It has been a challenging year, a strange year, for everyone. Most of us confined in our homes and working remotely, finding new ways of dealing with old problems.
Still, we believe the Gerrit Community as a whole has demonstrated an outstanding level of resilience in the face of exceptional difficulties. As far as we are concerned, we have seen no lesser activity, interest, new projects, compared to the previous years. For this, we are thankful to the community we are so strongly proud of being a part of.
In sharing our most sincere vows for happy festivities and a fruitful new year, we wanted to take the opportunity to share with you some of the achievements that made this 2020 worth getting through.
Top-Ten achievements in 2020
1. GerritForge has confirmed to be the world’s largest non-Google contributor to the Gerrit Code Review project.
GerritForge contributed almost a thousand changes merged, over 47 different components in the past 12 months. That is an outstanding achievement confirming the commitment and dedication of the company to the Gerrit Code Review platform and community.
2. Improved Gerrit DevOps Analytics with the ability to process Changes hashtags
The Gerrit DevOps Analytics platform continued to expand its possibilities, with the full support of the parsing of the NoteDb changes and the extractions of precious meta-data, such as the changes hashtags.
3. Driven two major releases of Gerrit Code Review
GerritForge helped driving the release of two major Gerrit Code Review version: Gerrit v3.2 – 1st June and with Ericsson making the Gerrit v3.3 – 1st December. GerritForge is also providing the CI/CD pipeline for the build and validation of the releases and helped the migration to Java 11.
4. Released major security fixes for the whole Gerrit Community, of all Gerrit versions dating back to v2.14
5. Brand-new Gerrit module cache-chroniclemap, a new high-performance persistent cache in Gerrit v3.3
GerritForge continued its efforts in improving Gerrit’s scalability and performance with the development of a brand-new persistent cache backend powered by ChronicleMap, showing unprecedented low latency and performance on Gerrit v3.3.
6. Introduced the world-first official Open-Source AWS-based Gerrit Code Review Deployment
In a year of remote working and flexible environments, GerritForge provided its contribution to the whole community to help adopting Gerrit in the cloud. The aws-gerrit project is a brand-new production-ready AWS deployment now available for everyone and fully Open-Source. The new project is based on the GitOps best-practices and has been successfully adopted for the testing and validation of Gerrit v3.3.
7. New read-write scalability for Gerrit in High-Availability
GerritForge’s mission to scalability and high-availability (HA) plugin continued with the ability to scale horizontally with multiple R/W Gerrit Servers behind the same load balancer.
8. Improved reliability and flexibility of Gerrit Multi-Site
The Gerrit Multi-Site (MS) plugin has received exciting improvements with the support for geographically distributed R/W Gerrit servers across the globe.
9. Brand-new pull-replication plugin for improving latency and performance of large mono-repos replication.
The need to have Gerrit multi-site brought the request to have faster replication, especially for large mono-repos. GerritForge introduced a new pull-replication plugin project that, used in conjunction with Git Protocol v2, assure top-notch performance in replicating repositories with large number of refs.
10. Helped large-scale OpenSource Community migrating to Gerrit v3
The Eclipse Foundation and the OpenDev platform (by OpenStack), upgraded to the latest version of Gerrit Code Review, thanks to the continuous help and support from GerritForge and the rest of the Gerrit Code Review community.
All the best, Stay Safe, and we will shake hands again soon!
Accelerating your time to market while delivering high-quality products is vital for any company of any size. This fast pacing and always evolving world relies on getting quicker and better in the production pipeline of the products. The whole DevOps and Lean methodologies help to achieve the speed and quality needed by continuously improving the process in a so-called feedback loop. The faster the cycle, the quicker is the ability to achieve the competitive advantage to outperform and beat the competition.
It is fundamental to have a scientific approach and put metrics in place to measure and monitor the progress of the different actors in the whole software lifecycle and delivery pipeline.
Gerrit DevOps Analytics (GDA) to the rescue
We need data to build metrics to design our continuous improvement lifecycle around it. We need to juice information from all the components we use, directly or indirectly, on a daily basis:
SCM/VCS (Source and Configuration Management, Version Control System) how many commits are going through the pipeline?
Code Review
what’s the lead time for a piece of code to get validated?
How are people interacting and cooperating around the code?
Issue tracker (e.g. Jira)
how long does it take the end-to-end lifecycle outside the development, from idea to production?
Getting logs from these sources and understanding what they are telling us is fundamental to anticipate delays in deliveries, evaluate the risk of a product release and make changes in the organization to accelerate the teams’ productivity. That is not an easy task.
Gerrit DevOps Analytics (aka GDA) is an OpenSource solution for collecting data, aggregating them based on different dimensions and expose meaningful metrics in a timely fashion.
GDA is part of the Gerrit Code Review ecosystem and has been presented during the last Gerrit User Summit 2018 at Cloudera HQ in Palo Alto. However, GDA is not limited to Gerrit and is aiming at integrating and processing any information coming from other version control and code-review systems, including GitLab, GitHub and BitBucket.
Case study: GDA applied to the Gerrit Code Review project
One of the golden rules of Lean and DevOps is continuous improvement: “eating your dog food” is the perfect way to measure the progress of the solution by using its outcome in our daily life of developing GDA.
As part of the Gerrit project, I have been working with GerritForge to create Open Source tools to develop the GDA dashboards. These are based on events coming from Gerrit and Git, but we also extract data coming from the CI system, the Issue tracker. These tools include the ETL, for the data extraction and the presentation of the data.
As you will see in the examples Gerrit is not just the code review tool itself, but also its plugins ecosystem, hence you might want to include them as well into any collection and processing of analytics data.
Wanna try GDA? You are just one click away.
We made the GDA more accessible to everybody, so more people can play with it and understand its potentials. We create the Gerrit Analytics Wizardplugin so you can have some insights in your data with just one click.
What you can do
With the Gerrit Analytics Wizard you can get started quickly and with only one click you can get:
Initial setup with an Analytics playground with some defaults charts
Populate the Dashboard with data coming from one or more projects of your choice
The full GDA experience
When using the full GDA experience, you have the full control of your data:
Schedule recurring data imports. It is just meant to run a one-off import of the data
Create a production ready environment. It is meant to build a playground to explore the potentials of GDA
You can find here more detailed information about the installation.
One click to crunch loads of data
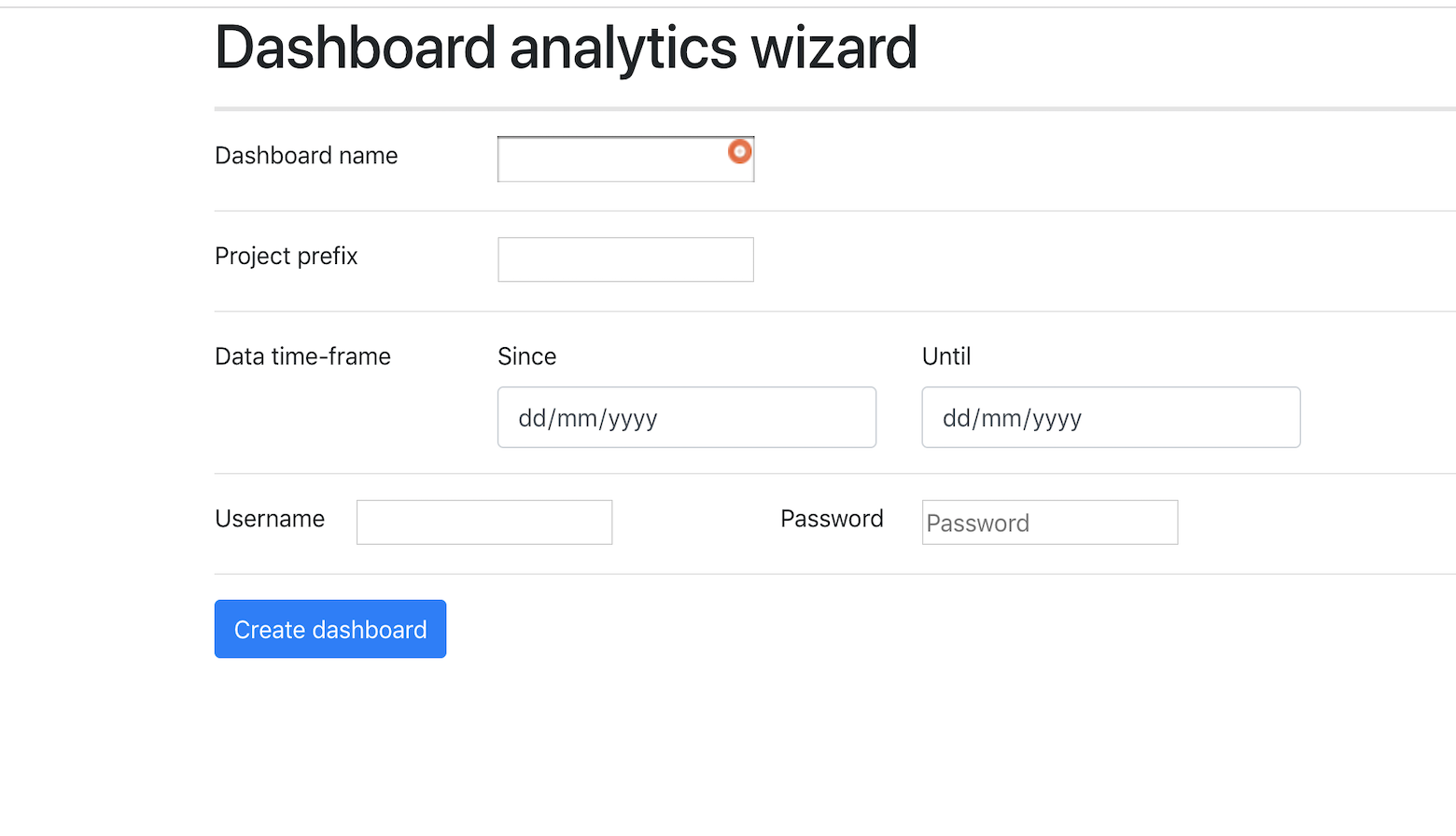
Once you have Gerrit and the GDA Analytics and Wizard plugins installed, chose the top menu item Analytics Wizard > Configure Dashboard.
You land on the Analytics Wizard and can configure the following parameters:
Dashboard name (mandatory): name of the dashboard to create
Projects prefix (optional): prefix of the projects to import, i.e.: “gerrit” will match all the projects that are starting with the prefix “gerrit”. NOTE: The prefix does not support wildcards or regular expressions.
Date time-frame (optional): date and time interval of the data to import. If not specified the whole history will be imported without restrictions of date or time.
Username/Password (optional): credentials for Gerrit API, if basic auth is needed to access the project’s data.
Sample dashboard analytics wizard page:
Once you are done with the configuration, press the “Create Dashboard” button and wait for the Dashboard, tailored to your data, to be created (beware this operation will take a while since it requires to download several Docker images and run an ETL job to collect and aggregate the data).
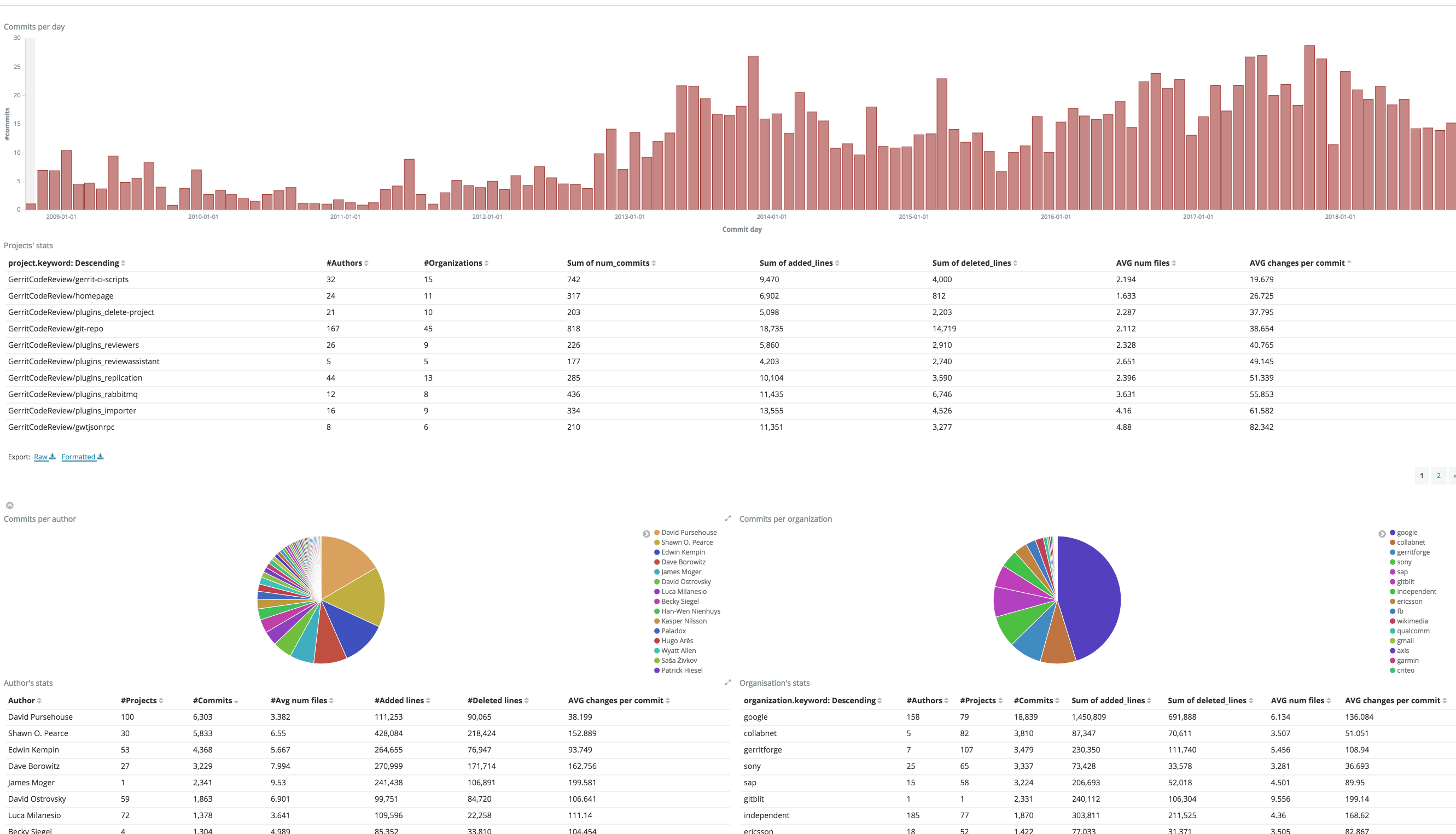
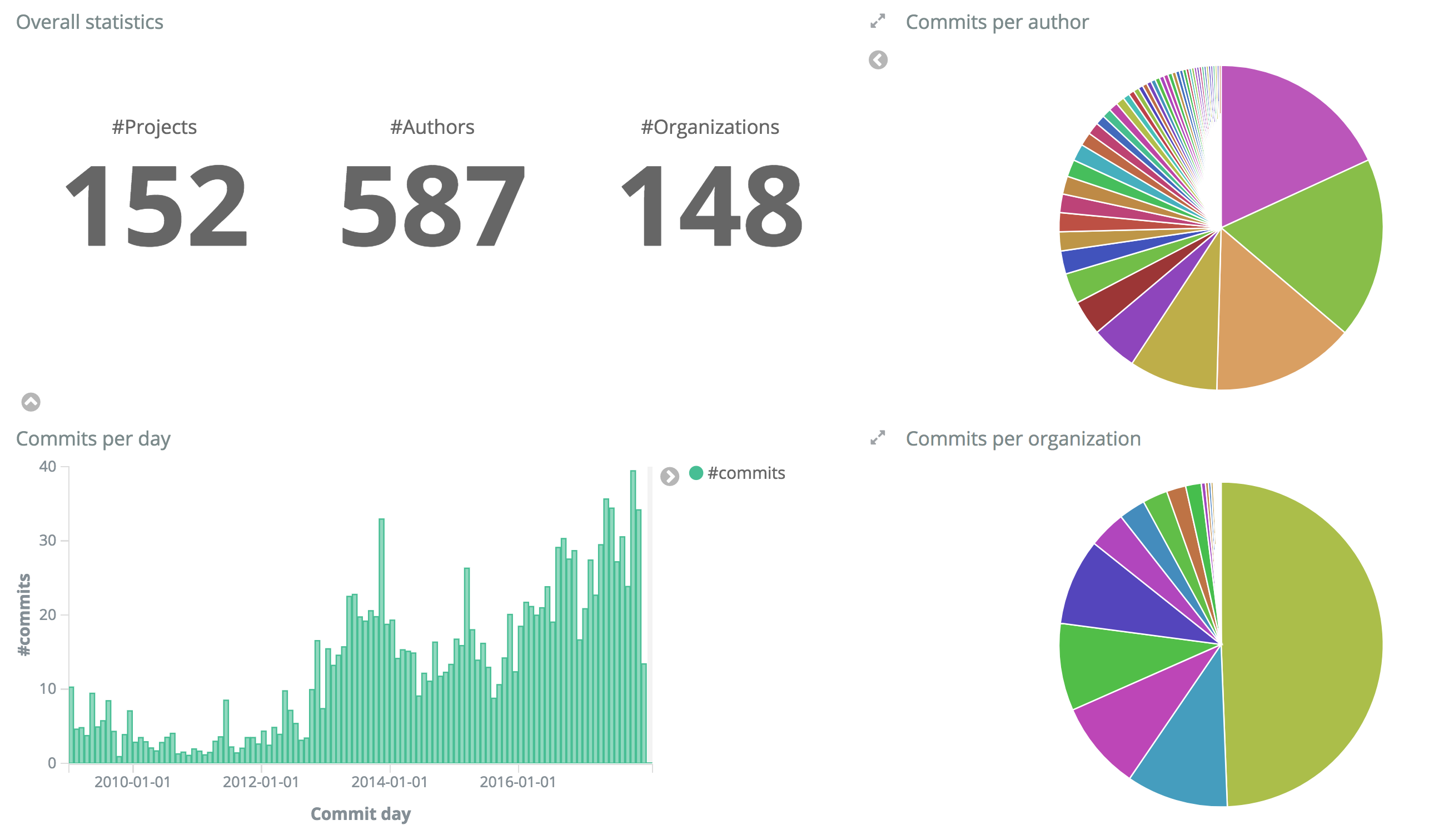
At the end of the data crunching you will be presented with a Dashboard with some initial Analytics graphs like the one below:
You can now navigate among the different charts from different dimensions, through time, projects, people and Teams, uncovering the potentials of your data thanks to GDA!
What has just happened behind the scenes?
When you press the “Create Dashboard” button, loads of magic happens behind the scenes. Several Docker images will be downloaded to run an ElasticSearch and Kibana instance locally, to set up the Dashboard and run the ETL job to import the data. Here a sequence workflow to illustrate the chain of events is happening:
Conclusion
Getting insights into your data is so important and has never been so simple. GDA is an OpenSource and SaaS (Software as a Service) solution designed, implemented and operated by GerritForge. GDA allows setting up the extraction flows and gives you the “out-of-the-box” solution for accelerating your company’s business right now.
Contact usif you need any help with setting upa Data Analytics pipeline or if you have any feedback about Gerrit DevOps Analytics.
It is exciting times for the Gerrit Code Review project, which is approaching its 10th anniversary. The very first commit is dated 14th of November 2008, exactly ten years back from the official kick-off the 15th of November 2018 of the Gerrit User Summit 2018 in Palo Alto
commit 23571ab1fa7fedc262d6c21510614353e9d8a4dc
Author: Shawn O. Pearce <sop@google.com>
Date: Fri Nov 14 16:56:58 2008 -0800
Initial project setup of Gerrit 2
Gerrit 2 is a ground-up rewrite of Gerrit, using GWT (Google Web
Toolkit) for the client side user interface and a Java servlet
based backend.
Signed-off-by: Shawn O. Pearce <sop@google.com>
An exciting schedule with talks about new features
The program is now complete and includes a lot of interesting talks about what’s new and noteworthy in Gerrit:
The summit is kindly hosted by Cloudera, the world’s leader of the BigData OpenSource Platform. It is not a coincidence that there are talks about Gerrit and the DevOps Analytics:
Recordings of the Gerrit User Summit 2017 in London
The best way to get ready to the Summit this year is to watch what happened during the past 12 months, compared to what was announced at the Gerrit User Summit held at Skills Matter in Central London back in 2017, leveraging all the free content available on the GerritForge TV YouTube Channel. There is a lot to learn about Gerrit and its related technologies.
2018 is an exceptional year for the Gerrit Community, and this Summit will most likely be the largest ever in the history of the Git Together and Gerrit User Summits of the past ten years.
I am pleased to announce the availability of Gerrit Code Review Analytics, an Apache 2.0 Open Source solution for extracting, processing and visualizing statistics about your code and developers community.
Why extracting analytics from the source code?
Actually, this is what most of the Git servers have available already out of the box as basic code commit metrics.
GitHub shows for every repository, a basic set of graphs including the overall daily commits and the breakdown on a per-contributor basis.
GitLab displays an overview of what happened on his platform, including push, merge and issue-related events with their correlation to the other GitLab CI components.
… and what about Gerrit? Well, there was basically nothing and we needed to fill the functionality gap and provide even more insights on what happens on the teams and projects that are managed with the Gerrit workflow.
What gets extracted and analyzed from Gerrit Code Review?
Gerrit Code Review has a goldmine of information related to the overall software development lifecycle:
Contributors and their team and company ownership
Repositories and their associated metadata
Git commits with their associated review notes
Feedback on code and review scores
Events on what happens in terms of commits, reviews, refs and much more
Additionally, Gerrit Code Review allows having a repository-agnostic view by allowing to query and search for information across multiple repositories.
All that “gold” can be extracted, organized and refined to be leveraged on a global scale and extract useful KPI for the Teams and entire Company.
Which components are needed?
To build an extraction pipeline to dig the “Gerrit Code Review goldmine of information” you need the following components:
We have built a working pipeline that is active 24×7 and is displaying the overall Gerrit Analytics of … the Gerrit Code Review project itself. Best way to iterate on the Gerrit Analytics features is dogfooding as we always did on the Gerrit Code Review project itself.
When can you start using it?
You can start building your Gerrit Analytics pipeline right now by installing the Gerrit Analytics plugin and running the ETL transformation on a regular basis.
If you need any help GerritForge can build and manage the pipeline for you. GerritForge provides the SaaS (Software as a Service) solution for setting up the extraction flows and give you the “out-of-the-box” solution for your company.
This week we are going to publish a talk from the Gerrit User Summit 2017 about Gerrit and Jenkins used together. It is a real-life story on how to set up a CI/CD pipeline for a massive traffic OpenSource project such as Gerrit Code Review and the learnings of how to manage the storage and consumption of the Jenkins build logs and the associated meta-data.
Even if you are not a Gerrit Code Review user, the learnings of this talk are going to be exciting and useful for any high load CI/CD pipeline project with Jenkins.
GerritForge: Gerrit Code Review and Jenkins expertise
I am part of GerritForge, a London-based limited company not specialized in Gerrit, as the name would tell, but also on Jenkins, Continuous Integration and Delivery. Why don’t we use our skills to serve the Gerrit Code Review project? A couple of years ago the project did not have an official CI yet, so we said: “why not help the project and set up an official pipeline to verify all the incoming Gerrit changes to the Gerrit Code Review project itself?”
We then created https://gerrit-ci.gerritforge.com and, as you can see, it is nowadays a jam-packed CI system. We have been running a Hackathon over the weekend, and now, even while people in this room are following this talk, new changes are produced, and reviews are getting pushed to Gerrit, and that keeps our CI busy all the times.
We have a lot of slaves, some of them are provided for free by Google and others are paid by GerritForge. We have been running this service for the last couple of years, and even non-contributors to the Gerrit project like most of you guys are possibly using it for downloading some useful artifacts such as the Gerrit plugins. Additionally, if you want to download and demo the latest and greatest version of Gerrit master, as we just did with some of you before lunch, you can use the Gerrit artifacts on Gerrit-CI instead of building it yourself on your local box.
Gerrit-CI pipeline walkthrough
Let’s have a look at how Gerrit-CI works. You can log in with your GitHub credentials, and then trigger builds for your Gerrit Code Review contribution using a job called “Gerrit verifier change”. That is the most important job of the pipeline and it verifies every single change we make on the Gerrit Code Review project.
How can you manually trigger the build and verification of a change in Gerrit? You navigate to https://gerrit-ci.gerritforge.com/job/Gerrit-verifier-change/ and click on “Build with parameters” link. You enter your change number and then click “Build”: it is straightforward.
What this job does is triggering a workflow developed in Groovy language which it will provide at the end a series of feedback messages to Gerrit. When you go to https://gerrit-review.googlesource.com and list of open changes, you will notice that some of them by one guy that is called “GerritForge CI”. That means that our CI works, yeah!
At a certain point in time, someone in the Gerrit mailing list said: “Houston, we have a problem, we are too productive! We have produced so many changes and patch sets that the time you finish to build a change, we have already produced other 300 patch sets on that job and the build logs get lost”.
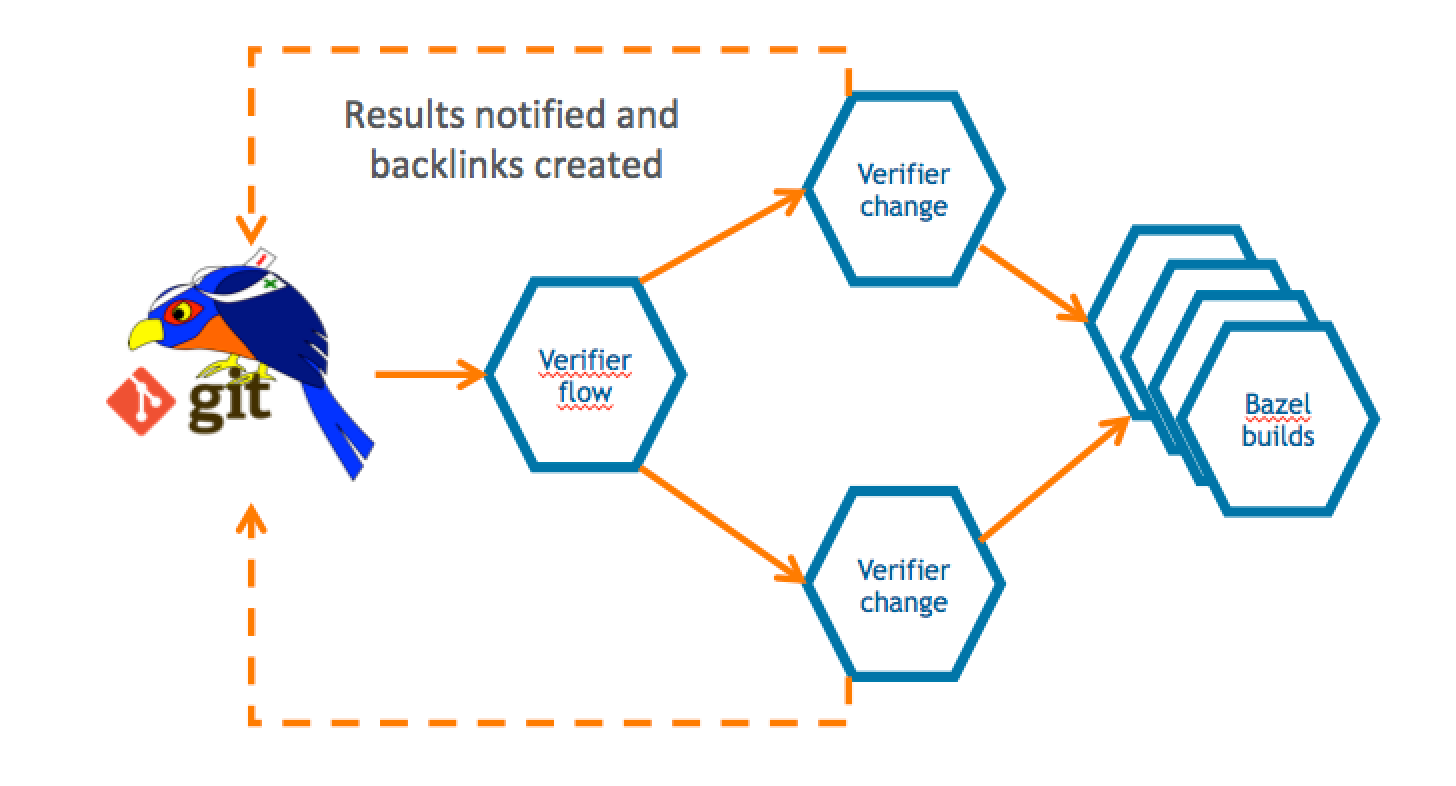
The Gerrit change verifier workflow
Let’s go back for a moment to review how the workflow that we came up with works. It does not rely on the Gerrit Trigger plugin, the de-facto out-of-the-box Gerrit/Jenkins integration that most of the people use, but rather on a complete “new thing” that we have built ad-hoc for our purpose.
We couldn’t use the Gerrit Trigger plugin because of two reasons:
Google data-centers do not allow incoming SSH connections
SSH stream event channel would not have been good enough for us, because of the parallelism needed.
The way that our workflow works if very simple.
The verifier flow requests the list of changes that need verification by leveraging Gerrit query language which allows you to search through most of the fields of changes using a Lucene syntax. For each change that needs checking, a corresponding number of parallel jobs are triggered. This parallelism is potentially unlimited; the only limit is the number of machines that Google can assign to the Gerrit-CI, if he can allocate one hundred, we will be able to perform hundreds of parallel changes verifications.
That means that we can produce a lot of verification jobs at the same time. Bear in mind that for every change we do not trigger just one build: we have NoteDb vs. ReviewDb verification, PolyGerrit UX tests, Code-Style check there was a moment in time where a single change needed up to 6 parallel builds! That resulted into a lot of builds, which, as long as you’ve got enough horsepower in the slaves, it was working fine us.
We do not send feedback to Gerrit for every single build, but we rather have a “Gerrit Verifier Change” job coordinating the workflow and makes a decision accordingly. The criteria are the number of failed builds, the build retries for flaky builds. At the end of the process, all build results are collected and a unique coordinated feedback to send back to Gerrit as a unique verification message.
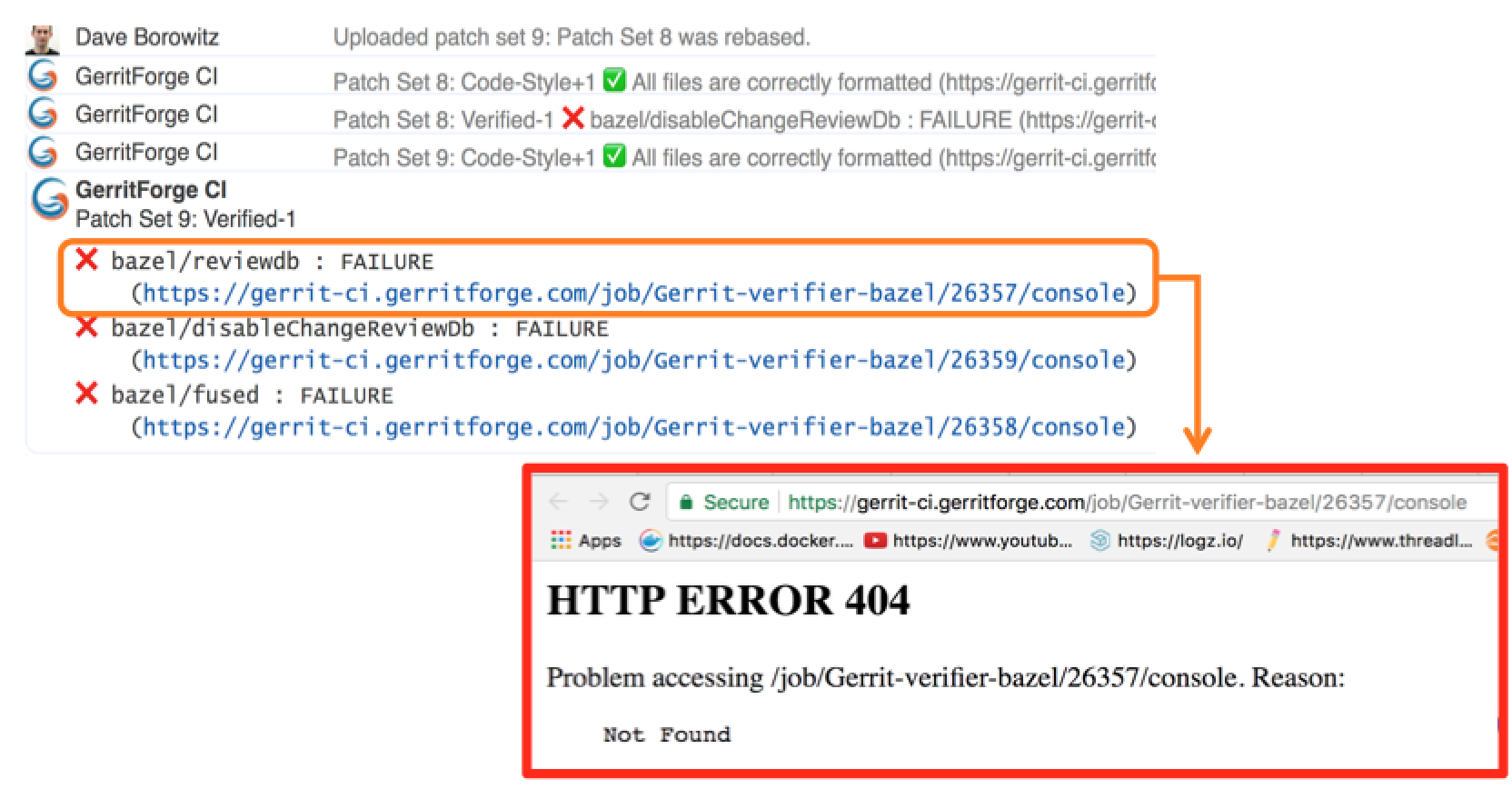
Too many logs for Jenkins lead to a 404 page.
This is all good, but as we said earlier: “Houston, we have a problem, we are too productive!”.
Here are some numbers of our productivity:
300 jobs
170,000 builds
4.8 millions of jar artifacts produced
1.7 billions of lines of logs
And of course, we want to send a link to the build logs we want to give context to the change failure or success. Unfortunately, happened to trace in Gerrit changes some nice links pointing to a quite unpleasant 404 page in Jenkins.
Why did it happen? We have a lot of contributors that generated lots of commit traffic and thus many build runs. There is a policy in Jenkins to remove “old” builds and thus happened that we lost build logs of active changes under review.
Q. (Han-Wen Nienhuys – Google) At Google internal build system we also this kind of numbers but of course with more zeros at the end, but actually we throw away our logs, and if you build binaries, they are very large.
In the beginning, we tried to keep more stuff online in Jenkins but people started saying “Luca, we have a much bigger problem now: gerrit-ci.gerritforge.com doesn’t respond anymore. When I open the Jenkins home page, it takes a very long time and eventually times out.”
That is caused by Jenkins design which is problematic when the number of logs increases considerably: everything is stored as a file and there is no efficient indexing for discovering the data on the filesystem. Additionally, if your company does not have a large infrastructure, your disk space is limited anyway. At GerritForge the Jenkins master has only 8TBytes of disk space, and we don’t have available a system with PetaBytes or more.
Keeping Jenkins logs forever
I made the Gerrit Contributors’ Community aware of the problem and I asked: do we like that? If you think about it, logs are not rubbish. Logs are of immense value, logs are like your money, and analyzing them, crunching and understanding them is our daily job. The timestamps in the logs are like precious diamonds because they tell you that you may have made a mistake in your code and some parts of your pipeline execution start taking a lot more time than before.
When you remove the “old” logs, you make much more difficult to investigate on a failed verification build: the link attached to the change verification message points to a page that returns a 404. That’s not a bug in Jenkins; it’s a feature of removing old logs and keeping the master instance fast and healthy. But actually, it is a real functionality gap because Jenkins doesn’t know yet how to manage logs archiving.
Then I asked the Community: “For how long you want your logs to be retained?” because I needed to raise a PO for a much bigger machine. “One day, one week, one month?” and the answer I got was “Forever!”
If you think about it carefully, the answer is correct. You may not need all those logs at the moment, but in a month’s time, you may need to crunch some data to extract features or metrics. Additionally, getting rid of all logs means generating broken links in my past reviews, which could be an audit requirement stored with Gerrit changes.
Sending Jenkins data to a Logstash appender
It was about time for me to think about a solution and here is a description of what I have done.
First of all, I needed to get more disk space from Google, but then how can I tell Jenkins to use an alternative disk storage mechanism for his logs?
I then started adding to the jobs a plugin called “Logstash” (https://wiki.jenkins.io/display/JENKINS/Logstash+Plugin) which is responsible for capturing and sending Jenkins data to a configured stream appender.
All the Gerrit CI jobs are managed through YAML files which are submitted through code-reviews, using the Jenkins Job Builder tool. However, showing the Logstash configuration on the Jenkins UI is much easier to show where the Logstash is playing a role in the Gerrit-verifier-change job configuration.
I have enabled a new feature to all the jobs to send all the log stream to the Logstash plugin. This works differently to what most of the people would do. Instead of just posting the log file into a stream of lines to ElasticSearch, this plugin gets the information directly from the JVM memory together with its metadata, the timestamp, the build parameters, the environment variables and send them to an endpoint, which could be anything. In this case, I have chosen to use RabbitMQ as stream appender. On RabbitMQ you can notice that I have created a queue for incoming Jenkins messages.
You may notice a lot of activity because every time that the Jenkins jobs produce something, a message is sent to RabbitMQ with the log and the attached meta-data. RabbitMQ is not used though as a storage system but acts only as a vehicle to transfer the information to a long-term storage system, which could be Google Cloud Storage.
The organization of files is straightforward: one file per hour. By looking at the file content, it is a very compressed JSON file that contains all the information I need: the build id, the result, the logs, the parameters.
Spark to the rescue
Problem solved? Can I tell all the Gerrit contributors that they have to look for a build result into a JSON file? Maybe this is not a very nice user experience.
I little more digging is needed to make the solution more transparent to the end user.
GerritForge as a company works and contributes to many BigData projects, including Apache Spark. Why don’t we build an elementary Spark transformation that consumes the input JSON files and materializes back the log into a readable format?
So we built a Spark job that is crunching this data and produces something very very similar to what Jenkins would render. However, we need to make sure to perform all those operations outside the Jenkins domain; otherwise, it would become very soon overloaded and thus unusable.
I have then created another directory that is not actually managed by Jenkins but gets populated by a Spark job. This parallel file structure has exactly the same organization of the build files generated by Jenkins builds.
Let’s have a look for instance at the oldest build that has been recorded by Jenkins: build #31639. For sure if I go to the build #31444, which is older than the #31638, Jenkins would give me a 404 because that job execution has been removed.
However, if I try now to navigate to the build log #31444, wow, I can see the full results as the build log was still accessible.
Additionally, as this log has been produced from the previous JSON file that contains all the meta-data, I can even render more information such as the time-stamps, which are not typically available in Jenkins unless you enable a specific plugin.
Moving forward, by leveraging the same input JSON file, we could do a lot more data crunching as well. It would be interesting for instance to draw a graph of the correlation between the Gerrit changes the build execution times at the different stages.
Uncovering the hidden value of your Jenkins logs
There is a lot more we can do with the JSON I’ve shown you before. It contains not just the log messages, but everything related to the build meta-data of the build and its execution metrics. That means if we go to this change #129553, the link that points to Jenkins logs is not broken anymore, even if it is not served by Jenkins but is backed by the Spark job results.
Starting to applying the same mechanism to all the Gerrit changes and redirecting them to the Google storage where all the files are going to be archived, any change in the Gerrit history will not contain broken links anymore and will be perfectly auditable.
That means that from now, whenever you are going to receive a Verified notification from Gerrit and you navigate to your change links, you are not landing anymore to a 404 page anymore.
Questions.
Q: What if I have a Jenkins instance and I want to do some of this but I don’t have infinite disk-space as Google. Is it is possible to implement?
A: With regards to disk space, you don’t have to go to Google or AWS. You can set up an HDFS filesystem yourself. All the cloud storage implementations available on the Cloud are mainly based on something very similar to HDFS which is an open standard and is available as OpenSource. That means you can store the information there and you do not necessarily need to keep it forever. In practical terms what you need to keep is the lifetime of a release of the software, or a few software iterations, maybe six months, 12 months. As the JSON files are organized on a time-series, it is going to be very easy to remove or archive all the data you do not need anymore. I have shown you how to store those files in JSON, but you can use even more optimised and compressed format such as Avro or Parquet, which may contain 10x times the information in a fraction of disk space. Additionally, when you process them, they can be even faster because they include data encoded in binary format. In a nutshell, the term “keep the logs forever” could be read as “keep for as much as you need: one week, one month, six months, …”. The problem with Jenkins is that for very busy servers like the Gerrit CI, you cannot keep even a single day of logs and when the people are coming the next day to check what’s wrong with a failed verification, would risk having a 404 error page.
Q: So if you do compression and decompression, that needs to happen server-side, so that is transparent to the browser?
A: Yes, that needs to happen on the Server, and there are a lot of ways for doing it, it could be even done on-the-fly, streaming and is pretty fast. There will be a talk tomorrow talking about the methodology to crunch large amounts of data and about the lambda architecture.
Q: Does it generate a RabbitMQ message for each log statement or a unique one at the end of the build?
A: Yes, and the reason is straightforward: If the build crashes or gets aborted for any reason, you do not want to lose your build logs. There was an implementation of Logstash for the Jenkins pipeline that was precisely collecting the logs all at the end of the build, but the design is wrong because if the builds get aborted you do not get feedback at all. Yes, it generates a message for every single line, and possibly RabbitMQ is not the correct implementation of it. But as soon as the Logstash plugin supports the Kafka transport, the performance issues related to the use of RabbitMQ for log streaming will be resolved.
Q: The Logstash plugin that you mentioned, has nothing to do with the “ElasticLogstash” implementation?
A: Yes, it is just unfortunate naming. Actually, the Jenkins Logstash plugin was possibly born before Elastic called his implementation ‘logstash’.
Q: You mentioned that you do Spark processing at some point, but it wasn’t part of your presentation.
A: Yes, it is not part of this presentation for reasons of time, but it is trivial.
Q: Question about the GerritForge CI: I have frequent problems of the test failing not because of my code, and I want to retrigger the tests without having to add a commit to retrigger the CI. Is there a way to retrigger the CI build?
A: Yes, it can be done by going to the Gerrit-verifier-change URL, you click on “Build with Parameters” and enter your change number. You can in this way retrigger any build without having to commit anything.
Q: And if that pass that would assign the Verifier approval to the change?
A: Yes. I would like to add a Button to Gerrit-Review to avoid people to navigate to a different URL.
Q: We are relatively heavy users of Gerrit topics because we have changes that are across multiple repositories. We have a very similar job to this one but we can either put a single or multiple change IDs or a topic name, and it will work out whether it is a consistent declaration. Another thing that you can comment on, you mentioned that the verifier job which runs some independent verifications and then feeds the result as one result to Gerrit, that sounds like something we could use. What is that build using?
A: Tomorrow there will be a presentation of a brand-new integration between Gerrit and Jenkins. The rationale for writing a new integration lies on the thinking that “maybe the Gerrit project is not the only one that needs a bit more from Jenkins.” So why not creating a Jenkins plugin that takes the most of the experience we’ve made in integrating Gerrit with Jenkins for the Gerrit Code Review project and makes it available to the rest of the world? There will a plugin to implement that workflow.
New and exciting features are coming for this year Gerrit User Summit, with the launch of Ver. 2.15, NoteDb, high-availability, multi-master and much more.
The Summit will take place for the very first time in Europe, London, the location chosen by the community after a public consultation, the 2nd and 3rd of October at CodeNode (Skills Matter).
See below an overview of the topics that will be presented and discussed during the User Summit.
What’s new in Gerrit 2.14.x.
Gerrit v2.14 was released during the last Hackathon in April and has gone through three patch releases. David Pursehouse from CollabNet will give an overview of the new features introduced which would be highly beneficial for all of those who haven’t migrated yet.
Gerrit at Google: Multi-master, Mutli-tenant.
Google is the founder, main contributor and possibly the most advanced user of the Gerrit Code Review: learning from their experience is a unique opportunity to learn and being able to leverage and use the tool at its best.
Patrick Hiesel from Google will go through the insights of their Gerrit Code Review architecture and will provide some of their metrics of scale. In addition to that, he will present some findings from the recent switch of their load-balancing infrastructure and the associated pitfalls encountered.
Google is possibly the only one in the world using Gerrit in a multi-tenant setup, having a unique multi-master installation that serves a constellation of domains and projects, including huge and familiar ones like Android and Chromium.
Standing “on the shoulders of giants” like Google helps a lot in preventing scalability issues as the audience and adoption of Gerrit Code Review grows in large companies: being part of the audience in the talk is a unique opportunity to learn and ask questions directly to the maintainers of their infrastructure.
PolyGerrit: a new UX experience for Gerrit Code Review
Google has invested a lot in reinventing and reengineering the user interface of Gerrit Code Review, which remained mostly unchanged for almost a decade. A new team has been put together in their San Francisco offices with experienced UX developers that leveraged the new Polymer framework of web components.
The result is PolyGerrit, a modern web UX which provides an unprecedented browsing speed and flexible rendering across different devices, including mobile and tablets.
The PolyGerrit Team will be presenting the findings of their user-experience research and show some of the features and insights of the new UX.
Gerrit CI and keeping logs forever.
Gerrit Code Review itself is a large project, involving over 300 developers across the globe and using the most advanced DevOps practices. The CI/CD pipeline has been provided and managed by GerritForge on the https://gerrit-ci.gerritforge.com and Luca Milanesio from GerritForge will present the latest improvements in the pipeline plus an interesting way of collecting and reusing the logs.
Leveraging the logs for identifying the bottlenecks of the CI/CD pipeline is the way to drive improvement. GerritForge leveraged the expertise of his engineers to harvest and organize data and will give it back to the community as powerful dashboards.
Beyond Gerrit.
Gerrit is great. However, it is also quite an important part of a bigger ALM process. Jacek Centkowski from CollabNet will describe how multiple tools can be unified under a single TeamForge umbrella and what are the immediate benefits of it.
What’s coming in Gerrit 2.15
After only four months, we are already close to the v2.15 of Gerrit Code Review, which would be possibly the last one before the step to the v3.0.
Dave Borowitz from Google, principal maintainer of the Gerrit Code Review project, will go through the new features of v2.15 and possibly give a glimpse in what to expect from v3.0.
Mining Gerrit Data to Study Contentious Reviews and Community Evolution
Gerrit Code Review is much more than a tool, it is a way for people working together in companies that are large and mostly distributed across the globe.
Shane McIntosh from McGill University has been running a research lab on this topic. The Software REBELs—a research lab at McGill University—mine code review data to study topics like the impact that code review practices have on software release and design quality. Our more recent work mines code review data to study the reviewing process itself. In this talk, I will describe the results of two empirical studies of data that we collected from the Gerrit instances of the OpenStack project. The first study aims to understand the reviews where reviewers disagree about a patch. The second study follows how the concerns that reviewers raise evolve as the OpenStack community ages and individual reviews accrue experience.
Gerrit Analytics: dashboards, networks, KPI
Gerrit has always been lacking major code analytics features compared to other Git Server tools like GitBlit or GitLab. GerritForge Ltd is filling the gap and adds one important asset to the Gerrit Code Review platform: code review analytics.
We need to harvest and unify the logs and events coming from the different components of the CI/CD pipeline by putting at the center of it the people and teams that are building and discussing the code on Gerrit. The resulting data-lake of information can be later analyzed and correlated to calculate the cycle time of the entire pipeline.
Luca Milanesio from GerritForge will show the new analytics dashboards that are going to be published and provided back to the Team that is developing the Gerrit Code Review project as a precious contribution to the community.
How to extend Gerrit using Scripting Plugins
Gerrit Code Review has a robust set of API that can be used to extend its functionalities and provide a more integrated development workflow for the Teams.
Luca Milanesio from GerritForge will present how to use different scripting tools to extend the capabilities of Gerrit without the need of developing and building a plugin, using Jython, Groovy and Scala.
A new simpler but powerful Gerrit Jenkins plugin
Gerrit Code Review is an essential part of a larger CI/CD pipeline. Most of the times it is used in conjunction with Jenkins, the most popular OpenSource Continuous Integration and Delivery tool.
The integration between Gerrit and Jenkins (Gerrit Trigger Plugin) was developed back in 2010 at Sony and since then has been extended and adopted in thousands of Jenkins installations. However, Jenkins has evolved too and has now a brand new concept and definition of multi-branch pipeline which struggles to be seamlessly integrated with the current Gerrit Trigger Plugin.
Luca Milanesio from GerritForge will present a brand new plugin based on the new Jenkins branch discovery API which works seamlessly with Jenkins multi-branch pipelines and provides a simpler interface with Gerrit by leveraging the new WebHooks.
Diffy with enterprise grade
Since 2012 CollabNet has been working on improving Gerrit integration with TeamForge. Many features have been created to satisfy the needs of enterprise customers. Eryk Szymanski from CollabNet will present features like RBAC, history protection, Git style notifications, quality gates, pull request and code browser which have been implemented on top of vanilla Gerrit.
Q&A with the maintainers
Have you ever wondered why something is working in a certain way? Have you ever wanted to explain any complaint about some parts of Gerrit? Would you give your congratulation to the people that made this project? Would you like to make a feature request or propose new ideas?
This is the moment where you can speak directly face-to-face to the people that are building this project every single day, the Gerrit maintainers.
I love hiking mountains; I always did since I was a child. There is a mix of challenges, enthusiasm, and learnings in walking for long hours through little and tortuous steep trails: it challenges your mind and body and makes you stronger.
One thing that always fascinated me is how the shape of peaks and valleys changes as you go higher and raise your perspective. When finally, exhausted, you reach the mountain peak you have a mix of pleasure and relief. You have achieved your goal, and you can, at last, have the full view on the horizon, understand how mountain chains are linked together, where rivers start and end up in lakes, and you can see far away as never before.
Continuous Delivery is a landscape of rivers, lakes, and mountains
I believe today’s landscape of Software Engineering is very diverse: there are so many powerful tools that generate streams of data continuously, and we need to get on top of them every day to be successful in an ever-evolving market space.
Continuous Delivery is the key methodology that nowadays allows the entire “software production chain” working smoothly. However, it poses challenges which are not always technical but often related to the flow of information across the systems and people.
See the big picture
To succeed, we need to raise our point of view to see the “big picture” and understand how things are connected and where are the improvement points, considering all the data we have about:
Tools
collect software and system metrics, logs, test results, build trends
People and Teams
active and passive collaborators, contributors, reviewers, comments and replies
Collecting data is not enough, we need to raise our point of view and hike the Continuous Delivery mountain of problems and reach a point where all those elements make sense because they are:
all visible from a single perspective
correlated
aggregated
Yet another BigData problem
The problem is too many data sources to manage.
The typical solution to the problem is taking all logs from everywhere and publishing them to a single repository using an ELK (ElasticSearch + Logstash + Kibana) stack and building fancy dashboards. I have used this approach for small-scale projects, and it works quite well, but … when I tried to scale that to a much bigger Continuous Delivery pipeline the complexity, diversity, and granularity of data just killed my ability to see the “bigger picture” and I felt almost helpless in front of my Kibana dashboards.
Back to the source of data
Trying to understand what was missing, I ended up realizing that some of the dimensions were not taken into account and correlated: Code Reviews.
All the tooling were about test results, build, system and application logs but none of them has taken the code into account, which is the source of all the pipeline. You can understand where to go if you realize where you are coming from: the code is the source of all build chains.
When I started collecting data from the code repository and reviews, all made sense again, and I felt the I have reached the peak of my Continuous Delivery hiking effort: all made sense again and I could see the overall perspective.
Continuous Delivery Analytics
Exactly in the same way we Application Analytics are used to collecting data about our production system, split into dimensions and analyzed, we need then to start doing the same with our Continuous Delivery pipeline.
There are already some of the tools out there in the market which integrates some parts of it, but I haven’t seen a single one who can give you the bird’s eye perspective you need to understand the big picture.
That’s why I started writing one, using the only way make sense for me: writing in the open and with the help and cooperation of the OpenSource community of people and companies who share the same problem and have the same perspective.
Gerrit Analytics coming at the User Summit 2016
I presented my ideas at a couple of conferences (Devoxx, JenkinsWorld) and I received a lot of appreciation and feedback: the next one is the Gerrit User Summit in Mountain View – CA.
Large companies like SAP, Qualcomm, Ericsson, Google and Intel are exchanging every year their problems and ideas on how to make their Continuous Delivery Pipelines smoother, better and faster.
The perspective will be, of course, more Gerrit Code Review centric with more data and views that make sense from a review perspective.