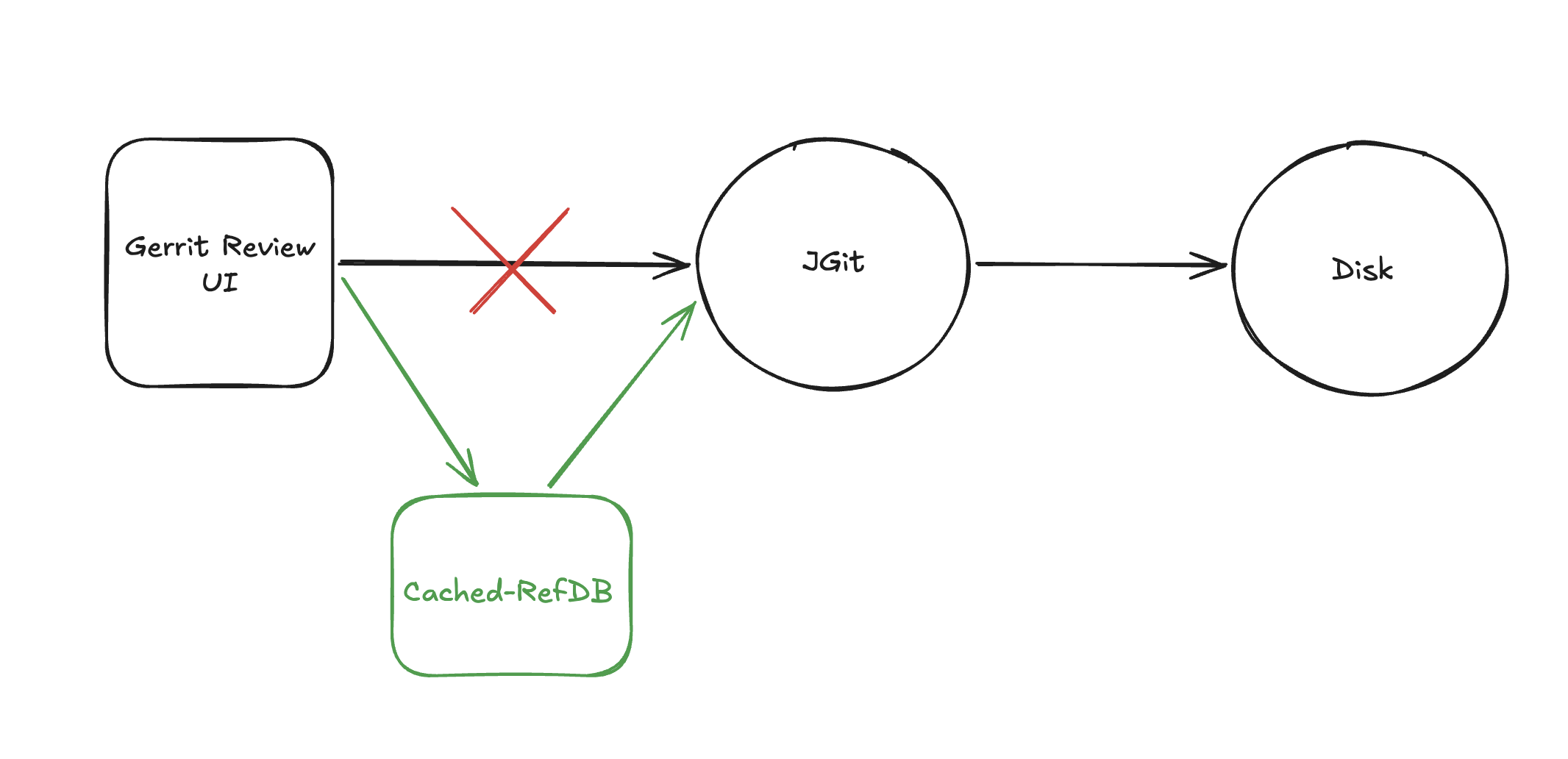
TL;DR
AI-assisted coding and automated agentic development pipelines are overwhelming Git repositories. Rapid packfile accumulation breaks traditional maintenance, causing severe bottlenecks in Git’s “Counting” and “Search-for-Reuse” (SFR) phases. Fast pushes suddenly become agonizing delays.
Our 12-hour stress tests proved that standard solutions fail under scale. Doing nothing leads to server collapse. Scheduled Garbage Collection (GC) is just a band-aid, creating unstable performance until the system finally chokes under heavy traffic.
The solution is adaptive intelligence. Git-at-High-Speed (GHS) uses reinforcement learning to trigger lightweight, proactive repository adjustments. GHS keeps system load flat, drops latencies under 50ms, and entirely eliminates massive GC disruptions.
Introduction
Modern software organisations are rapidly embracing AI-generated code and content, dramatically increasing the volume and velocity of changes flowing into their repositories. As this wave of automated contributions accelerates, version control systems such as Gerrit must sustain ever-increasing data ingestion without degrading developers’ experience or the reliability of CI/CD pipelines. Maintaining high throughput and low latency under continuous, AI-amplified load is no longer optional; it is foundational to engineering productivity and operational stability. As repositories grow and CI/CD activity intensifies, the cost of managing pack files inside Git becomes critical.
Every push or fetch triggers internal Git phases that prepare the objects to send to the client. First, Git performs a Counting phase, where it walks the repository graph to determine which objects need to be included in the pack being generated. It then scans existing pack files to determine whether objects can be reused, a step known as search-for-reuse (SFR). These stages can become bottlenecks when too many pack files accumulate, resulting in slower pushes, fetches, and clones, and higher CPU load.
To understand how different maintenance strategies affect Counting, SFR, and overall system stability, we conducted stress tests that mimic a realistic enterprise workload. Each simulation ran for 12 hours with 70 concurrent users, blending Git read/write operations with REST API calls. We compared three scenarios:
- Baseline (no garbage collection) – no attempt is made to repack or compact the repository during the test.
- Rule‑based GC (current industry standard) – full garbage collection is scheduled periodically (every 15 minutes) regardless of current load.
- GHS (Git‑at‑High‑Speed) – an adaptive agent monitors repository state and chooses between several actions (create bitmaps, repack references, pruning, do nothing, etc) based on reinforcement‑learning rewards.
The core focus of this analysis is how each strategy influences the Counting and search‑for‑reuse metrics over the full 12‑hour window.
Why Counting Time Matters
Before pack generation begins, Git performs a counting phase to determine which objects must be included in the pack sent to the client. During this step, Git walks the commit graph and object references to build the list of objects that need to be transferred. If the repository contains many changes, branches, and references, this traversal can become expensive and increase the time required to prepare the pack. We measure this latency as the counting time. High counting times indicate that Git is spending significant effort discovering the objects to send, which delays the entire operation. Conversely, low counting times indicate that the repository structure allows Git to identify the required objects quickly.
Why Search‑for‑Reuse Matters
When a Git server receives a push or serves a fetch, it may need to create a pack file. Git attempts to reuse objects that are already stored to avoid duplicating data. It does so by scanning the indices of existing pack files. If there are many small pack files, the scan can touch thousands of index entries, dramatically increasing latency. We measure this latency as the search‑for‑reuse time. High SFR times indicate that Git spends too much time searching for existing objects, thereby bottlenecking the entire operation. Conversely, low SFR times indicate the repository’s internal structure is healthy and that operations can proceed quickly.
Workload Model
To evaluate Gerrit under realistic conditions, we modelled three concurrent workloads using Gatling: developer activity, CI/CD clone jobs, and CI/CD fetch operations. Each workload runs with 70 concurrent virtual users, resulting in 210 active clients interacting with Gerrit simultaneously throughout the simulation.
All workloads run continuously for 12 hours while maintaining a constant number of concurrent users. This creates sustained system pressure and avoids the unrealistic burst patterns often seen in short benchmarks.
Developer Simulation
The developer simulation models the typical workflow of engineers interacting with Gerrit. Virtual users continuously perform common code-review activities such as creating changes, uploading new patch sets, rebasing work, reviewing code and submitting approved changes. These operations generate a steady stream of Git pushes and server-side processing, closely resembling the activity of a busy development team.
CI/CD Clone Simulation
The CI/CD clone simulation represents build systems that regularly clone repositories to run builds and tests. Each virtual pipeline repeatedly performs repository clones followed by verification steps. Because clones require Gerrit to generate pack files and search for reusable objects, they place a significant load on the repository storage layer.
CI/CD Fetch Simulation
The CI/CD fetch simulation models pipelines that periodically fetch updates from the main branch to detect new changes. These incremental updates are lighter than full clones but still exercise Gerrit’s pack generation and object lookup mechanisms, contributing to the overall system load.
Controlling Operation Distribution
To keep the workload realistic, each action includes a configurable pause with a small amount of variation. This prevents request bursts and allows the simulations to control the relative frequency of operations such as pushes, submissions and repository fetches, producing a steady and predictable workload over the entire test duration.
Baseline: Unsustainable Growth Without Maintenance
The baseline scenario intentionally performs no maintenance on the repository. Early in each run, the system is in a relatively healthy state: push traffic is stable, CPU load is moderate, SFR and Counting latencies rise steadily and predictably. As the Gatling simulation continues, however, the number of pack files grows unchecked, and the overall system load, driven by the combined cost of counting objects and searching for reuse, begins to climb.
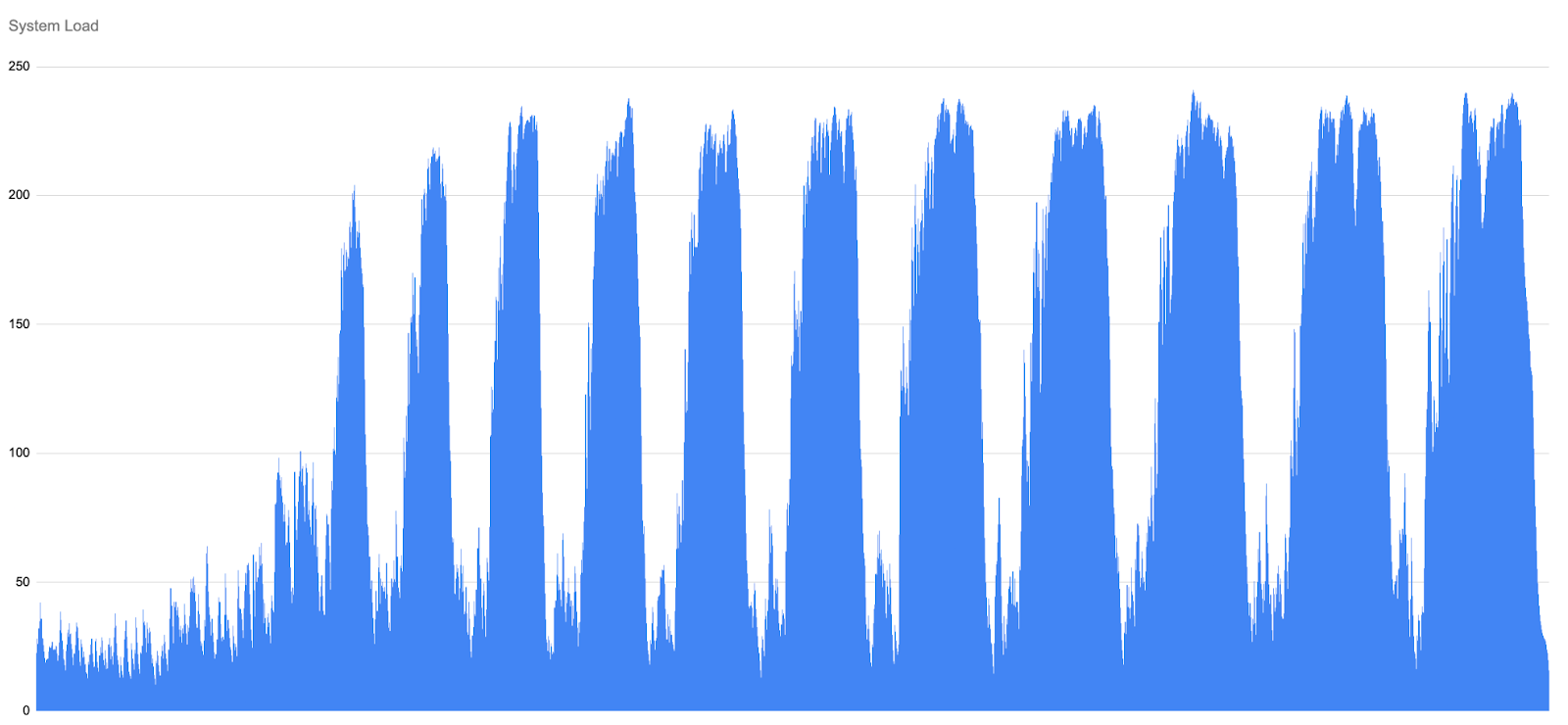
Only once the load crosses a certain threshold does Gerrit begin rejecting HTTP requests. Interestingly, this rising load appears before any HTTP rejections occur. These rejections act as a form of back-pressure: with a fixed pool of HTTP threads, Gerrit limits the number of incoming requests in order to protect the server from complete overload.
This behaviour is clearly visible in the following Counting and SFR graph. As the load builds up, the curve becomes steeper and more unstable. Distinct “waves” start to appear in the data.
Each wave represents a cycle of overload and partial recovery. When the system becomes saturated, Gerrit rejects more requests (shown as red crosses in the graphs). This temporarily reduces the amount of new work entering the system, allowing some ongoing operations to complete and causing Counting and SFR latencies to drop slightly. However, as soon as some headroom becomes available, new requests are accepted again, contention builds up, and latencies begin climbing once more.
The important detail is that each recovery is only partial. The next Counting an SFR peak is higher than the previous one. Over time, the system enters a repeating pattern of build-up, throttling, and renewed overload rather than returning to a stable state.
By the middle of the simulation, Counting and SFR peaks reach hundreds or even thousands of seconds, and latency never returns to the low levels seen at the start of the run.
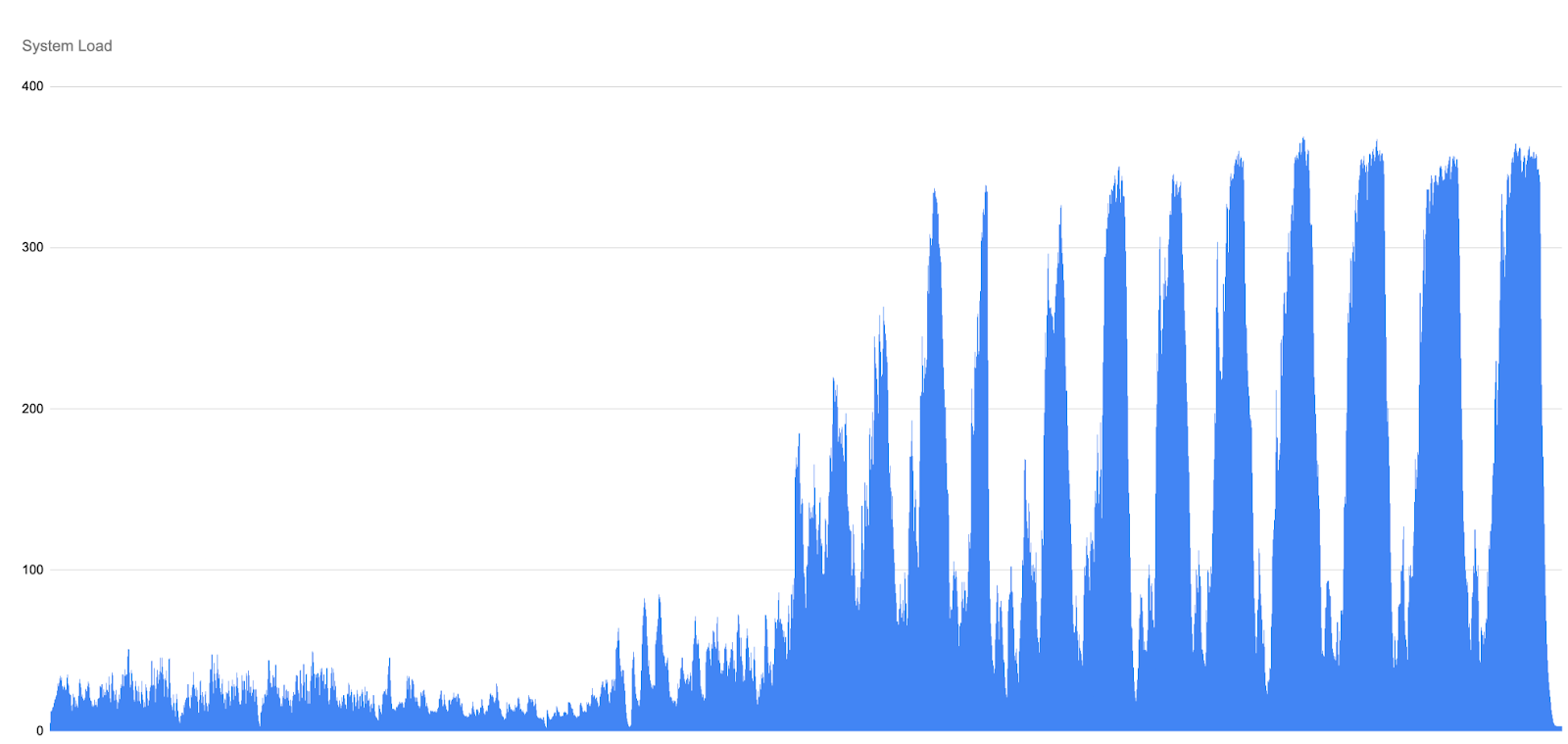
Without any intervention, the baseline runs invariably end, with the system saturated: pushes and fetches stall, HTTP rejections become constant, and SFR and Counting both continue to grow. The ever‑increasing peaks in the above graph illustrate how an unmanaged repository accumulates pack files until normal operations are no longer feasible.
Key observations:
- Trend: The run begins with slow growth, enters a phase of rising oscillations as load builds and then ends in runaway SFR and Counting growth.
- Cycles of overload and throttling: SFR and Counting rise in waves, driven by the server alternating between taking on work and aggressively throttling to survive.
- Implications for users: Rising SFR and Counting times directly translate into slower pushes and fetches. Developers and CI jobs see spiky latencies that grow from seconds to minutes, and eventually operations time out completely as Gerrit exhausts its HTTP thread pool.
Rule‑Based GC: Periodic Relief, Growing Spikes
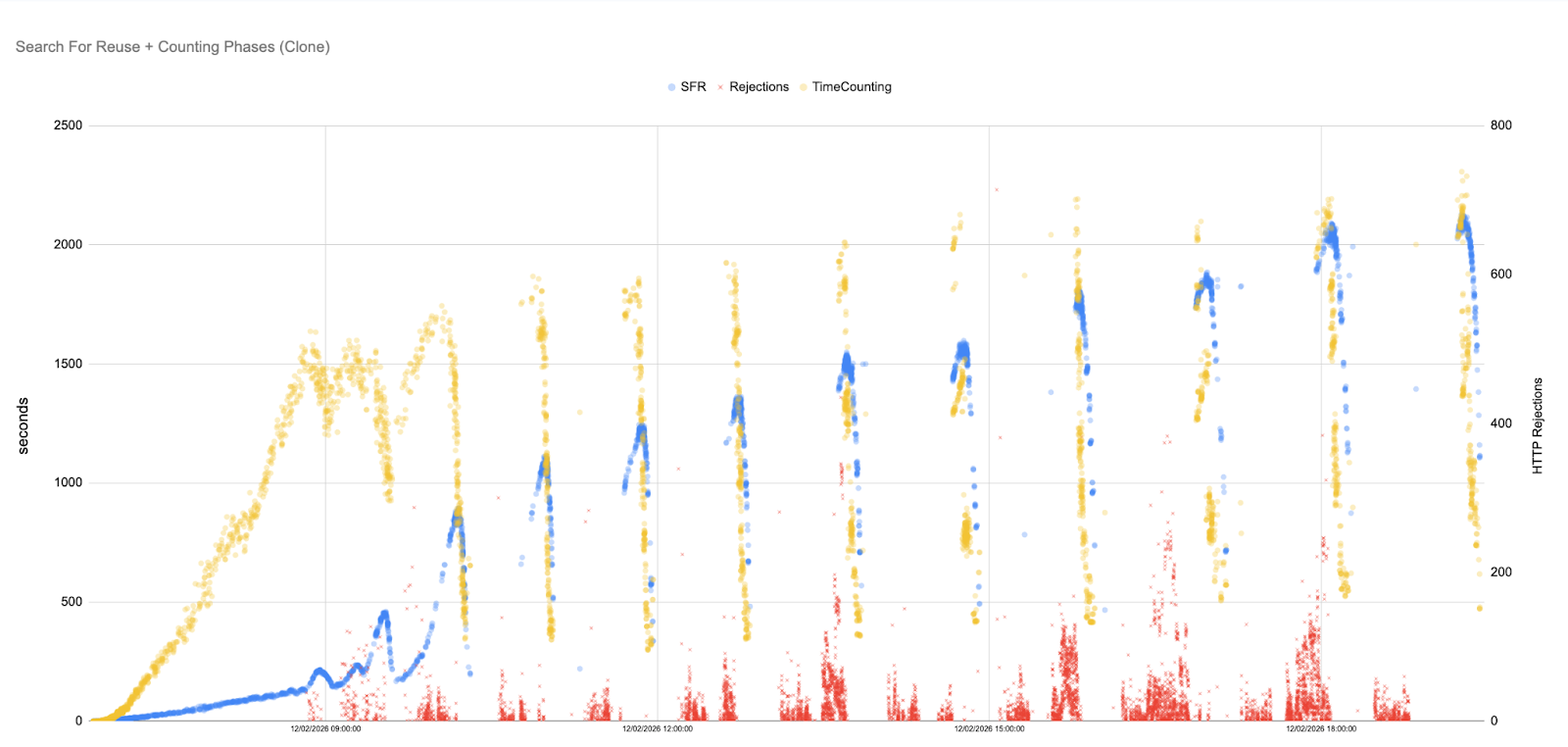
To mitigate uncontrolled pack growth, the rule-based scenario performs a full garbage collection every 15 minutes. This approach reflects the most common maintenance strategy used in Git environments. Each GC run repacks objects and temporarily reduces the number of pack files. This produces a saw‑tooth pattern: immediately after a GC run, SFR and Counting times fall dramatically, but as users continue pushing and fetching, new pack files accumulate, and times rise again until the next GC triggers.
The scatter plot for the rule-based runs shows initial latencies of only a few seconds, but as the simulation progresses, they climb into the hundreds of seconds, with later peaks reaching well over a thousand seconds. Each subsequent GC run yields diminishing returns because the maintenance cost grows: from seconds to minutes, and later ones well over an hour. As a result, the time between the end of one GC and the start of the next gradually shrinks, and the system spends an increasing fraction of its time running GC rather than serving user requests. Eventually, GC cycles grow longer than the 15-minute scheduling interval itself. When this happens, the next scheduled GC attempt overlaps with the previous one and is aborted because it cannot obtain exclusive access to the repository.
GC does eventually repack objects, but the system-load graph shows a delayed saw-tooth pattern: each GC cycle briefly relieves pressure, then load builds again as new work accumulates, with progressively higher peaks as as GC executions become so expensive that they can no longer keep pace with incoming traffic.
Key observations:
- Temporal instability: The saw‑tooth pattern leads to oscillating performance. Users see periods of good throughput immediately after GC, followed by worsening latencies until the next GC fires. This instability is visible even when the average throughput remains high.
- GC cost escalation: Each successive GC run takes longer because the repository is larger and more fragmented. The schedule does not adapt, causing GC to run during peak load and further slow down the system.
- Partial improvement: Compared with the baseline, rule‑based GC delays the point of collapse. However, it fails to maintain low Counting and SFR times for more than 12 hours and introduces performance jitter that developers and CI systems will notice.
Alternatives
A natural question at this point is whether alternative strategies, such as geometric repacking, could be used instead of traditional GC.
In practice, when it comes to JGit, which Gerrit relies on, this is not really an option, as geometric repacking is not currently supported.
Even if we tried to run it externally using C Git, it would not integrate well with Gerrit. Packfiles would be replaced abruptly, continuously invalidating JGit caches, and the resulting layout would not be ideal, as C Git does not separate heads and non-heads packfiles.
For these reasons, we focused on approaches that are commonly used in practice and that fit naturally within Gerrit’s execution model and repository structure.
GHS: System load stabiliser and performance accelerator
The GHS approach uses an intelligent agent to monitor repository metrics and decide when any action is required. At each decision point, the agent can either do nothing, create bitmaps, repack references, prune packfiles, and perform other actions. A reinforcement‑learning reward function balances the cost of maintenance against the benefit of reducing future SFR times. As a result, GHS tends to perform less-expensive actions early and avoids the expensive full GCs.
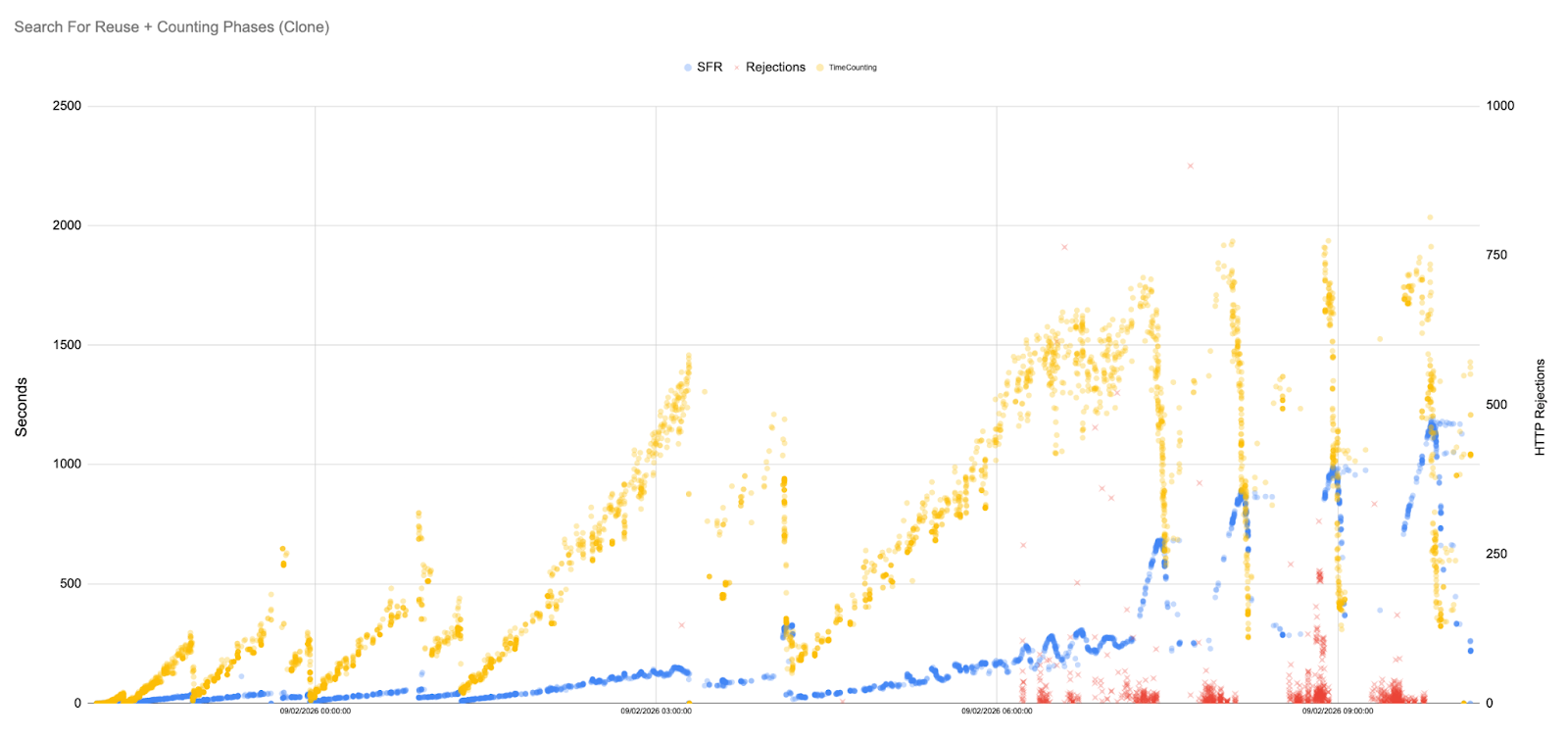
Our GHS runs exhibit remarkably stable SFR and Counting times. The scatter plot below shows most samples concentrated below 500 ms, with only a handful of outliers.
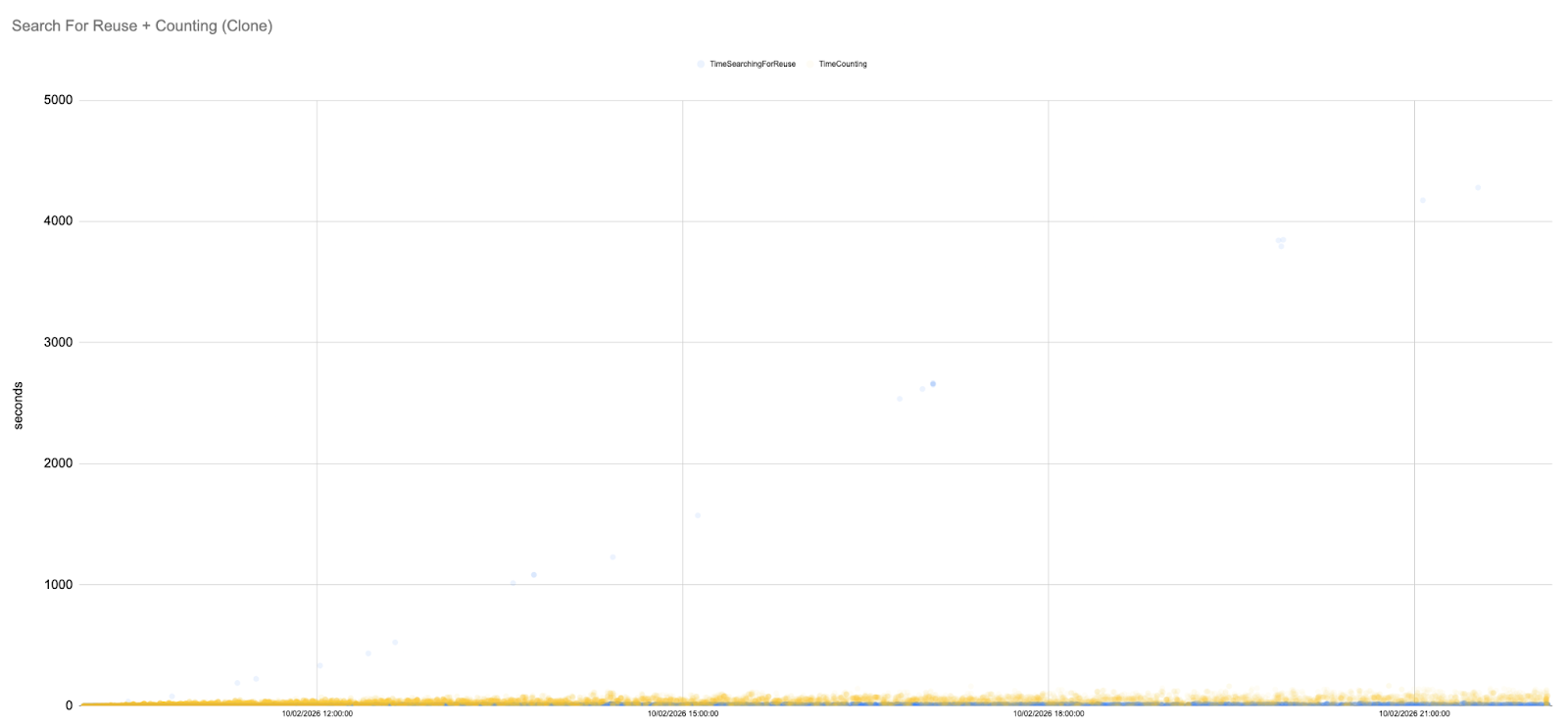
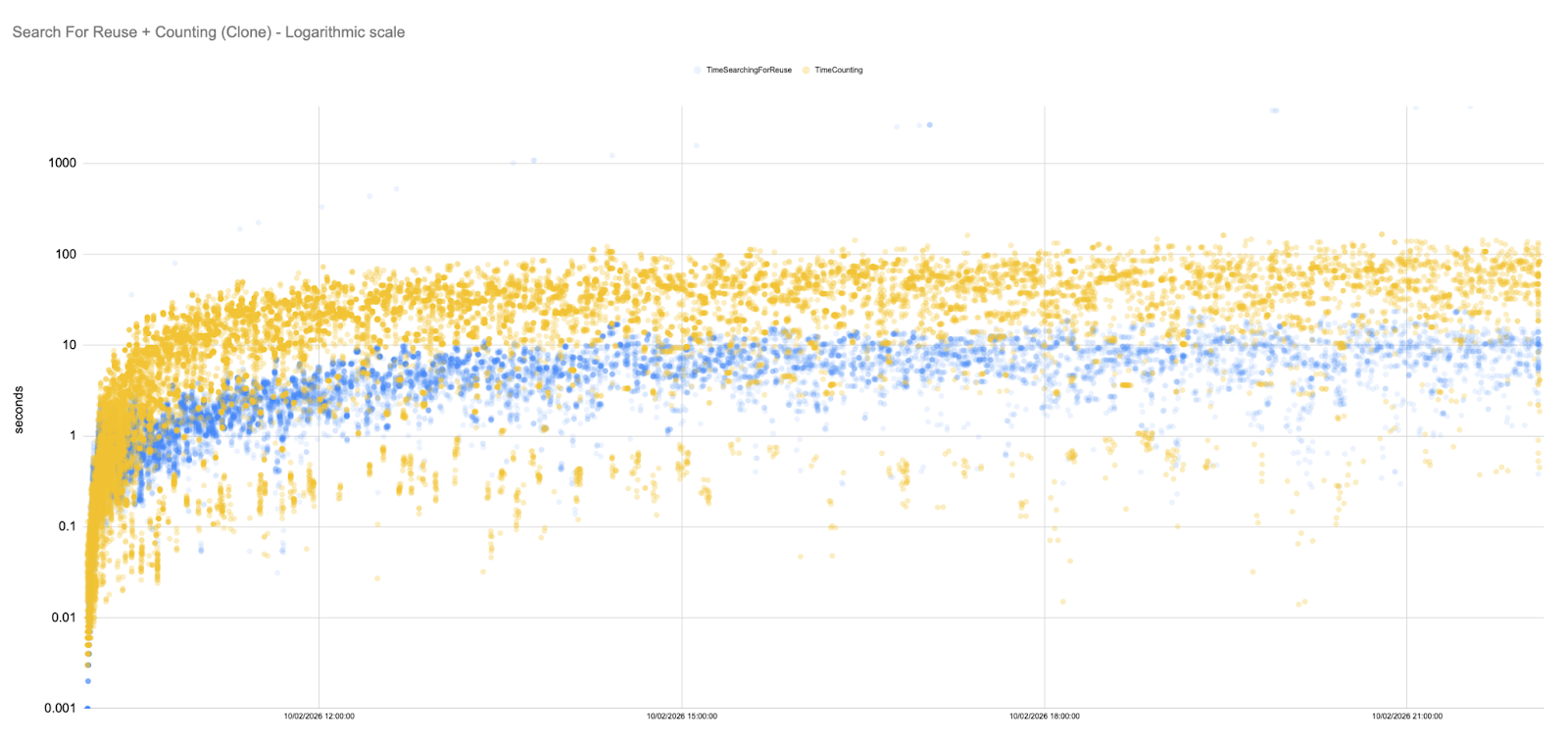
In fact, for long stretches of the simulation, the SFR latencies hover in the 5–50 ms range. To fully appreciate this, it is useful to plot the data on a logarithmic scale.
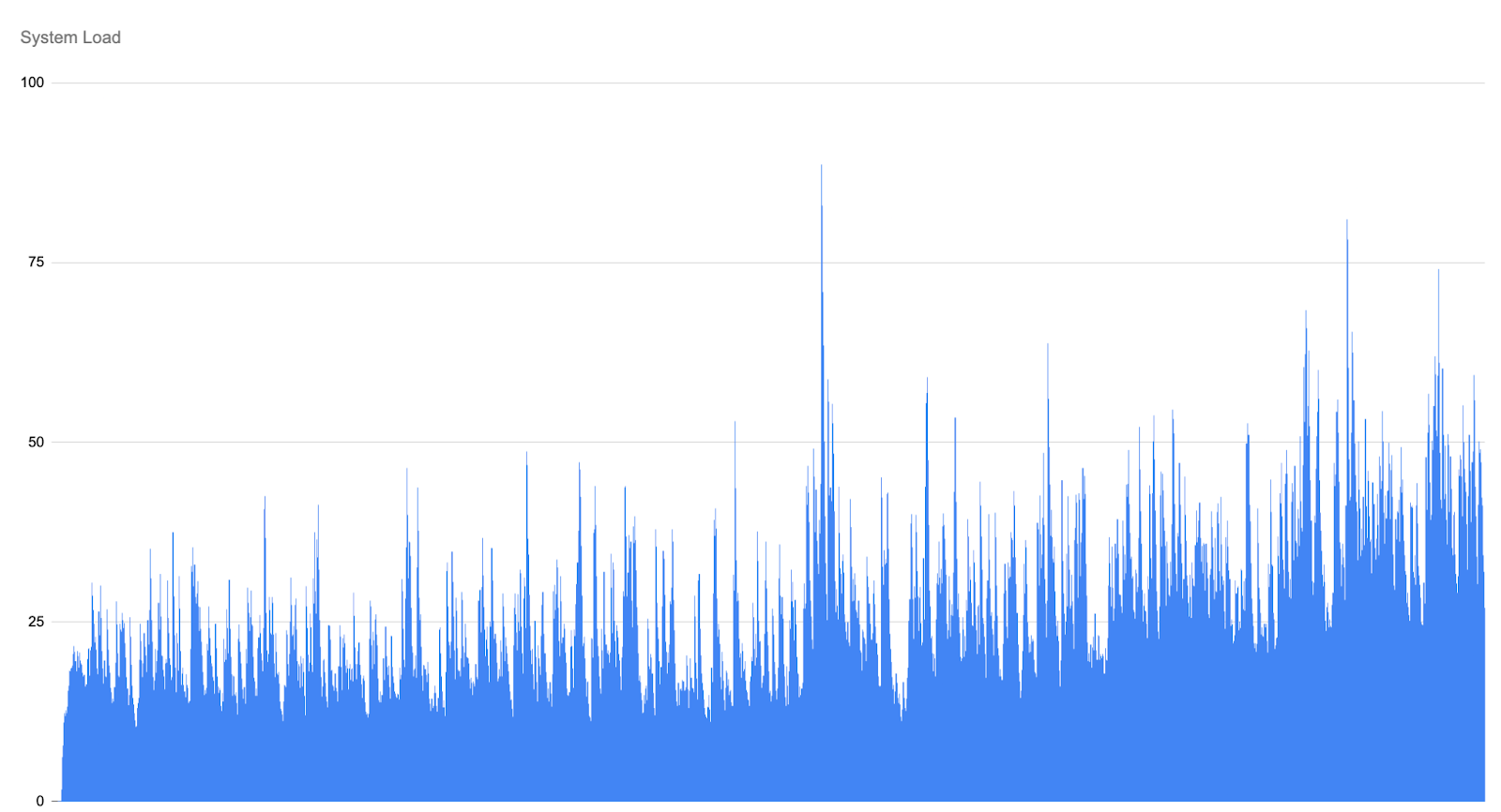
System‑load graphs remain flat, indicating that maintenance tasks performed by GHS are highly optimised and far less expensive than a full GC cycle.
Key observations:
- Flat trend line: Unlike the baseline and rule‑based scenarios, the Counting and SFR metrics under GHS do not grow super‑linearly. Minor fluctuations are present, but the overall trend is remarkably flat.
- Proactive actions: GHS performs frequent, inexpensive, locally optimal tasks, avoiding unnecessary overhead and maintaining high read and write throughputs at minimal cost.
- Learning and improvement: The agent learns from experience. Chosen actions change as the agent converges on an optimal policy.
Comparative Insights
The three maintenance strategies yield starkly different outcomes.
Without GC, SFR and Counting latencies climb linearly, and the repository becomes unusable after a few hours. Rule‑based GC delays but does not prevent this collapse; it introduces periodic relief but suffers from growing GC costs and oscillating performance.
Not only does GHS keep SFR and Counting times low and stable across the entire 12‑hour simulation, but it does so by leaning much less on system load.
In practical terms, these findings suggest that adaptive optimisations are essential for large Git-based installations: scheduled GC can help, but must be complemented with cheaper, more frequent actions.
GHS is uniquely positioned to decide when such actions are beneficial, especially as modern development workflows, including AI-assisted coding and automated tooling, continue to increase the volume and frequency of changes flowing into repositories.
Conclusion
Search‑for‑reuse and Counting are critical metrics for understanding Git repository health.
Our 12‑hour stress tests show that no maintenance leads to runaway SFR and Counting latencies and system collapse, while periodic GC offers only temporary relief and introduces instability.
In contrast, GHS employs reinforcement‑learning and a palette of actions to keep the repository efficient. The result is a dramatic reduction in SFR and Counting latencies, keeping them as efficient as possible, and sustained throughput throughout the simulation. Importantly, GHS achieves these gains while consuming far less CPU and memory: system‑load graphs remain flat, the agent helps reduce the need for expensive full-GC runs, and the server never approaches the overload thresholds seen in the baseline and rule‑based scenarios.
This lighter footprint translates into lower infrastructure cost, fewer cores and smaller memory footprints are needed to support the same workload, while simultaneously improving user experience. For DevOps engineers and Git administrators, these results highlight the importance of intelligent, adaptive acceleration strategies. Deploying a tool like GHS can transform the developer experience from unpredictable slowdowns to consistent, high‑performance operations, and do so economically by minimising resource consumption.