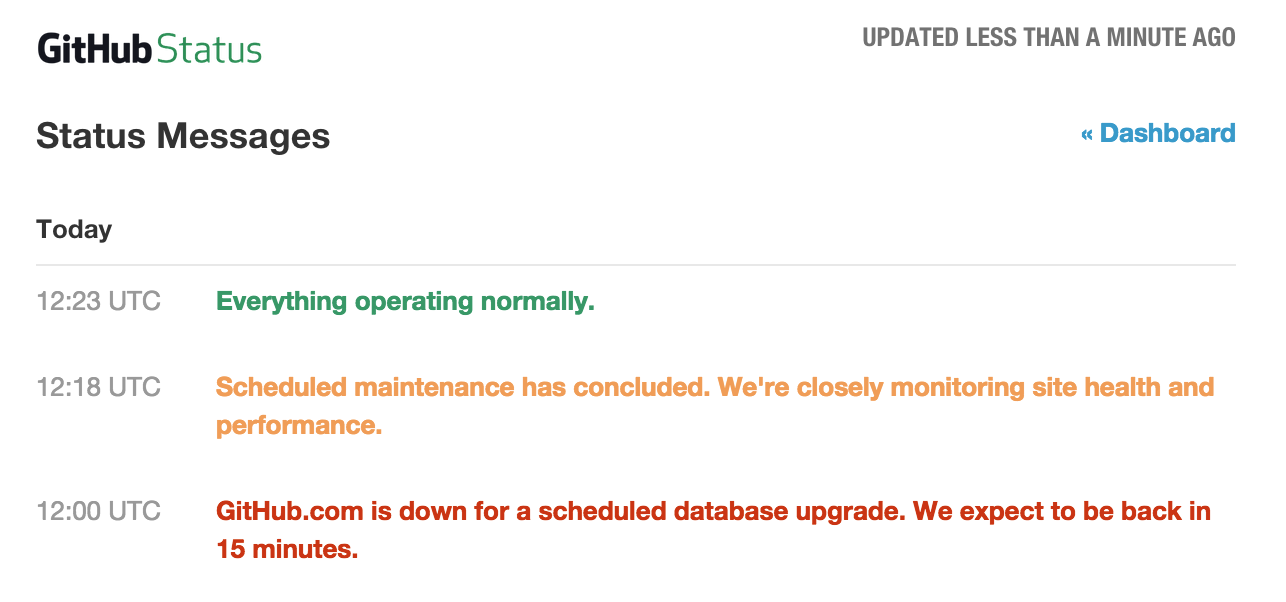
Where is this coming from?
Yesterday GitHub was down for a DB upgrade, an outage that overall lasted for 23 minutes. This may not sound a problematic downtime at all, but when you think that nowadays GitHub is used not only for Software development worldwide as a Git server but as also as a source and binary packaging repository and distribution centre, a Markdown pages server and possibly much more … and you multiply by the number of users / repos hosted, then 23 minutes may translate in a significant disruption and, for some mission-critical business use-cases, even financial loss.
We never needed planned outages for DB upgrades on Gerrit Code Review used for a lot of other OpenSource projects (ranging from Android to Chromium): how the Gerrit team is managing to outperform GitHub? I asked Shawn Pearce to spend some time to describe how his team at Google managed to implement its roll-out strategy in the delivery pipeline going through tons of major DB upgrades with zero downtime worldwide.
He kindly responded on the Gerrit Code Review mailing list with this post, and we are very thankful for having shared his experience with us, hoping that GitHub guys will read this post and may learn from it for future GitHub DB upgrades.
I am reporting here Shawn’s post AS-IS, in order to maximise the audience and enable more people to access its content.
How googlesource.com manages database upgrades with no downtime (by Shawn Pearce)
In light of the recent GitHub database outage, Luca Milanesio asked me to describe how googlesource.com has managed nearly 3 years of database upgrades with zero downtime. So… here is an attempt. 🙂
tl;dr: protobuf, Bigtable, and multi-master.
Long version…
Bigtable … not SQL
Years ago we settled on using Google Bigtable as the backing database for googlesource.com instead of MySQL or PostgreSQL. This decision actually came about because of virtual hosting (see below), not because Google is any better at running Bigtable than MySQL or PostgreSQL (we run those well too).
Briefly, Bigtable is a NoSQL database that organizes data into tables of column families; read the Bigtable paper for an overview. Rows can contain irregular shapes of columns, and two rows in the same table do not need to have the same layout (columns).
To support Gerrit Code Review I hand-wrote a complete implementation of the ReviewDB interface and all of its sub interfaces to transport data between the application and Bigtable.
Data is stored in ~3 Bigtables:
Accounts: Accounts, AccountDiffPreferences, AccountExternalIds, …
Changes: Changes, PatchSets, PatchLineComments, …
SiteData: AccountGroups, AccountGroupByIds, …
We mash data for multiple ReviewDb tables into the same Bigtable by assigning the tables to different column families. Data for an Accounts row goes into the “Accounts.data” column family, while data for an AccountDiffPreferences row goes into the “AccountDiffPreferences.data” column family. E.g.:
row: 100151 # account_id
Accounts.data:
... data for account object ...
AccountsDiffPreferences.data:
... data for diff pref object ...
Our guiding principal for what goes where is based (mostly) on the primary key declaration. If Account.Id was first in the primary key, the row(s) go into the Accounts Bigtable. If Change.Id was first in the primary key, the row(s) go into the Changes Bigtable. This means the StarredChanges data is stored in the Accounts Bigtable, and PatchLineComments is in the Changes Bigtable.
Everything else that didn’t quite fit the Accounts or Changes pattern went into SiteData. AccountGroups for example are in SiteData.
To be honest, this is all arbitrary. I could have randomly assigned ReviewDb tables to Bigtables. Or put them all in a single Bigtable.
Creating new tables
New table creation is handled by pushing a new column family to Bigtable. This is an online operation that does not require changing any existing data. Internally column families are just unique tags written before the stored data. Adding a column family just assigns a new tag that has not been used yet.
Protobuf
The really important part of our online schema upgrade process is actually Google protobuf.
Bigtable doesn’t store structured data. Bigtable stores sequences of bytes in column families. Googlers get structure by storing encoded protobuf messages in column families. Protobuf encodes messages by writing a unique integer tag before each field. The tag allows readers to match data back up to the runtime object during decoding.
Protobuf gives us very critical features:
– Unknown fields are skipped (and ignored). If a field has been deleted from the model, but still exists in data records, the application code can safely skip over that data by reading the tag, recognizing its an unknown field, skipping its encoded bytes, and continuing onto the next field.
– Unknown fields are preserved. If a field is not recognized its encoded bytes are kept in memory. When the application makes changes to a message and writes the message back to the database table, the unknown fields are preserved and written back as-is.
– Fields can be missing. If a field is not present in the data, it simply has no tag present in the encoded message. The field is assumed to be its default value by the application.
Each database table in ReviewDb is described by its own protobuf message. The @Column() annotations in ReviewDb include the unique field numbers used by protobuf to tag data in encoded messages. You can see this schema by printing the protobuf schema out:
java -jar gerrit.war ProtoGen -o reviewdb.proto ; cat reviewdb.proto
In our Bigtable mapping the Gerrit application server encodes an Account object into a protobuf message, then writes the encoded protobuf to the Accounts.data column family. Reading from the database is merely the reverse process.
Column deletion
Columns can be removed from a table by removing its @Column annotation from the Java object. The field definitions will be omitted from the protobuf description. New application code that reads from the database table will skip over the (now unknown) field. During updates of a row the deleted/unknown field will be preserved and written back to the database table.
It is very important that the field number is never reused.
Nothing prunes the old fields from the Bigtable. Disk storage is cheap, disk IOs are not. Leaving the deleted data on disk is cheaper than scanning through every row and clipping out the deleted fields.
This is why we leave deleted fields commented out in source code, so future developers know not to reuse a field number.
Column addition
Columns can be trivially added to an existing table by assigning a new field number. When newer application code reads an old record it won’t find the new tags and will simply assume the default that is supplied in the protobuf description.
Unfortunately the defaults used in @Column annotations don’t always match with the real intended defaults. We have had to hack this at Google by applying a patch to every version of Gerrit for 2 fields:
- optional bool size_bar_in_change_table = 16;
+ optional bool size_bar_in_change_table = 16 [default = true];
optional bool legacycid_in_change_table = 17;
optional string review_category_strategy = 18;
- optional bool mute_common_path_prefixes = 19;
+ optional bool mute_common_path_prefixes = 19 [default = true];
The open source project chose to apply these defaults using Schema_NNN upgrade files that rewrite all existing accounts to set the fields true during init. We do not have that luxury and instead patch every release we make to assume the “correct” default if the field is not present in the stored data. This is why I lobby so hard against boolean columns being true by default via Schema_NNN upgrades. 🙂
Because of the unknown field properties described earlier, it is (usually) safe to run newer binaries alongside old binaries against the same database. A newer binary may store new fields to a row. The older binary will ignore these, but preserves the unknown field data during updates.
Of course cross-field semantics could be confused if we attempted this. We limit our risk by staying close to HEAD and try really, really hard to avoid cross-field semantic issues (e.g. anything like status and open in changes).
Column rename
We really don’t care about column renames. The column names themselves are not stored in Bigtable or in the encoded protobuf messages. Column names are only in the application software. A column name change is just a recompile, similar to a method name change.
What we cannot do is change field IDs. Once used in an @Column annotation, we are stuck with that ID number forever. 🙂
Virtual Hosting
googlesource.com implements virtual hosting for hundreds of Gerrit sites. All sites are combined together into the same 3 Bigtables by prefixing each row with the site name, for example:
row: gerrit:100151 # $site:$account_id
Accounts.data:
... data for account object ...
AccountsDiffPreferences.data:
... data for diff pref object ...
The application server itself is virtual hosted by running a javax.servlet.Filter in front of Gerrit. The filter extracts the host name from the HTTP Host header and stores it somewhere accessible by the hand-coded ReviewDb implementation. All database operations include the host name as part of the row keys being accessed.
It is this virtual hosting strategy that forced our hand and required such smooth online schema migrations.
When we update the binary, we update the binary for hundreds of “servers” at once. We can’t shutdown everyone for 200 * 5 minutes to upgrade 200 sites at 5 minutes each while we run a Schema_NNN process serially. We also don’t want to use 200 CPUs to update 200 sites in parallel during a global 5 minute downtime window, too much can go wrong, and there will always be straggling sites. Neither option appealed to us.
So smooth online migrations it was. 🙂
Multi-master hosting
We don’t run one Gerrit server. We run many Gerrit servers against the same Bigtables. Requests load-balance across this pool of servers, based on a number of factors that are out of scope for this particular article.
We use this multi-master hosting to help do online binary upgrades of Gerrit.
Given N servers where N >= 3:
1) we take one out of the load balancing rotation
2) wait for in-flight requests to finish
3) stop the process
4) install the new version
5) restart it
6) add it back to the rotation
7) goto 1
We size N such that N is larger than the number we actually need to handle traffic; this allows us to lose a server without impact to traffic to do the upgrade dance.
Linux operating system upgrades can be coordinated the same way, as the servers are on different machines.
Multi-data center hosting
Given multi-master hosting, we don’t put all of our servers in the same data center. We run them in multiple data centers and allow the load balancers to route across all of them.
This strategy allows us to perform data center level maintenance without service interruption by taking some servers out of the load balancing rotation before maintenance starts.
Sometimes data center level maintenance is power related; e.g. servers may need to be shutdown to repair a failed UPS. Other times its database related. I recently corrupted a database replica in one data center by accident. I “shutdown” our servers in that data center while I manually restored a known good database. Nobody except my team at Google knew about my mistake, or the impact.
Once you are multi-data center, cross-site database consistency becomes an issue. Frankly we just reuse Google Megastore to get cross data center consistency based on a high quality Paxos implementation. Each of our data centers has a full copy of the database local to it and Paxos is used to ensure the application has a consistent view.
And by this point, you are probably wishing you had stopped at the tl;dr … 🙂