
The fourth talk of the Gerrit User Summit 2017 edition is Zoekt, an improved fast and secure Code Search engine made by Han-Wen at Google.
One year after its inception, the search engine supports now Unicode v2.0 and is fully integrated with Gerrit ACLs, ready to be used with large enterprise installations.
Say hello to Zoekt, the fast source code search
My name is Han-Wen, I’ve been writing a new source code search engine called Zoekt.
Here is the home page of the search engine and you can see that I am not a Web UI person 🙂
It is running on the public internet on the website hosted by my friends of the Bazel Team.
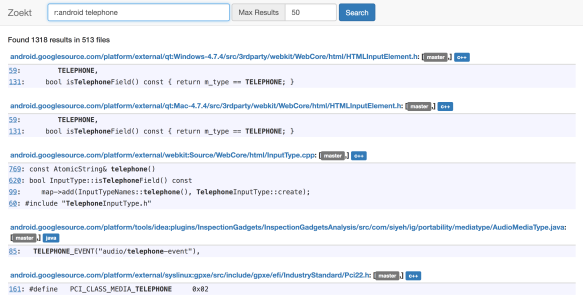
It has a bunch of source code indexed, about 30 GB, which is mostly Google source code. You can search through the Android source code project for things that match “telephone” and get lots of results associated.
Linus Torvalds created the Linux operating system and, as we all know, he has not a very diplomatic use of language. If you want to know where he says “crazy idiot” you can find it in just under 9 milliseconds!
Zoekt is super fast and is OpenSource. You can run it on your server or your laptop, but if you want just to check it out, you can go to this URL: https://cs.bazel.build.
Why I did this?
I work at Google, and I spend most of my time looking at others’ code and trying to understand what is doing. Frequently I have to dig into code that I don’t know, and I have not necessarily have checked out locally. I use the Google internal code search for that, and I missed it when I started to work on Gerrit. Then I thought: “I can fix that, I can just do it on my own.”
Last year I announced this search code site running on the Bazel site and was a kind of the first instance. I have been running it for one year, finding a lot of bugs and things that could break and developed many improvements and I am going to show you some of them today.
The core of a search engine for code is an engine that can find substrings in a large file of text. They can be arbitrary substrings, and most of the code search engine like to search for words. However, if you take the last char of the word away, e.g. you are not looking for “crazy idiot” but only for “craz idiot”, most search engines like ElasticSearch of GitHub won’t find any match.
ASCII vs. Unicode
Zoekt works, but the implementation was initially based on the idea that everything is ASCII and then any char is one byte. In reality, a lot of text is not just ASCII and, maybe, someone from Sweden has the strange “A” with the circle on top. The character is then is no longer ASCII, and you can’t search for any of their names. That is a bummer, and then I thought “well, it kinda works, but it doesn’t really work”. The regex engine uses Unicode for searching, and that leads to bugs, that means things are right there, but you can’t find them.
That happens surprisingly often like, for example, the source code of this project which has Unicode characters because it has some tests about Unicode. Finally, this is just a bug, and to me, this is pretty much like the mountain Everest.

Why do people climb mountain Everest? Because it is there. And why I wanted to fix this bug? Because the bug was there.
Triagrams
Before you can understand what the bug is, you need to understand what Unicode is and how it works so that you can understand why the code was not working before.
The basic idea of code searching is that you build an additional data structure that helps you find things in a large chunk of text.
For example, we have two files, one contains the word “code” and the other contains the word “model”. What we do is split it out into two sequences of three characters, and we record the offsets of each of those group of threes: we call them triagrams. Then we create an index of the triagrams and the associated offsets. If you want to look for “temp 50C max”, you take the first group of three characters which is “tem” and the last group which is “max”. Then you look for this with exactly the distance of 10 characters apart, because with this data structure over here we can do this very efficiently.

So we are looking for the characters “tem” and in the data structure over here we should find something that matches “tem” and you only have to look at one row over here and may to another one row over there. Finding if a string is not there is very quick and, if the string is there, these offsets will give you the position for a real string search.
In practice, you always want to look for things disregarding case. In this case, if you ‘re going to do it case insensitively you can generate all the different flavor of cases, for the first and the last triagram, and then you can do the same strategy again.
What about Unicode?
Unicode, in essence, is a mapping from numbers to meanings, for example, the Unicode number 24991 is the Chinese character “Wen” which is part of my name. So, it is a huge book which is a sequence of numbers mapped to a list of different characters.
The predecessor was ASCII in 1963 where you find the common characters like “abcd”. In 1988 Unicode Ver. 1.0 introduced a space for 65 thousand characters; the people that invented it were not too familiar with Asian languages because it turns out that you can fill a lot of Chinese and Japanese into that but if you want to have all the characters it is a little bit tight on space. In 1996, Unicode Ver. 2.0 introduced a 21-bit space with the ability to represent up to 2 millions of characters, including as well this Egyptian character and the “poo” emoji.
UTF-8 encoding
It is important to remember that Unicode is merely a book of numbers and their associated characters. It doesn’t say anything on how you store this data and that is why you need an encoding format. There are different encodings, but the one that has won is UTF-8. It uses a scheme where the ASCII characters have a first 0 bit at the beginning and then 7 bit of data. If you have a character that needs more space, you start using multiple bytes for its representation.

The advantage of this approach is that ASCII stays ASCII. It is nice because the reality most strings are effectively ASCII and then remain ASCII which is a space saving. The disadvantage is that characters can occupy a variable amount of space; if you want to index them you don’t know where the characters start anymore. For most indexing, this is not a big problem, but unfortunately for code search, it is.
Why bother? We can still just make trigrams out of Unicode characters and look for their indexes. This kind of works, except that there a catch. Suppose that you are not searching for the temperature of 50 Celsius max, but you are searching for 323 Kelvin max. So if you are using Unicode, you could be looking for the lowercase k the capital K or Unicode symbol 212A which is the symbol for Kelvin degrees. It turns out that the Kelvin symbol takes 3 bytes, and so if I am looking for the string over here I want to look for “tem” and “max” but what distance do I pick? Because if someone is using Kelvin in Unicode, the distance is 12 but if I use K the distance is 10. The scheme isn’t working anymore.
I changed the triagrams to work with Unicode. I have used 64bit, and the three times 21-bit is 63 which fits nicely and works efficiently for all the offsets regarding Unicode code points.

So if we take the example earlier, we have Egyptian character and the “poo” emoji. So you can still search using this table over here, you can find where concerning Unicode code points the string is. If you want to use the actual comparison you need to find the offset in the file in bytes so that you can start making the real string comparison. So we have an extra table with the offsets with the mapping between the Unicode code points and the corresponding bytes offsets. You can see that the codepoint at offset number 6 is at byte 9, and so, it works!
Zoekt hosted by the Bazel project
I’ve put this on a machine that is hosted by the Bazel project, so it runs on the Google Cloud infrastructure on https://cs.bazel.build. As I work at Google, this is also nice because I can understand what customers go through when they want to use our products. Deploying is always good because when you need to start using your software for real, you then find the actual bugs and the real issues.
Code Search and Security
Of course, Google is a company that takes security and privacy seriously. Zoekt is a project that I do for fun, spending a couple of hours of free hacking time once a week and I don’t want to have any trouble with security.
One way to get into trouble is to set Cookies on your site, and then you’re subject to various laws in various countries, multiple lawyers will talk to me, and I don’t want that.
Another way to get into trouble is to have a security breach. If you do something that compromises the machine and opens it up to bad people, bad people to bad things with it and then other people from Google come to me and make my life difficult, and I don’t want that. Does anybody recognize this image? As a cultural reference, this is an image from “The Matrix Reloaded” where Trinity uses an existing exploit from SSH to access to the power grid of The Matrix. One of my personal goals is also to not be in any movie where the bad guys try to get in: don’t be implicated with bad guys in the film.
Threat model
What do I have that people want to steal from me? In case of a code search engine, if you’d be indexing private code and someone would want to leak that code; in this case this is not a problem since I am indexing Open Source code, so it is all public.

There is an SSL key to keep the traffic going securely so if someone steals that key and can make a man-in-the-middle attack and show source code that subtly different from the real thing and how bad would that be? In my case, this is not a problem because the Google Infrastructure provides the load balancing. You upload your private key into the load balancer, and then the only way to compromise it is hacking your Google account which is very well protected.
There is an access token needed to get the code into the indexing machine for processing. In my case is a GitHub public token, so it is not a big deal if it is getting lost, but possibly Google will get very upset with me if that is getting misused.
Finally, if you can get access to the machine, you can do any of the above. You can use it for other attacks, to mine bitcoins and to do many different bad things. Again, I don’t want these things happening because people come and speak to me, talk to my manager and I don’t want bad things happening to me because of a project that I do for fun.
So, how would you get into such a system? The search engine itself is written in Go, which is a memory-safe language. The worst thing you could do is to make it crash and then it gets restarted again. So no big deal. But there is one part of the search engine that is important which is the thing that provides symbols. When you are looking for something you typically want to have the definition of a symbol. I am using a problem called ‘ctags’ for that, and this is a problem written in C that parses lots of languages. It understands where the identifiers definition are so that I can get better search results.
But CTags is written in C and if someone would have control to the source code that I am indexing could create source code that looks suspicious and maybe exploit some error in this hundred of thousands of lines of C code.
For example, the ANSI C standard says that identifiers can be at most 32 chars. I hope they didn’t do it but suppose that CTags used a fixed buffer size for that and someone creates a commit that introduces this variable that overflows a buffer. Then it may overflow the buffer and try to dial a four pin number: that would be bad.
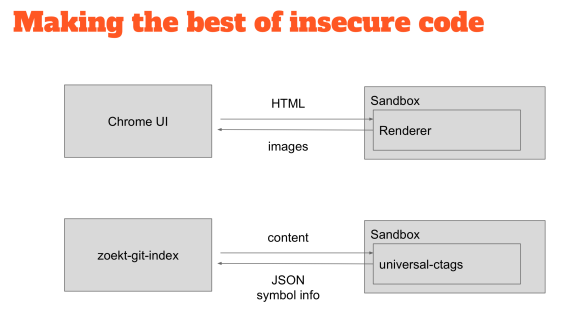
So how do you deal with that? You can take inspiration from other projects, which have the same problem, so Chrome, for example, is one of the most secure browsers out there because it uses sandboxing. So the part that renders HTML which is entirely untrusted is put inside sandbox where they can do almost no damage.
If you find a problem in the renderer that you can exploit, then you’ll find yourself in a place where you cannot do any damage. I have used the same technique for the indexer. I run the untrusted binaries inside the sandbox, I ship the content to the CTags binary, and the CTags binary responds with JSON containing the symbol definitions.
It uses seccomp which is available only on Linux. You start the program by declaring what system calls it can do, allocating the memory, providing the input and you then get the output. When you exit there is as well a system call that, if you can forget to exit from the process, it will automatically kill the sandbox. All of the above is all done by seccomp.
As you can see in this picture, I am now peacefully sleeping because everyone is secure and I don’t have to worry about anything anymore.

Gerrit ACLs
We had a hackathon yesterday, and I have thinking about this idea for a while, and I thought that I would have to go to tackle the Gerrit ACLs integration during those days. The overall ACL model in Gerrit is very sophisticated, so the only way to understand if someone can read a piece of source code is just to ask Gerrit “can this person see this source code?” A component of the solution is an ACL filter in the middle when you contact a web server to search something you typically start on the Web server and then it looks at all the different indexes to ask for a search result.
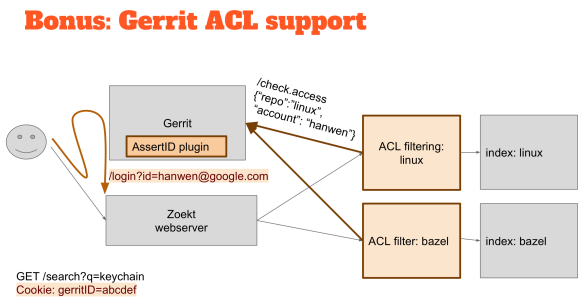
For the Gerrit support, I’ve put something in the middle that if you want to search for the code, it asks Gerrit if that person has permissions to read that code and to be able to execute the search. If the person doesn’t have the permissions, you just don’t return any result.
Gerrit SSO
So how do you know who the person is? I added some HTML magic that in case you don’t have a specific cookie you go to Gerrit and there is a little plugin that redirects back to the web server. So the plugin knows who you are on the Gerrit domain and using a redirect can tell the Web server your identity.
I am the administrator in Gerrit, as you can see over there on the top, and so if I go to Zoekt, then you can see in the corner that I am an Administrator there as well. That goes very quickly because now runs locally, but in reality, it does a redirect to Gerrit, and then Gerrit sends a redirect back to Zoekt.
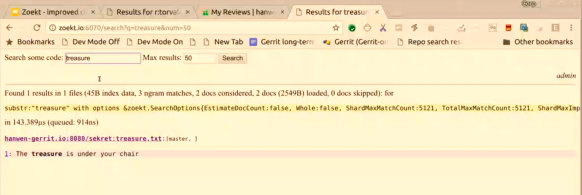
If I want to search for things, I can find results in the “secret” repository. So if I now were to log out from Gerrit, there is another redirect to make sure that I am also logged out from the Zoekt, and now if I try to access the search engine I got “how no, who are you?” you have to authenticate.
I can now become another person, logging in as Rebecca; looking at Zoekt, I am Rebecca as well. If I try now to search for the treasure in the “secret” repository, hopefully, it doesn’t work: so “no results” right?
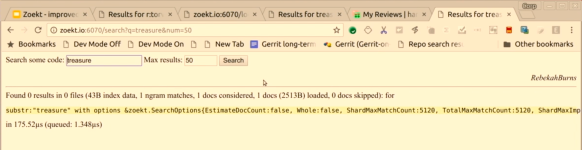
That is how ACL support could work, regarding the overall idea on how to make this work, the piece that goes from here to there was a little bit complicated, but I think it is a decent idea. The plugin in Gerrit that does this redirect is quite hacky, and in a real deployment, you have to integrate to whatever authentication system people have on site.
I don’t know how LDAP works and so if anyone is interested in this and wants to have this, and there to make it work but then need some help on how to integrate with external authentication providers.
Questions
Q: (Martin Fick – Qualcomm) How do you envision this working by knowing Projects and Branches that users can use and be doing in a performant way in case they can’t read most of the information on the server?
A: The ACL filtering can cache that information, and my idea is that all pre-loading of ACLs can be cached to whether the user has access to it or not.
Q: So only at the repository level? Not at the branch level?
A: So this check access endpoint, I added it because we had people misconfiguring their Gerrit server leading to confidential data being leaked. People should test this so I made it so that people can pre-verify that people had no access to it has support for branches as well, but that part has been left off the slides though.
Q: So from a performance standpoint. Suppose you have a large amount of stuff you can’t see, would you be taking into account what you is authorized to see before you run the query?
A: Yes, it happens before the query goes into the index. So if the person has no access to it, you skip the search for the piece of data that person has no access to it.
Q: So if on the other side they have access to a lot of things and a lot of refs, then the filtering may be slow on the frontend.
A: Wow, this is basically what I have implemented in two days. Real life tests would be helpful. I would love people to try out and tell me how well it performs, so, let me know.
Q: So, does that mean that index is done once and access control is done afterward. So that indexing is not dependant on the access.
A: The indexing is usually done off-line on a cronjob because it generates a lot of data. The entire point of the indexing is to make the online search queries very fast and not doing the indexing when the person is looking for the document.
