Milanesio from GerritForge closed the Summit with a case-study on how GerritHub.io achieved a 100% zero-downtime migration process, with limited disruption to its 10K users.
Apart from Google, the current implementations of Gerrit Code Review around the world do not allow to keep the service running in case of upgrades between major releases. That was true until GerritHub.io recently introduced a well-testing roll-out mechanism inspired by the well known “blue-green” deployment.
The approach adopted by GitHub, in the case of DB upgrades, is to advise the customers up-front and schedule a planned outage of the system. Last time that this happened was last year and the blackout lasted for around an hour. However, GerritHub.io decided to be different and developed a strategy where the old version and the new version can work side-by-side by synchronizing Git repository and reviews, even across different versions of the DB schema and index.
The “preparation phase”, or Step-1 as Luca described it, may take even days or weeks to complete because relies on a low-bandwidth mirroring to avoid service disruption on the current user-base. Once the two instances are aligned, the subsequent steps will take only a few minutes.
During the “flipping” of the blue (old release) with the green (new release) instance, the users will notice that the repositories become read-only and receive a courtesy message saying “Upgrade is in progress, all projects are read-only. Please retry a few minutes later”.
The read-only “service degradation” would last only for a few minutes (2/5 minutes) and wouldn’t cause a service disruption for all the other users that are fetching, cloning or just browsing the reviews.
The Gerrit Hackathon

Even though this year we had only two “hacking days,” the overall productivity has been remarkable: 158 changes created, with 82% of them merged during the Hackathon.
Bazel Build
Authors: David Ostrovsky, Luca Milanesio, Edwin Kempin, Han-Wen Nienhuys
Changes: https://gerrit-review.googlesource.com/#/q/project:gerrit+after:2016-11-10+before:2016-11-17+message:bazel
The summary of the changes is perfectly represented by David’s announcement to the Gerrit mailing list:
“I’m pleased to announce, that we are moving from Buck to Bazel build tool [1].
I’m working for a while on the transition now, and we are reaching the feature
parity for Bazel build toolchain.
I think that Bazel is a better tool for us and provides the following advantages:
* all actions are hermetic by design (no arbitrary python code execution)
* bootstrapping doesn’t require Ant
* can be installed on the main operating systems, including Windows
* better support for re-using of build rules across local and remote repositories
* switching to different branches wouldn’t mean rebuilding build tool
* extensible rules
* failed tests are not cached
* flaky tests are re-run multiple times
* error prone static analyzer integration out of the box
I would like to thank Shawn for supporting this project, and reviewers/contributors:
Han-Wen Nienhuys, David Pursehouse and Damien Martin-Guillerez from Bazel team.
Also big thanks to Luca and GerritForge for helping out with the CI and running a *lot* of tests.
Here is my related talk from Gerrit User Summit 2016: [2].
[1] https://bazel.build
[2] http://ostrovsky.org/gerrit/bazel-build-gerrit”
Allow plugins to define “has” search operands
Author: Martin Fick
Changes: https://gerrit-review.googlesource.com/#/c/91514/
Plugins can define new search operands to extend change searching.
Plugin methods implementing search operands (returning a
`Predicate<ChangeData>`), must be defined on a class implementing
one of the `ChangeQueryBuilder.ChangeOperandsFactory` interfaces
(.e.g., ChangeQueryBuilder.ChangeHasOperandFactory). The specific
`ChangeOperandFactory` class must also be bound to the `DynamicSet` from
a module’s `configure()` method in the plugin.
The new operand, when used in a search would appear as:
operatorName:operandName_pluginName
A sample `ChangeHasOperandFactory` class implementing, and registering, a
new `has:sample_pluginName` operand is shown below:
@Singleton
public class SampleHasOperand implements ChangeHasOperandFactory {
public static class Module extends AbstractModule {
@Override
protected void configure() {
bind(ChangeHasOperandFactory.class)
.annotatedWith(Exports.named("sample")
.to(SampleHasOperand.class);
}
}
@Override
public Predicate<ChangeData> create(ChangeQueryBuilder builder)
throws QueryParseException {
return new HasSamplePredicate();
}
Zoekt
Author: Han-Wen Nienhuys
Changes: https://gerrit-review.googlesource.com/#/q/before:2016-11-17+after:2016-11-10+project:zoekt
Han-Wen has officially announced at the Gerrit Hackathon, the general availability of the Zoekt code search engine.
“Hi there,
I’d like to announce “zoekt”, a search engine for source code I wrote over the last month or so. It was made to work well with (large) Git based repositories, so I think some of you may find it useful.
If you’re interested in code search, please try it out, and let me know about your experiences.
http://github.com/google/zoekt
http://gerrit.googlesource.com/zoekt
I didn’t do any work to try and integrate it with Gerrit/Gitiles, but
if someone wants to invest effort in making that happen, I’d be
happy to review CLs. “
ElasticSearch Index
Authors: Hugo Ares, Dariusz Łuksza
Changes: https://gerrit-review.googlesource.com/#/q/before:2016-11-17+after:2016-11-10+project:gerrit+message:elasticsearch
Small steps towards the goal of having ElasticSearch integrated as Gerrit secondary index:
– On-line reindexing (in-progress)
– Accounts indexing (in-progress)
Plugin examples
Author: Martin Fick
Changes: https://gerrit-review.googlesource.com/#/q/before:2016-11-17+after:2016-11-10+project:plugins/examples
Gerrit cookbook has become over the years a mix of different type of plugins functionality. That is good and bad at the same time. A typical “cookbook” should have a set of recipes for obtaining a final dish ready to eat … whilst our was more like a mixed salad with a bit of everything.
Martin started the noteworthy task of reorganizing the cookbook in a set of self-contained example, hopefully, easier to manage and with a clearer understanding.
Cassandra Repository Manager
Author: Haithem Jarraya
Changes: https://gerrit-review.googlesource.com/#/q/before:2016-11-17+after:2016-11-10+project:libs/modules/repomanager/cassandra
Haithem started a new change (still in draft at the moment) for plugging an alternative JGit DFS implementation to the Gerrit repositories. It is the very first time that such a challenging goal is attempted outside Google data-centers and BigTable/GFS infrastructure. If we succeed in completing the implementation and demonstrating that the resulting architecture is more robust and scalable than the local file-system, it would be a first 100% OpenSource distributed JGit backend ever.
Gerrit LibModules
Author: Luca Milanesio
Changes: https://gerrit-review.googlesource.com/#/q/message:libModule+after:2016-11-10+project:gerrit
Luca discussed how to “plug” an external repository manager into Gerrit: it is something “similar” to a plugin but more fundamental to the system. Differently from a plugin, it needs to satisfy the following requirements:
- Loaded at start-up time only
- Cannot be unloaded
- Must be injected in the primary Gerrit sys injector
It is not the first time that we need to introduce a “modular piece of software” which isn’t part of Gerrit Code Review:
- Java CryptoProvider – BouncyCastle
- Encrypted secure store for gerrit.config
- Servlet filter for authentication and SSO
- JDBC Interceptor for JavaMelody
- Multi-hosted Git repository directories
Instead of creating “yet another exception” in Gerrit, we discussed amongst the hackathon members and agreed to come up with a new concept: LibModules.
The rationale behind the name is:
- They need to be loaded from the same Gerrit class path from /lib
- They provide extra Guice modules to be added to the sys injector at start-up
The configuration of a set of LibModules in Gerrit is straight-forward:
[gerrit]
installModule = com.mycompany.MyModule
installModule = com.googlesource.gerrit.modules.FancyModule
Now that the change is merged and the new concept has become part of Gerrit, we are expecting a growing number of LibModules to become available.
Removal of references to LocalDiskRepositoryManager
Authors: Hugo Ares, Shawn Pearce
Changes: https://gerrit-review.googlesource.com/#/q/before:2016-11-17+after:2016-10-11+project:gerrit+message:LocalDiskRepositoryManager
Shawn and Hugo started removing the explicit references in Gerrit to the local filesystem for resolving Git repositories. Those changes are needed to fully support an alternative implementation of a Repository Manager not based on a local filesystem anymore.
DynamicBeans for Gerrit Plugins
Author: Martin Fick
Changes: https://gerrit-review.googlesource.com/#/q/before:2016-11-17+after:2016-11-10+project:gerrit+message:DynamicBeans
Until now it has been possible to create new SSH commands or REST API through plugins, which is great but sometimes not enough. Martin came up with a use-case where they need to rather extend the current core commands, without having to necessarily change its code. How can you satisfy this use-case with plugins? Martin has the solution and is called “DynamicBeans”.
It is definitely an interesting use-case that is going to trigger a lot of interest and discussions amongst the Gerrit Community.
Analytics plugin
Author: Luca Milanesio
Changes: https://gerrit-review.googlesource.com/#/q/after:2016-11-10+project:plugins/analytics
One of the things that people are missing in Gerrit, when comparing it to GitHub, is the overall repository statistics:
- List of contributors with number of commits / adds / remove
- Project’s statistics of number of commits over time
The new analytics plugin extends the Gerrit project’s SSH and REST API to expose aggregated data extraction. It is extremely fast compared to GitHub because it works purely in streaming and doesn’t actually load the data in memory. The amount of data generated by the analytics can be huge and is intended to be used by an external analysis and dashboard system. Differently from the typical Gerrit’s API, the returned result has one item per line instead of a big unique JSON object. The rationale is that to generate and process a set of JSON elements in streaming, you need to make each record self-contained and processed independently. That would allow as well batch-processing with a parallel system, without having to parse the entire file content all at once.
Example of how to extract the list of contributors out of a Gerrit project via SSH:
$ ssh -p 29418 admin@gerrit.mycompany.com analytics contributors
{"name":"John Doe","email":"john.doe@mycompany.com","num_commits":1,"commits":[{"sha1":"6a1f73738071e299f600017d99f7252d41b96b4b","date":"Apr 28, 2011 5:13:14 AM","merge":false}]}
{"name":"Matt Smith","email":"matt.smith@mycompany.com","num_commits":1,"commits":[{"sha1":"54527e7e3086758a23e3b069f183db6415aca304","date":"Sep 8, 2015 3:11:23 AM","merge":true}]}
Wrap-up and Summit in 2017
It has been a very intense and revolutionary Gerrit User Summit & Hackathon this year, with a lot of new faces, new contributors and new features coming in the next forthcoming releases.
At the summit, Shawn Pearce and Luca Milanesio announced the proposal to organize the event in Europe for next year, possibly in June/July or Oct/Nov 2017. The reason for changing the location is to attract the feedback from more Gerrit Users that have not been heard so far and increase the participation of the community in the future of the of Project.
The summit has been already endorsed by the major organizations driving the Gerrit Code Review Project and other very active sponsors of the OpenSource Community, including CloudBees, CollabNet, eSynergy, Google, GerritForge, SAP and SkillsMatter which has offered to host the event at CodeNode.
Shawn Pearce, the Gerrit Code Review project founder, will send in the next few weeks a Survey to capture the opinion of this proposal from the Gerrit Community.
See you in 2017 for new and amazing features coming on Gerrit Code Review.
Luca Milanesio – GerritForge.