Slow Git isn’t just annoying – it’s expensive for everyone: developers wait for a CI/CD validation of their changes, SCM admins are wasting their time in fire-fighting SCM slowdown and broken pipelines, IT managers are wasting millions of dollars in CPU and Disk hosting costs.What if your Git operations could be up to 100x faster, and keep up with the new AI-vibe coding landslide of PR and changes?
100x Faster Git, Powered by AI
GHS is an AI-based accelerator for Git SCM that redefines performance:
Up to 100x faster clones and fetches.
CI/CD pipelines that run without SCM barriers.
Adapt automatically to your repository shape and make it faster.
Scale without slowdown even under heavy loads
This isn’t traditional “tuning.” GHS learns your repos and access patterns, then continuously optimises them so your Git server is always running at maximum speed.
How Does GHS Deliver 100x Faster Git?
Measure Everything It collects detailed metrics in realtime on your repositories.
Spot Bottlenecks GHS AI model is trained on recognizing the bottlenecks and take immediate action, before they become a problem
Stay Fast Your Git stays consistently accelerated, not just temporarily boosted.
Why Speed Matters
Developers stop wasting hours on slow fetches and builds.
Release managers push features out faster.
IT leaders reduce infra costs by doing more with less.
Admins no longer fire-fight performance issues.
Every 1% of time saved in Git can add up to days of productivity across a large team. Imagine saving 100x that.
Who Needs 100x Faster Git?
Repositories of all sizes: AI-driven code generation and “vibe-coding” have dramatically accelerated the pace of software delivery.
Enterprises that have adopted the AI-pipeline want that value delivered faster to production.
Any team frustrated with slow CI/CD pipelines.
The GHS Advantage
Transformative speed: not just 2x or 5x faster, but up to 100x
SCM expertise: GerritForge’s decades of enterprise SCM know-how built in.
Proven reliability: Stability and uptime as performance scales.
Get Started Today
You can try GHS free for 30 days and experience the difference for yourself.
First, a huge thank you to the OpenInfra Foundation for hosting this event in Paris. Their invitation to have the Gerrit User Summit join the rest of the community set the stage for a truly collaborative and impactful gathering.
Paris last weekend wasn’t just a conference; it was a reunion. Fourteen years after the last GitTogether at Google’s Mountain View HQ, the “Git and Gerrit, together again” spirit was electric.
On October 18-19, luminaries from the early days (Scott, Martin, Luca, and many others) reconvened, sharing the floor with the new generation of innovators. The atmosphere was intense, filled with the same collaborative energy of 2011, but focused on a new set of challenges. The core question: how to evolve Git and Gerrit for the next decade of software development, a future dominated by AI, massive scale, and an urgent demand for smarter workflows.
Here are the key dispatches from the summit floor.
A Historic Reunion, A Shared Future
This event was a powerful reminder that the open-source spirit of cross-pollination is alive and well. The discussions were invigorated by the “fresh air” from new-school tools like GitButler and Jujutsu (JJ), which are fundamentally rethinking the developer experience.
In a significant show of industry-wide collaboration, we were delighted to have GitLab actively participating. Patrick’s technical presentation on the status of reftable was a highlight, but his engagement in discussions on collaborative solutions moving forward with the Gerrit community truly set the tone. It’s clear that the challenges ahead are shared by all platforms, and the solutions will be too.
Scaling Git in the Age of AI
The central theme was scale. In this rapidly accelerating AI era, software repositories are growing at an unprecedented rate across all platforms—Gerrit, GitHub, and GitLab alike. This isn’t a linear increase; it’s an explosion, and it’s pushing SCM systems to their breaking point.
The consensus was clear: traditional vertical and horizontal scaling is no longer enough. The community is now in a race to explore new techniques—from the metal up—to improve performance, slash memory usage, and make core Git operations efficient at a scale we’ve never seen before. This summit was a rare chance for maintainers from different ecosystems to align on these shared problems and forge collaborative paths to solutions.
Dispatches from the Front Lines: NVIDIA and Qualcomm
This challenge isn’t theoretical. We heard powerful testimonials from industry giants NVIDIA and Qualcomm, who are on the front lines of the AI revolution.
They shared fascinating and sobering insights into the repository explosion they are actively managing. Their AI workflows—encompassing massive datasets, huge model binaries, and unprecedented CI/CD activity—are generating data on a scale that is stressing even the most robust SCM systems. Their presentations detailed the unique challenges and innovative approaches they are pioneering to tackle this data gravity, providing invaluable real-world context that fueled the summit’s technical deep dives.
Beyond the Pull Request: The Quest for a ‘Commit-First’ World
One of the most passionate debates centered on the developer workflow itself. The wider Git community increasingly recognizes that the traditional, monolithic “pull request” model is ill-suited to the “change-focused” code review that platforms like Gerrit have championed for years.
The benefits of a change-based workflow, cleaner history, better hygiene, and higher-quality atomic changes—are driving a growing interest in standardizing a persistent Change-ID for each commit. This would make structured, atomic reviews a first-class citizen in Git itself. The collaboration at the summit between the Gerrit community, GitButler, JJ, and other Git contributors on defining this standard was a major breakthrough.
This shift is being powered by tools like GitButler and JJ, which are built on a core philosophy: Workflow Over Plumbing. Modifying commits, rebasing, and resolving conflicts remain intimidating hurdles for many developers. The Git command line can be complex and unintuitive. These new tools abstract that complexity away, guiding users through commit management in a way that feels natural. The result is faster iteration, higher confidence, and a far better developer experience.
AI and the Evolving Craft of Code Review
Finally, no technical summit in 2025 would be complete without a deep dive into AI. The arrival of AI-assisted coding is fundamentally shifting the dynamic between author and reviewer.
Engineers at the summit expressed a cautious optimism. On one hand, AI is a powerful tool to accelerate reviews, improve consistency, and bolster safety. On the other, everyone is aware of the trade-offs. Carelessly used, AI-generated code can weaken knowledge sharing, blur IP boundaries, and erode a team’s deep, institutional understanding of its own codebase.
The challenge going forward is not to replace the human in the loop, but to strengthen the craft of collaborative review by integrating AI as a true co-pilot.
A Path to 100x Scale: The GHS Initiative
The most forward-looking discussions at the summit centered on how to achieve the massive scale required. One of the most promising solutions presented was GHS (Git-at-High-Speed). This innovative approach is not just an incremental improvement; it’s a strategic initiative designed to increase SCM throughput by as much as 100x.
The project’s vision is to enable platforms like Gerrit, GitLab, and GitHub Enterprise to handle the explosive repository growth and build traffic generated by modern AI workflows. By re-architecting key components for hyper-scalability, GHS represents a concrete path forward, ensuring that the industry’s most critical SCMs can meet the unprecedented demands of the AI-driven future.
The Road from Paris
The Gerrit User Summit 2025 was more than a look back at the “glorious days.” It was a statement. The Git and Gerrit communities are unified, energized, and actively building the next generation of SCM. The spirit of GItTogether 2011 is back, but this time it’s armed with 14 years of experience and a clear-eyed view of the challenges and opportunities ahead.
So you think PRs are the only way you can do effective code review? Well, then you’ll be surprised to hear that ain’t the case!
If you’ve read my previous article, you’ll be aware that GitHub or GitLab are great for quick and easy integrations with CI/CD tooling and average for issue tracking/planning, but, in my opinion, miss the mark when it comes to facilitating effective code review.
Today, I want to show you a typical Gerrit workflow and explain why I believe it can greatly improve the quality of your reviews.
Let’s start by reiterating that PRs should be small so as to be easily reviewable, and it’s the creator’s job to make sure they are paired with a meaningful description. But don’t take it from me, you can read it directly on GitHub’s blog.
However, splitting out work into easily reviewable chunks is not easy or intuitive when following a PR-based approach as maintaining dependent PRs is cumbersome and error-prone, so let’s see how Gerrit facilitates this for developers.
Relation chains vs PRs
Let’s say that you’ve started working on a new feature. You realize early on that it’ll be a lot easier to implement if you do some refactoring beforehand. So you go ahead, do the refactoring, commit your work, then add the new feature and commit that too, as a separate commit. If you’re working with a PR based workflow, before doing the above you’ve probably created a branch and are now about to push it to the remote to then create a PR from the UI, am I right?
Well, if you’re using Gerrit, you don’t need to do that. If your work is supposed to be merged on main, then you can develop directly on that branch, create those 2 commits and push them with git push origin HEAD:refs/for/main, we’ll decompose this command later, but for now let’s look at the effects of it.
As you can see in the screenshot above, Gerrit detects that you’re pushing two separate commits, so it automatically creates 2 new changes, one for each commit, against the branch you’re working on. There was no need to interact with the UI either.
But how did this happen? HEAD:refs/for/<branch-name> tells the Gerrit backend that you’d like to push your current local changes (HEAD) up for review against branch-name Gerrit then does all the magic for you.
Let’s now take a look at the UI:
There’s quite a lot to unpack here, so let’s go in order. First, Gerrit created a Relation chain for us, that includes both commits. Then, in the commit message, we notice something maybe unexpected, a Change-Id. This is Gerrit’s way of tracking updates to a change. From now on, every time we push a new commit with the same Change-Id, Gerrit will understand it belongs to this change and update it accordingly. You could completely change the commit message, but, as long as you leave the Change-Id unchanged, Gerrit will understand where it belongs.
So let’s try doing that.
How to update changes
The main difference from what most people are used to here is that when you want to update a change, you don’t push a new commit; rather, you amend the existing one
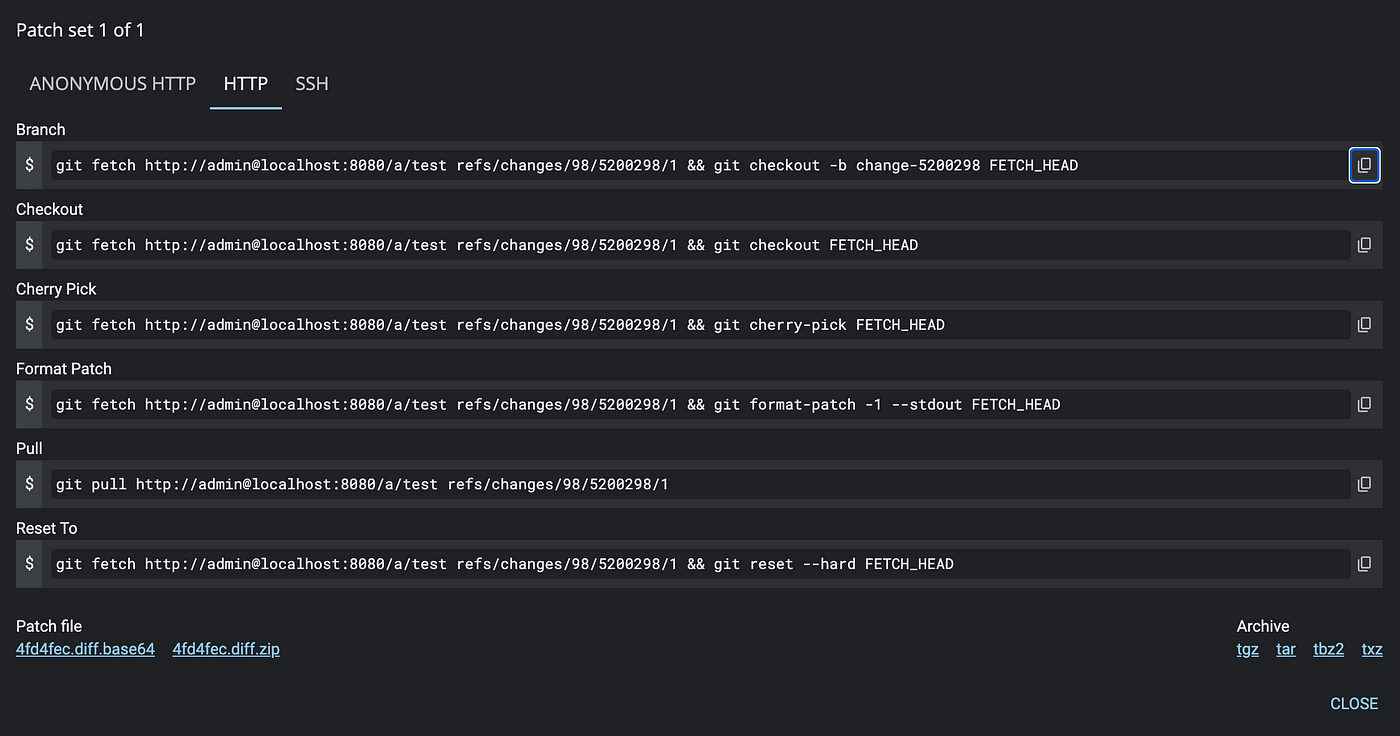
First I need to checkout the change, I can do that by clicking on the DOWNLOAD button(highlighted in the image above), which will show this modal window
This gives me a few options for checking out said change without having to Google how to check out a specific ref or how to cherry-pick each time. So, I copy-paste the “Checkout” option and then run the following on my terminal.
You can see here that I’m not creating a new commit, but rather amending the same one.
Gerrit warns me now that I’ve not amended any files but only the commit message, no problems there, just a handy reminder.
As I’ve not changed the Change-Id, we can see that the change number is still the same. The UI now looks like this:
A few things to notice here. First, I’ve updated the commit message to add a description, great, but surely I wouldn’t want to lose track of the initial state of the change? Can I still see the previous version of this commit? YES!
When you amend your commit, you’re not losing the history of what was there before, you’re merely adding a new patchset to the change. Patchsets are what Gerrit calls each iteration of the commit.
You can also see how the next commit in the relation chain is now marked as an “Indirect relation.” This is because it is not based anymore on the latest version of its parent commit, which as just been updated, so let’s go ahead and fix it. First, we’ll need to select the commit we want to update and then click on the handy “Rebase” button, which will show the following modal
As this is a straightforward case, we’ll confirm the rebase on the parent change.
We can now see that the indirect relation message has disappeared. But how did Gerrit keep track of that? By creating a new patchset which tracks the updated version of the parent commit! Pretty neat, huh?
This leads us to our next topic:
Meaningful commit messages by design
Another problem I see with the PR workflow, or at least how it’s been implemented by the most popular tools today, is that it essentially leaves it up to each individual developer to commit meaningful messages. Whatever merge strategy you pick, neither of them allows for the commit message to be reviewed before it gets merged.
In Gerrit there is no PR description, the commit message IS the “PR description”. Further more, the commit message appears as file in its own right and users can comment on it. This allows reviewers to actually add comments on the message itself to ensure it’s up to scratch with whatever the company standards are.
Submitting the change
Finally, once the comment has been addressed and the change approved, we can click on Submit including parents, and both changes will be merged to the main.
As can be seen by running git log , which will look like this:
Conclusion
The one thing I’d like readers to take away from this article is that no, PRs are not the only way forward and there are solutions to the old problem of wanting to split up code reviews in more manageable chunks.
So let’s quickly review how Gerrit works: You create changes by pushing commits using the “magic” command refs/for/<bran-name> . When you want to update a change, you don’t push a new commit; rather, you amend the existing one. Gerrit keeps track of each update in the form of patchsets so you can see how each commit evolved over time.
You can then chain commits as you wish, allowing you to split your work in easily reviewable units.
Finally, commit messages are treated as first class citizens, they’re like any other file in the change, they can be reviewed and commented on, ensuring that no un-helpful commits are merged to the target branch.
(TL;DR) The Gerrit Code Review project has an ambitious roadmap for 2025 and beyond. Gerrit 3.12 (H1 2025) will focus on JGit performance improvements, X.509 signed commit support, and enhanced Owners and Analytics plugins. Gerrit 3.13 (H2 2025) aims to further optimize push performance, UI usability, and plugin updates, including Kafka and Zookeeper integrations.
The k8s-Gerrit initiative will improve Gerrit’s deployment on Kubernetes, ensuring better scalability and resilience. Looking ahead, Gerrit 4.0 (2026/2027) plans to decouple the review UI from the JGit server, enabling alternative review interfaces and improved flexibility.
The development team is prioritizing significant performance enhancements in JGit, the Java implementation of Git used by Gerrit. Key objectives include:
Speeding Up Conflicting Ref Names on Push: This aims to reduce delays during push operations when ref name conflicts occur.
Enhancing SearchForReuse Latency for Large Monorepos: The goal is to improve latency by at least an order of magnitude, facilitating more efficient operations in extensive monorepositories.
Improving Object Lookup Across Multiple Packfiles: Efforts are underway to accelerate object lookup times by at least tenfold, enhancing performance in repositories with numerous packfiles.
Parallelizing Bitmap Generation: By enabling bitmap generation across multiple cores, the team aims to expedite this process, contributing to overall performance gains.
Gerrit Core Experience Enhancements
A notable feature planned for this release is the support for X.509 signed commits, which will bolster security and authenticity in the code review process.
Owners Plugin Improvements
Enhancements to the Owners Plugin are set to provide clearer insights and streamlined interactions:
Action Requirements Display: Explicitly showing required actions by each owner at the file level.
Detailed Pending Reviews: Offering more comprehensive information on pending reviews by owners.
Easier Contact with File Owners: Facilitating more straightforward communication with file owners.
Analytics Plugin Optimization
The analytics plugin is slated for improvements to enhance speed and usability:
Repo Manifest Discovery: Native support for discovering repository manifests.
Faster Metrics Extraction: Accelerated extraction of metrics for branches, aiding in quicker data analysis.
Gerrit 3.13 (Target: H2 2025)
JGit Performance and Concurrency Enhancements
Building upon previous improvements, version 3.13 aims to further optimize performance:
Optional Connectivity and Collision Checks: Improving push performance by allowing the skipping of certain checks when appropriate.
Customizable Lock-Interval Retries: Providing flexibility in managing lock intervals to enhance concurrency handling.
Read-Only Multi-Pack Index Support: Introducing support for read-only multi-pack indexes to improve repository access efficiency.
Gerrit Core and UI Experience Enhancements
User experience remains a focal point with planned features such as:
File List Filtering: Allowing users to filter the file list in the change review screen for more efficient navigation.
Headless Gerrit Packaging: Offering a version of Gerrit that serves only read/write Git protocols, catering to users seeking a streamlined experience.
Plugin Updates
The roadmap includes updates to key plugins:
Kafka Events-Broker: Upgrading to support Kafka 3.9.0, enhancing event handling capabilities.
Zookeeper Global-Refdb: Updating to support Zookeeper 3.9.3, improving global reference database management.
Replication Plugin Enhancements
Efforts to simplify configuration and improve performance include:
Dynamic Endpoint Management: Introducing APIs for creating and updating replication endpoints dynamically.
UI Integration: Displaying replication status within the user interface for better visibility.
Reduced Latency on Force-Push: Improving replication latency during force-push operations by applying objects with prerequisites.
k8s-Gerrit
The k8s-Gerrit initiative focuses on deploying Gerrit within Kubernetes environments, aiming to enhance scalability, resilience, and ease of management. This approach leverages Kubernetes’ orchestration capabilities to provide automated deployment, scaling, and management of Gerrit instances, facilitating more efficient resource utilization and operational consistency.
Gerrit 4.0 (Target: 2026/2027)
Looking ahead, Gerrit 4.0 is set to introduce significant architectural changes:
Decoupling Gerrit Review UI and JGit Server: This separation will allow the Gerrit UI and JGit server to operate as independent services, providing greater flexibility in deployment and scaling.
Enabling Alternative Review UIs: By decoupling components, the platform will support the integration of other review interfaces, such as pull-request systems, offering users a broader range of tools tailored to their workflows.
The Gerrit community is encouraged to stay engaged with these developments, as the roadmap is subject to change. Contributors planning to work on features not listed are advised to inform the Engineering Steering Committee (ESC) to ensure alignment with the project’s goals.
As 2024 draws to a close, it’s a great time to reflect on the milestones and achievements of the GerritForge team in innovating Git performance with the release of GHS, supporting and advancing the Gerrit Code Review project with 20 releases and over 1.5k commits. This year has been one of exciting developments and initiatives that have made Gerrit stronger, more accessible, and better equipped to meet the needs of modern software teams. Here’s what GerritForge accomplished for the Git and Gerrit Code Review ecosystem in 2024.
2024 in numbers
1,500 changes merged
40 repositories involved in the Gerrit and JGit projects
20 releases
5 conferences, 6 meetups
11 contributors, 4 maintainers
20k man/hours spent in open-source projects
Managing the Releases of Gerrit 3.10 and 3.11
As usual, we continue to ensure the regular releases of new Gerrit versions. This year was no exception with the releases of Gerrit 3.10 and 3.11. These releases introduced new features, performance optimisations, and bug fixes to further solidify Gerrit as the leading code review tool for large-scale projects.
Our team cooperated with the Gerrit Code Review community to ensure these releases were stable, well-documented, and aligned with community needs. From coordinating release schedules to ensuring compatibility with plugins and integrations, GerritForge played a key role in making these versions a reality.
Key Highlights
Gerrit 3.10 brought major improvements in user experience, including refined UI capabilities and enhanced search functionality.
Gerrit 3.11 introduced critical updates to multi-site support, security enhancements, and significant performance boosts.
GerritMeets success in both the USA and Europe
The GerritMeets series has become a cornerstone of community engagement, and 2024 was no exception. GerritForge organised six GerritMeets across several locations, including California, Germany, and the UK, bringing together contributors, users, and maintainers to share knowledge, discuss trends, and explore use cases. Each session covered a diverse range of topics, including:
Best practices for multi-site setups.
Advanced plugin development.
Gerrit performance tuning for large repositories.
Innovations in CI/CD workflows with Gerrit.
These virtual meetups provided a platform for collaboration and learning, reinforcing Gerrit’s community spirit. All the recordings of the 2024 GerritMeets are available as a playlist on the GerritForge TV YouTube channel.
World-class Enterprise Gerrit-as-a-Service on Google Cloud Platform
In 2024, GerritForge expanded Gerrit’s capabilities by adding support for Gerrit-as-a-Service (GaaS) on the Google Cloud Platform (GCP). This initiative makes it easier than ever for organizations to adopt Gerrit without the operational overhead of managing infrastructure.
Benefits of Gerrit-as-a-Service on GCP
Scalability: Leveraging GCP’s powerful infrastructure to scale Gerrit deployments for enterprises of any size.
Simplicity: Reducing setup and maintenance complexity, allowing teams to focus on development and code reviews.
High Availability: Utilizing GCP’s advanced networking and storage capabilities for improved uptime and disaster recovery.
By enabling Gerrit on GCP, GerritForge is broadening the tool’s accessibility, particularly for teams looking for a cloud-native, fully managed solution.
Gerrit User Summit with Qualcomm
This year’s Gerrit User Summit, organized by Qualcomm in collaboration with GerritForge, was a highlight for the community. Held at the Qualcomm HQ in San Diego, CA (USA), the summit offered a chance for Gerrit enthusiasts worldwide to come together in person. The agenda featured:
Keynotes by Gerrit maintainers and industry leaders.
Hands-on hackathon for contributors and users.
Insightful panels on the future of Gerrit.
The collaboration with Qualcomm not only expanded the summit’s reach but also highlighted Gerrit’s growing importance in enterprise environments.
Showcasing GHS and Gerrit Code Review worldwide
This year, GerritForge actively participated in numerous conferences to showcase GHS and expand Gerrit’s visibility, and demonstrate its unique capabilities. These events were a fantastic opportunity to uncover GHS and showcase Gerrit to hundreds of developers who had never encountered it.
At these conferences, we showcased:
GHS: It demonstrates its seamless integration with Git and showcases a whopping 100x performance improvement over a vanilla setup thanks to the power of AI and reinforcement learning.
K8s-Gerrit: Highlighting how Gerrit deployed on Kubernetes provides unparalleled flexibility, performance, and multi-site support.
Through live demos, presentations, and Q&A sessions, we highlighted GHS and Gerrit’s ability to scale, its unique review model, and its role in making software delivery pipelines up to 100x times faster.
K8s-Gerrit Hackathon with SAP
Collaboration was at the forefront of the k8s-Gerrit Hackathon, co-hosted by GerritForge and SAP. The hackathon brought together developers from both SAP and GerritForge teams to tackle the challenges of Kubernetes-based Gerrit deployments and multi-site support.
Outcomes of the Hackathon
Enhanced scalability for k8s-Gerrit deployments.
Breakthroughs in multi-site replication and disaster recovery.
Valuable contributions to the Gerrit codebase and documentation.
The event exemplified the power of open collaboration, pushing Gerrit further into cloud-native development.
Looking Ahead to 2025
As we celebrate the progress made in 2024, we remain focused on the road ahead. GerritForge is committed to:
Public offering of GHS
Gerrit-as-a-Service in Google Cloud
Gerrit Code Review v3.12 and v3.13
More GerritMeets and Gerrit User Summit events
Our gratitude goes out to the Git and Gerrit Code Review communities, contributors, and partners who have made this year a success. Together, we’re building a tool that empowers teams to deliver high-quality code faster and more efficiently. Here’s to an even more impactful 2025!
We’re thrilled to announce that our team will be speaking about our advancements with GerritForge AI Health Service (GHS) at several prestigious conferences in the coming months. These events provide an incredible opportunity to share our innovative AI solutions with a broader audience, engage with industry experts, and showcase how GHS is revolutionizing the way organizations maintain the health and stability of their Gerrit and Git systems.
Our journey begins at the Linux Open Source Summit in Vienna, from the 16th to the 18th of September. This summit is a cornerstone event for the open-source community, and we couldn’t be more excited to discuss how GHS leverages AI to ensure the seamless performance of Git and Gerrit systems, even in the most demanding environments.
Next, we’ll be in Berlin for Git Merge on the 19th and 20th of September. Git Merge is the go-to event for Git enthusiasts and professionals alike, and we’re eager to dive deep into the technical aspects of GHS, sharing insights on how our AI solution optimizes system performance, reduces downtime, and empowers development teams to focus on what they do best—creating great software.
In October, we’re particularly excited about the Gerrit User Summit in San Diego, on the 10th and 11th. This event is especially important to us as it brings together the Gerrit community to discuss the latest developments and best practices. We’ll be showcasing how GHS is enhancing Gerrit environments by providing intelligent and automated health monitoring and ensuring peak performance.
Following that, we’ll speak at the OCX conference in Mainz, from the 22nd to the 24th of October. OCX is known for bringing together top minds in DevOps and open-source technology, making it the perfect venue to highlight how GHS is transforming the management of code review and source control systems with intelligent, automated health monitoring and remediation.
Finally, we’re thrilled to wrap up our conference tour at KubeCon in Salt Lake City, from the 12th to the 15th of November. As one of the most anticipated events in the cloud-native ecosystem, KubeCon offers an unparalleled platform to demonstrate how GHS integrates with Kubernetes environments, ensuring that your SCM systems are always running at peak performance.
These conferences represent more than just speaking engagements for us—they are an opportunity to engage with the community, learn from our peers, and continue pushing the boundaries of what’s possible with AI in software development. We can’t wait to connect with you at these events and share how GHS can make a tangible difference in your organization’s success.
Stay tuned for more updates as we approach these dates, and be sure to catch our sessions if you’re attending any of these events!
Daniele Sassoli GerritForge Engineering Manager Gerrit Code Review Community Manager and Contributor
GerritForge has confirmed over 2023 its commitment to the Gerrit Code Review platforming, helping deliver two major releases: Gerrit v3.8 and v3.9.
The major contributions combined are focused on the plugins for extending the reach of the Gerrit platform, first and foremost the pull-replication and multi-site, as shown by the split of the 853 contributions across the projects, weighted by the number of changes and average modifications per change.
Pull replication plugin This is where GerritForge excelled in providing an unprecedented level of performance over anything that has been built so far in terms of Git replication for Gerrit. Roughly one-third of the Team efforts have contributed to the pull replication plugin, which provided over 2022/23 a 1000x speedup factor compared to Gerrit tradition factor. GerritForge has further improved its stability, resilience and self-healing capabilities thanks to a fully distributed and pluggable message broker system.
Gerrit v3.8 and v3.9 GerritForge helped release two major versions of Gerrit Code Review, contributing noteworthy features like Java 17 support, cross-plugin communication, importing of projects across instances and the migration to Bazel 7.
Owners plugin Jacek has completely revamped the engine of the owners plugin, boosting it with an unprecedented level of performance, hundreds of times faster than in the previous release, and bringing it to the modernity of submit requirements without the need to write any Prolog rules.
Multi-site plugin The whole team helped provide more stability and bug fixes across multiple versions of Gerrit, from v3.4 up to the latest v3.9.
JGit GerritForge kept its promises in stepping up its efforts in getting important fixes merged, including the optimisation of the refs scanning in Git Protocol v2 and the fix for bitmap processing with incoming Git receive-pack concurrency that we promised to fix at the beginning of 2023.
Migration of Eclipse JGit/EGit to GerritHub.io
The 2023 has also seen a major improvement in GerritHub stability and availability, halving the total outage in a 12-month period from 19 to 10 minutes, with a total uptime of 99.998% (source: PIngdom.com)
The whole process was completed without any downtime and a reduced read-only window on the legacy Eclipse’s instance git.eclipse.org, which was needed because of the lack of multi-site support on the Eclipse side.
What we did achieve from our goals of 2023
JGit changes: we did merge 22 changes in 2023, most of them within the list of our targets for the year. One related to the packed-refs loading optimisation was abandoned (doesn’t get much traction from the rest of the community), and the last major one left is the priority queue refactoring still in progress on stable-6.6. Also, thanks to the migration of JGit/EGit to GerritHub.io, David Ostrovsky managed to get hold of its committer status and will now be able to provide more help in support in getting changes reviewed and merged.
JGit multi-pack index support: we did not have the bandwidth and focus to tackle this major improvement. The task is still open for anyone willing to help implement it.
Git repository optimiser: we kick-started the activity and researched the topic, with Ponch presenting the current status at the Gerrit User Summit 2023 in Sunnyvale CA.
Gerrit v3.8 and project-specific change numbers: the design document has been abandoned because of the need of rethinking its end-to-end user goals. However, we found and fixed many use cases where Gerrit wasn’t using the project/change-number pair for identifying changes, which is a pre-requisite for implementing any future project-specific change number use-case.
Gerrit Certified Binaries: the Platinum Enterprise Support for Gerrit has been enriched in 2023 with the certified binaries programme, with enhanced Gatling tests and E2E validation using AWS-Gerrit. Many bugs have been found and fixed in all the active versions of Gerrit; some of them were very critical and surprisingly undiscovered for months.
GerritForge Inc. revenue targets in the USA: the revenues increased by 50% in 2023, which was slightly below the initial expectations but still remarkable, despite the latest economic downturn of the past 12 months. 100% of the business has been transferred to the USA, including the GerritForge trademark and logo and we are now ready to start a new robust growth cycle in 2024 and beyond.
Looking at the future with AI in 2024
The recent economic news in the past 6 months has highlighted a difficult moment after the COVID-19 pandemic: the conjunction of the cost of living crisis, rising interest rates and two new major wars across the globe have pushed major tech companies to revise their small to medium-term growth figures, resulting in a series of waves of lay offs in the tech sector and beyond.
Whilst the layoffs are not immediately related to a lack of profitability of the companies involved, it highlights that in the medium term there will be a lot fewer engineers looking after the production systems across the company, including SCM.
SCM and Code Review are at the heart of the software lifecycle of tech companies and, therefore, represent the most critical part of the business that would need to be protected at all costs. GerritForge sees this change as a pivotal moment for stepping up its efforts in serving the community and helping companies to thrive with Gerrit and its Git SCM projects.
How do we maintain SCM stability with fewer people?
Gerrit Code Review has become more and more stable and reliable over the years, which should sound reassuring for all of those companies that are looking at a reduced staff and the challenge of keeping the lights on of the SCM. However, the major cause of disruption is represented by what is not linked to the SCM code but rather its data.
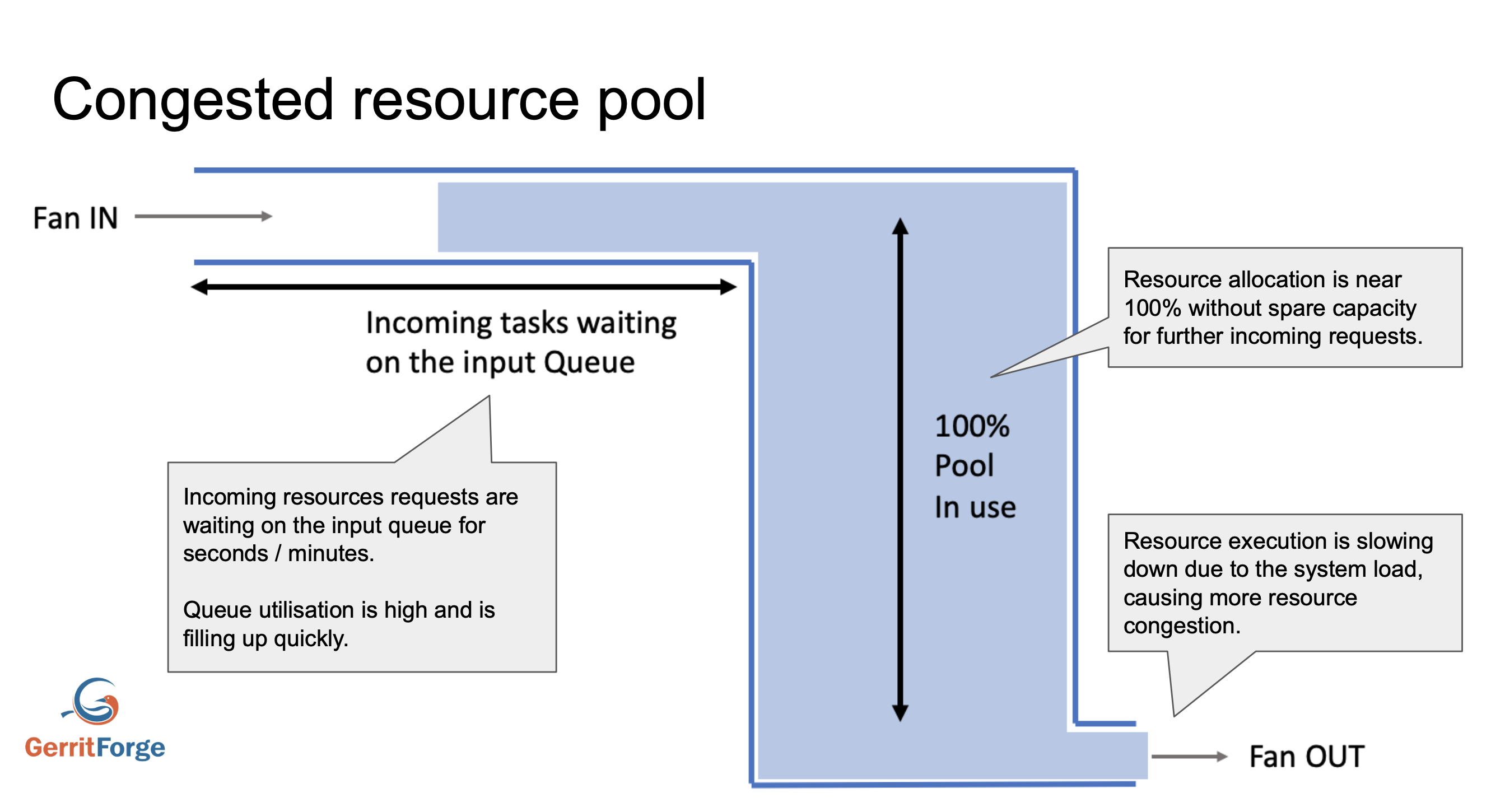
The Git repositories and their status are nowadays responsible for 80% of the stability issues with Gerrit and possibly with other Git servers as well. Imagine a system that is receiving a high rate of Git traffic (e.g. Git clone) of 100 operations per minute, and the system is able to cope thanks to a very optimised repository and bitmaps. However, things may change quickly and some of the user actions (e.g. a user performing a force-push on a feature branch) could invalidate the effectiveness of the Git bitmap and the server will start accumulating a backlog of traffic.
In a fully staffed team of SCM administrators and with all the necessary metrics and alerts in place, the above condition would trigger a specific alert that can be noticed, analysed, and actioned swiftly before anyone notices any service degradation.
However, when there is a shortage of Git SCM admins, the number of metrics and alerts to keep under control could be overwhelming, and the trade-offs could leave the system congestion classified as a lower-priority problem.
When a system congestion lasts too long, the incoming tasks queueing could reach its limits, and the users may start noticing issues. If the resource pools are too congested, the system could also start a catastrophic failure loop where the workload further reduces the fan out of the execution pool and causing soon a global outage.
The above condition is only one example of what could happen to a Git SCM system, but not the only one. There are many variables to take into account for preventing a system from failing; the knowledge and experience of managing them is embedded in the many of the engineers that are potentially laid off, with the potential of serious consequences for the tech companies.
GerritForge brings AI to the rescue of Git SCM stability
GerritForge has been active in the past 14 years in making the Git SCM system more suitable for enterprises from its very first inception: that’s the reason why this blog is named “GitEnterprise” after all.
We have been investing over 2022 and 2023 in analysing, gathering and exporting all the metrics of the Git repositories to the eyes and minds of the SCM administrators, thanks to open-source products like Git repo-metrics plugin. However, the recent economic downturn could leave all the knowledge and value of this data into a black hole if left in its current form.
When the work of analysing, monitoring and taking action on the data becomes too overwhelming for the size of the SCM Team left after the layoffs, there are other AI-based tools that can come to the rescue. However, none of them is available “out of the box” and their setup, maintenance and operation could also become an impediment.
GerritForge has a historic know-how on knowledge-based systems and has been lecturing the community about data collection and analysis for many years in the Gerrit Code Review community, for example the Gerrit DevOps Analytics initiative back in 2017. It is now the right time to push on these technologies and package them in a form that could be directly usable for all those companies who need it now.
Introducing GHS – GerritForge-AI Health Service
As part of our 2024 goals, GerritForge will release a brand-new service called GHS, directly addressing the needs of all companies that need to have a fully automated intelligent system for collecting, analysing and acting on the Git repository metrics.
The high-level description of the service has already been anticipated at the Gerrit User Summit 2023 in Sunnyvale by Ponch and the first release of the product is due in Q1 of 2024.
How does GHS work?
GHS is a multi-stage system composed of four basic processes:
Collect the metrics of your Gerrit or other Git repositories automatically and publish them on your registry of choice (e.g. Prometheus)
Combine the repository metrics with the other metrics of the system, including the CPU, memory and system load, automatically.
Detect dangerous situations where the repository or the system is starting to struggle and suggest a series of remediation policies, using the knowledge base and experience of GerritForge’s Team encoded as part of the AI engine.
Define a direct remediation plan with suggested priorities and, if requested, act on them automatically, assessing the results.
Stage 4, the automatic execution of the suggested remediation, can be also performed in cooperation with the SCM Administrators’ Team as it may need to go through the company procedures for its execution, such as change-management process or communication with the business.
However, if needed, point 4. can also be fully automated to allow GHS to act in case the SCM admins do not provide negative feedback on the proposed actions.
What the benefits of GHS for the SCM Team?
GHS is the natural evolution of GerritForge’s services, which have historically been proactive in the analysis of the Git SCM data and the proposal of an action plan. The GerritForge’s Health Check is a service that we have been successfully providing for years to our customers; the GerritForge Health Service is the completion of the End-to-End stability that the SCM Team needs now more than ever, to survive with a reduced workforce.
To the SCM Administrator, GHS provides the metrics, analysis and tailored recommendations in real-time.
To the Head of SCM and Release Management Team, GHS gives the peace of mind of keeping the system stable with a reduced workforce.
To the SCM users and developers, GHS provides a stable and responsive system throughout the day, without slowdowns or outages
To the Head of IT, GHS allows to satisfy the company’s needs of costs and head count reduction without sacrificing the overall productivity of the Teams involved.
GerritForge’s pledges to Gerrit Code Review quality and Open-Source
GerritForge has provided Enterprise Support and free contributions to Gerrit Code Review for 14 years, pretty much since the beginning of the project. We pledged in the past to be always 100% Open-Source and do commit to our promises.
For 2024, GerritForge will focus on delivering its promising Open-Source contributions to the stability and reliability of Gerrit Code Review, with:
Support for the Gerrit Code Review platform releases, Gerrit v3.10 and v3.11
Free support and development of the Gerrit CI validation process, in collaboration with all the other Gerrit Code Review contributors and maintainers
Free Open-Source fixes for all critical problems raised by any of its Enterprise Support Customers, available to everyone in the Gerrit Code Review community
Free Open-Source code base for the main four components of the new GHS product, following the Open-Core methodology for developing the service.
With regards to the initiatives that we started in the past few years, including pull-replication and multi-site, we believe they have reached a maturity level that would not need further major refactoring and extensions in 2024. We will continue to support and improve them over the years, based on the feedback and support requests coming from the Enterprise Support Customers and the wider Gerrit Open-Source community.
GHS AI engine and dogfooding on GerritHub.io.
GHS will have a rule-based AI system that will drive all the main decisions on the selection and prioritisation of the corrective actions on the system. As with all AI systems, the engine will need to start with a baseline knowledge and intelligence and evolve based on the experience made on real-life systems.
GerritForge’s commitment to quality is based on the base principle of dogfooding, where we use the system we develop every single day and learn from it. The paradigm is on the basis of our 14 years of success and we are committed to using it also for the development of GHS.
GerritForge has been hosting GerritHub.io since 2013, and tens of thousands of people and hundreds of companies are using it for their private and Open-Source projects every single day. The system is fully self-serviced; however, still relies on manual maintenance from our Gerrit and Git SCM admins.
We are committed to starting using GHS on GerritHub.io from day 1 and use the metrics and learning of the systems to improve its AI rule engine continuously. All customers of GerritForge’s GHS service will therefore benefit from historic knowledge and experience induced by the the learnings and optimisations made on GerritHub.io for the months and years to come.
GHS = Git SCM admins humans and AI-robots working together
GHS will revolutionise the way Git SCM admins are managing the system today: they will not be alone anymore, juggling a series of tools to understand what’s going on, but they will have an intelligent and expert robot at their service, driven by the wisdom and continuous learnings made by GerritForge, at their service every single day.
We expect a different future way of working in front of us: we are embracing this radical change in how people and companies work and making GHS serve them effectively and in line with our Open-Source pledges.
The future is bright with GerritForge-AI Health Service, Git and Gerrit Code Review at your service !
Luca Milanesio GerritForge CEO Gerrit Code Review Release Manager and member of the Engineering Steering Committee
GerritHub has experienced unprecedented growth over the past two years. The November 2015 numbers presented at the Google User Summit in Mountain View – CA have been surpassed again, and we do need to make sure that our infrastructure is still capable of dealing with current and future users’ needs.
What is changing in GerritHub.io?
We are changing everything, from the version of Gerrit to the hardware, network and storage infrastructure. Data, DBMS, Indexes and cache, need to be upgraded and refreshed to make sure that the new systems are reflecting exacting the current production data and sessions. We are changing as well the geo-location of our servers, from the current server farm in Germany (Bayern, Nuremberg – 100 MBps) to a new server farm in Canada (Quebec, Beauharnois – 1 GBps).
Why have so many changes?
We started to measure some significant delay in the Git and review operations on the old infrastructure, mainly due to three factors:
More users, more repositories, more concurrency. Individuals, OpenSource projects and Businesses started using GerritHub.io for their mission-critical repositories, considering Gerrit the “source of truth” of their review workflow. We needed more horsepower, memory, storage and ability to scale even further.
Bandwidth from USA and Far-east. The majority of people using GerritHub.io are from the other side of the Atlantic Ocean: this is typically not a problem from 7 AM to 3 PM … but after 4 PM the connectivity between Europe and the Americas becomes slow. Additionally, people using GerritHub.io from India, Japan, Australia and New Zealand experienced terrible slowdowns because of the excessive number of hops to reach Germany.
Gerrit master is much faster. Based on the current data and metrics measured on GerritHub.io, we have contributed a lot of patches to reduce the overhead caused by Gerrit DB and lessen the number of SQL queries per minute. All those new improvements are on Gerrit master, and we need to catch-up with the “latest and greatest” version.
Will I experience any GerritHub.io outage?
Last time that GitHub needed to make a major upgrade, asked his 5M users to stop working for 23 minutes,. This translates to a loss of two millions of hours of continuous delivery lifecycle, equivalent to over 130 man/years, worth no less than eight millions dollars.
We are going to adopt a new Zero-Downtime Gerrit roll-out strategy to make sure that all those changes are not going to impact your day-by-day activity. If you were not reading this post you would possibly even not notice the “switch” from the old to the new infrastructure, apart from the increase in speed and bandwidth.
Zero-downtime GerritHub.io migration, step by step with the associated expected timings.
Phase 0 – Replication to the new Gerrit infrastructure. (- 1 month ago)
We started migrating everything one month ago, and the old and new infrastructure are working side-by-side, thanks to Gerrit master-slave replication. The new Gerrit servers are active as slaves and are read-only.
Phase 1 – Migration kick-off. (08:00 GMT)
We install a Gerrit plugin that rejects all the push to GerritHub.io repositories providing a courtesy message: “Gerrit is under maintenance, all projects are READ ONLY”. All the HTTP POST, PUT and DELETE are disable on the Gerrit REST-API.
Phase 2 – Wait for replication events to complete and migrate DB. (08:02 GMT)
Git repositories are continuously replicated, but we do need to make sure that the event queue is empty. Once that happens we schedule the last final DB migration to the new infrastructure.
Phase 3 – Gerrit DB upgrade and reindex (08:04 GMT)
New Gerrit server executes the final upgrade and off-line reindex of the latest received changes.
Phase 4 – Gerrit start-up and cache warm-up (08:05 GMT)
New Gerrit is restarted and the most critical Gerrit caches (projects, accounts and groups) are pre-loaded in memory. This allows the incoming traffic spike to avoid the collapse of used threads and makes the transition as smooth as possible without slowdowns.
Phase 5 – Traffic switch and DNS updates (08:06 GMT)
GerritHub.io redirects all incoming HTTPS and SSH traffic to the new infrastructure. Git pushes and HTTP PUT, POST and DELETE operations of the REST API are operational again and served by the new Gerrit infrastructure. GerritHub.io DNS is updated to the new Canadian IPs.
Phase 6 – New IPs gets propagate to all worldwide DNSs (+ 1 day)
Once all the DNSs in the world would have been updated, everyone will start going directly to the new infrastructure without further hops or redirection from Germany. Customers from USA, Canada, South America, Asia, Japan, New Zealand and Australia should see a significant reduction of the network latency and increase of GerritHub.io responsiveness.
Firewall and SSH considerations
Even if Gerrit server’s SSH key is not changing, some of you may see a warning similar to this when they push or pull over SSH:
Warning: the RSA host key for ‘review.gerrithub.io’ differs from the key for the IP address ‘148.251.77.70’
The warning message will also tell you which lines in your ~/.ssh/known_hosts need to change. Open that file in your favorite editor, remove or comment out those lines, then retry your push or pull.
Should your network have some strict firewall rules to access external sites, you may want to whitelist the IP of the new infrastructure WLB to: 192.99.233.76.
Follow GerritHub.io migration progress.
We will advertise the migration progress on Twitter at @GitEnterprise. Should you have any issue you can tweet us or contact GerritForge Customer Support at support@gerritforge.com.
Nowadays people are very careful about privacy and user data: nobody grants access to their profile without checking first the possible consequences.
We want to give the user the ability always to know and control what level of access is given to their data: that’s why we improved the way you login in GerritHub.io.
GitHub scopes: what is it?
GitHub provides the authentication and access to user’s profile using a protocol called OAuth 2.0. When GerritHub is requesting a user to authenticate is then granted a set of permissions to operate on behalf of the user on their GitHub resources, which include:
User’s personal data (name, e-mails)
User’s membership to organisations and teams
User’s repositories
The set of permissions to access and operate on your data is also known as “Scope” in GitHub terms.
Displaying your current scope and associated rights GerritHub has on your GitHub profile
Giving you the ability to switch to a different “Scope” and consequently the rights that GerritHub has on your profile data
Transparency is good, but what is the practical added value?
There has been in the past a common complaint about GerritHub having too much or too little access to your GitHub profile:
Too much? Why GerritHub.io needs access to my e-mail address? Why does GerritHub need to see my public keys?
Too little? Why does GerritHub not show my private repositories in the import screen? How can I see my organisation membership in GerritHub project security screen?
With the ability now to visualise and change the current “Scope”, people can be more aware of why things are not showing up. They can make conscious decisions about how to change them with full transparency on the associated implications.
A common scenario: importing and accessing private GitHub Organisations, Teams and Repositories.
When you need to import an existing private GitHub project, you need to access information that is not publicly available:
Your membership to a private organisation
Your ownership of a Team structure
Ability to clone and push your private organisations’ repositories
There is now a special information box suggesting that you have the ability to change your “Scope” if you don’t see the organisations and repositories you want to import.
After changing the scope, you can then log in again and you will have an improved set of options to get more data and repositories from your GitHub account.
Like it? Will you use it on a daily basis?
We are eager to get your feedback on this new feature: Tell us what you think and let us know what you would change or add to the set of “Scope” permissions.
GitHub has recently changed his API default permissions and has caused big problems and outages to Jenkins or Gerrit instance configured for with OAuth 2.0 authentication.
GerritHub.io unfortunately has been impacted and this has caused two outages today:
0:40 – 1:10 CEST (GitHub API error temporary overload – automatically resolved)
10:50 – 11:25 CEST (GitHub API error overload causing the slowdown of HTTP calls and subsequent exhaust of our DBMS connection pooling)
The second outage was more serious as the GitHub API problems happened exactly at peak hours for European customers.
What is the current situation?
We have added the extra “read:org” Scope permissions to the default public access to GerritHub.io in order to prevent the GitHub API from failing. This change requires you to logout and login back to GerritHub.io to approve the extra permission flag.
IMPORTANT NOTE: Previous authenticated sessions are not valid anymore (batch users for Jenkins Jobs) for reading your GitHub organisation ownership and, as a consequence, your Gerrit permissions cannot be fully evaluated. You need to login on behalf of the batch users to GerritHub.io and accept the new GitHub permissions in order to get the new valid OAuth token.
The system is back up-and-running but is slower than usual, due to the extra throttling applied by GitHub cause by the error overload. As people will start logging in again and approving the new permissions, the error rate should drop and the situation will come back to normal.
What if I still have problems after having logged in and approved the read:org permissions?
We have been monitoring the situation during the day but the performance of the system was not recovering as quickly as we wanted. The problem was related to the batch users that were still running in background using OAuth tokens not authorised anymore to perform their actions.
One user from RedHat pointed out:
“You can see it triggered job and the Build results is SUCCESS. But there is no votes or verified status.”
This was caused by the batch user (configured in this case on Jenkins) was still authenticated through its old OAuth token but not authorised anymore to provide the “Verified” status. Batch users are typically not using the GUI and so have not a lot of chances of getting a renewed OAuth token with the correct permissions.
Current situation: workaround in place.
The OAuth Scope problem was only impacting those users associated to a public GitHub plan and thus using the default scopes user:email + public:repo. All the other users associated to a private GitHub plan had already granted access to all private information, including the full list of their public and private organisations.
The workaround in place uses the weakest link of the chain applied to the GitHub’s protection of the user’s organisations memberships:
A logged in with scopes [user:email + public:repo] cannot access its own list of organisations (strongest link).
The same user can however open a web browser and navigate, even without being authenticated, the URL https://github.com/username and extract the list of organisations on the bottom-left of the page under the H3 tag “Organizations” (weakest link)
The latest patch applied later today just apply this principle using the weakest link (page-scraping with anonymous HTTP-GET) as compensation of the failure to overcome the strongest link.
NOTE: The workaround allows to fill-up the Gerrit cache and gradually eliminates the GitHub throttling on the failed API calls. It allows the service to come back much more quickly to the expected normal response times. You are better anyway to authenticate to GerritHub.io interactively in order to get a renewed OAuth token as hopefully the workaround won’t be necessary anymore in the next few days.