21 November 2023 (Sunnyvale, CA) – GerritForge Inc. the leader in Gerrit Code Review Enterprise Support, has successfully re-hosted the Eclipse JGit/EGit projects on GerritHub.io, preserving 14 years of the repository history, including all changes, reviews and comments. Everything that has been produced and was historically available on the https://git.eclipse.org/r website is now fully available on https://eclipse.gerrithub.io.
From repo.or.cz to Eclipse
Shawn Pearce (RIP) started the JGit project back in 2006 on repo.or.cz and later joined Google in 2008 where he was given the task to adapt the Gerrit Rietveld Code Review tool for the development of the Android Operating System.
Later in 2009 Shawn started the dogfooding practice by also re-hosting the project on Gerrit Code Review instance, kindly offered to the Eclipse Foundation as self-hosting of the Eclipse plugin for Git (i.e. EGit) and its 100% pure Java implementation of the Git protocol and data format (i.e. JGit). The URL of the self-hosted dogfooding Gerrit instance was https://egit.eclipse.org which was later exposed as https://git.eclipse.org/r.
Here is the first Gerrit change https://git.eclipse.org/r/c/egit/egit/+/1 hosted on the first Gerrit Code Review Server Shawn Pearce and Matthias Sohn hosted ourselves on a vserver we got from Eclipse foundation.
Since then, the Gerrit Code Review project has massively evolved, and Google adopted the tool for all its Open-Source projects in a highly available multi-site and multi-domain setup across the globe. Noteworthy examples are https://gerrit-review.googlesource.com, https://android-review.googlesource.com and https://chromium-review.googlesource.com.
Project growth on Eclipse
The Eclipse Foundation started to encourage all of its projects to adopt Gerrit Code Review, which became the main hub where all the other Open-Source components and contributors were uploading their code and collaborating.
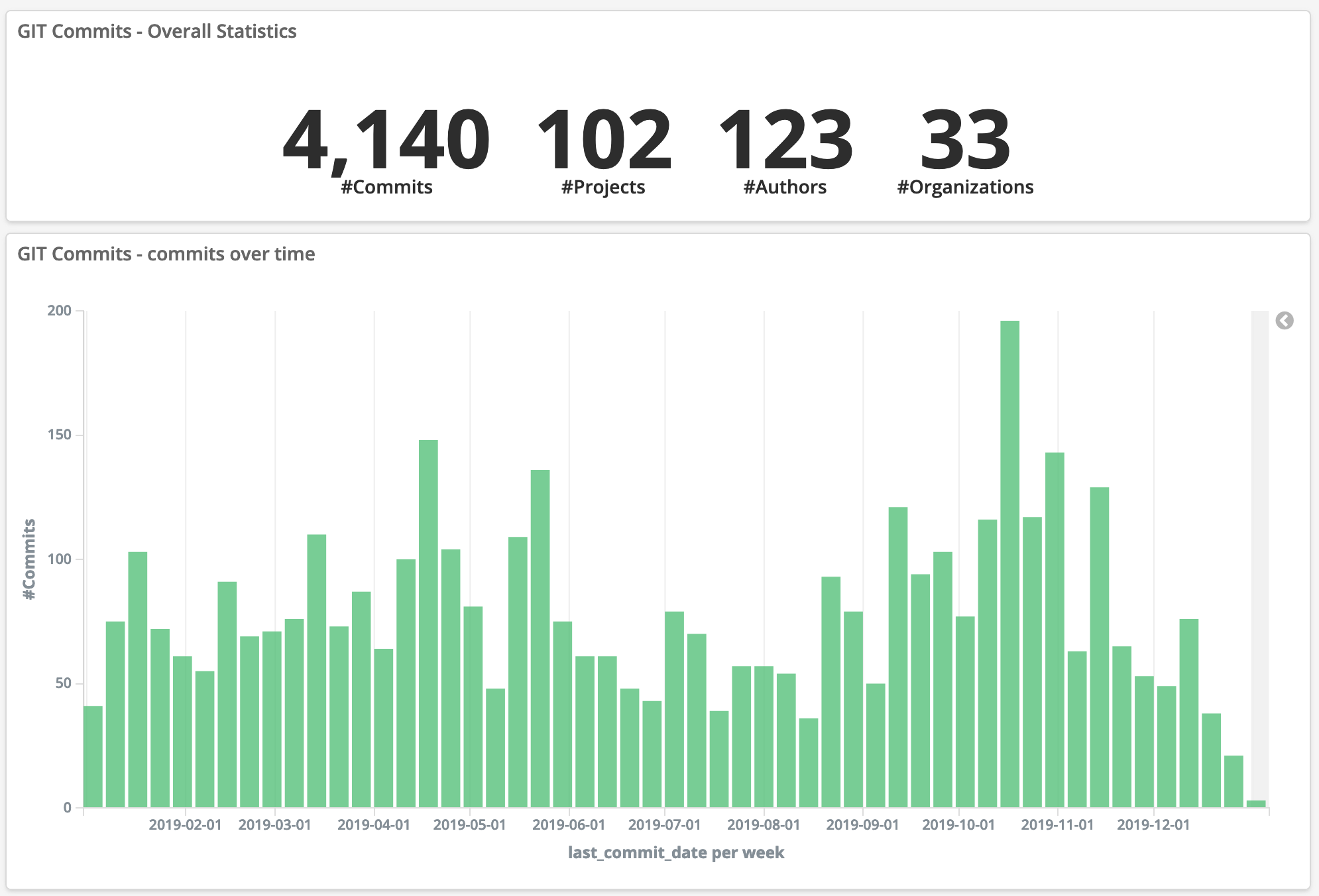
Today, the https://git.eclipse.org/r site hosts over 1300 repositories and tens of thousands of contributors and reviewers.
The risks of the announced shutdown
The Eclipse Foundation started looking at more comprehensive hosting solutions well beyond pure Git hosting and associated Code Review, including GitHub and GitLab and started using them side-by-side with their existing https://git.eclipse.org/r.
In November 2021, the organisation decided to shut down the Gerrit Code Review instance giving as alternatives to migrate the projects to either GitHub or GitLab.
Although both GitHub and GitLab would have offered to keep the code history of all projects, the review information would have been completely lost. Gerrit Code Review has a JSON format (code-named NoteDb) for storing all the review comments together with the repository so that code and review meta-data can be kept safe in the same place. However, GitHub and GitLab have a more traditional relational DBMS approach and would have been unable to render Gerrit’s NoteDb.
If the project would have migrated to GitHub or GitLab, they could have created three main issues:
- All the review history would have been formally accessible in the repository but not visible on the GitHub or GitLab UI
- All associations between the NoteDb data and the committers’ identity would have been lost.
- New reviews of the code developed on GitHub or GitLab UI would have been stored on a server-side relational DBMS.
GerritForge offers to rescue 14 years of review data
GerritForge, the largest contributor to the Gerrit Code Review project outside of Google, leader of the Gerrit Code Review Enterprise Support, launched a new dogfooding project called GerritHub.io back in 2013 with the aim of providing the richer Code Review experience of Gerrit on top of every GitHub repository.
The main goal of GerritHub.io was to enable anyone who has a public or private repository on GitHub to use Gerrit Code Review on top of their existing data. All the authentication, authorisation and publishing of the repository stay on GitHub, whilst GerritHub.io provides the Code Review and collaboration experience.
Because the Eclipse Foundation offered GitHub as one of the alternatives to https://git.eclipse.org/r, GerritHub.io was the most likely candidate to achieve a win-win situation:
- The Eclipse Foundation‘s win: they have been able to shut down https://git.eclipse.org/r and save on hosting and maintenance costs.
- The projects’ win: all their repositories would have been moved to GitHub, and all existing 14 years of review history and new reviews would be accessible through GerritHub.io
The migration project from git.eclipse.org/r to eclipse.gerrithub.io
The migration journey started six months ago, when Matthias Sohn, the project leader of JGit and EGit, announced on the Eclipse Foundation issue tracker that he was planning to use GerritHub.io as Code-Review frontend for his migrated projects in GitHub.
The project was made possible thanks to the introduction of the “importing feature” in Gerrit v3.7, where projects can be moved between Gerrit instances by keeping their change numbers, accounts identities mapping and all associated review data.
Using existing GitHub projects on GerritHub.io is straightforward, and anyone can get started in a matter of minutes; however, the Eclipse Foundation case was more complex because of multiple additional requirements:
- Custom validation of incoming Git commits authors against the Eclipse ECA policies. The Foundation had developed a custom plugin on Gerrit Code Review that needed to be amended to be suitable for a shared-hosting platform like GerritHub.io.
- Virtual isolation of the Eclipse Foundation projects from all the other 56k repositories on GerritHub.io. All the repositories that were migrated from the legacy https://git.eclipse.org/r needed a new “home page” in GerritHub.io called https://eclipse.gerrithub.io
- The Eclipse Foundation needed the configuration of specific OAuth scopes and permission tailored to the roles of the Eclipse Foundation contributors and reviewers.
Last but not least, the migration from https://git.eclipse.org/r to https://eclipse.gerrithub.io needed to be completed with zero downtime and minimal disruption for the existing committers and contributors to the project. Therefore, a classic “big-bang” migration with a planned outage was not an option.
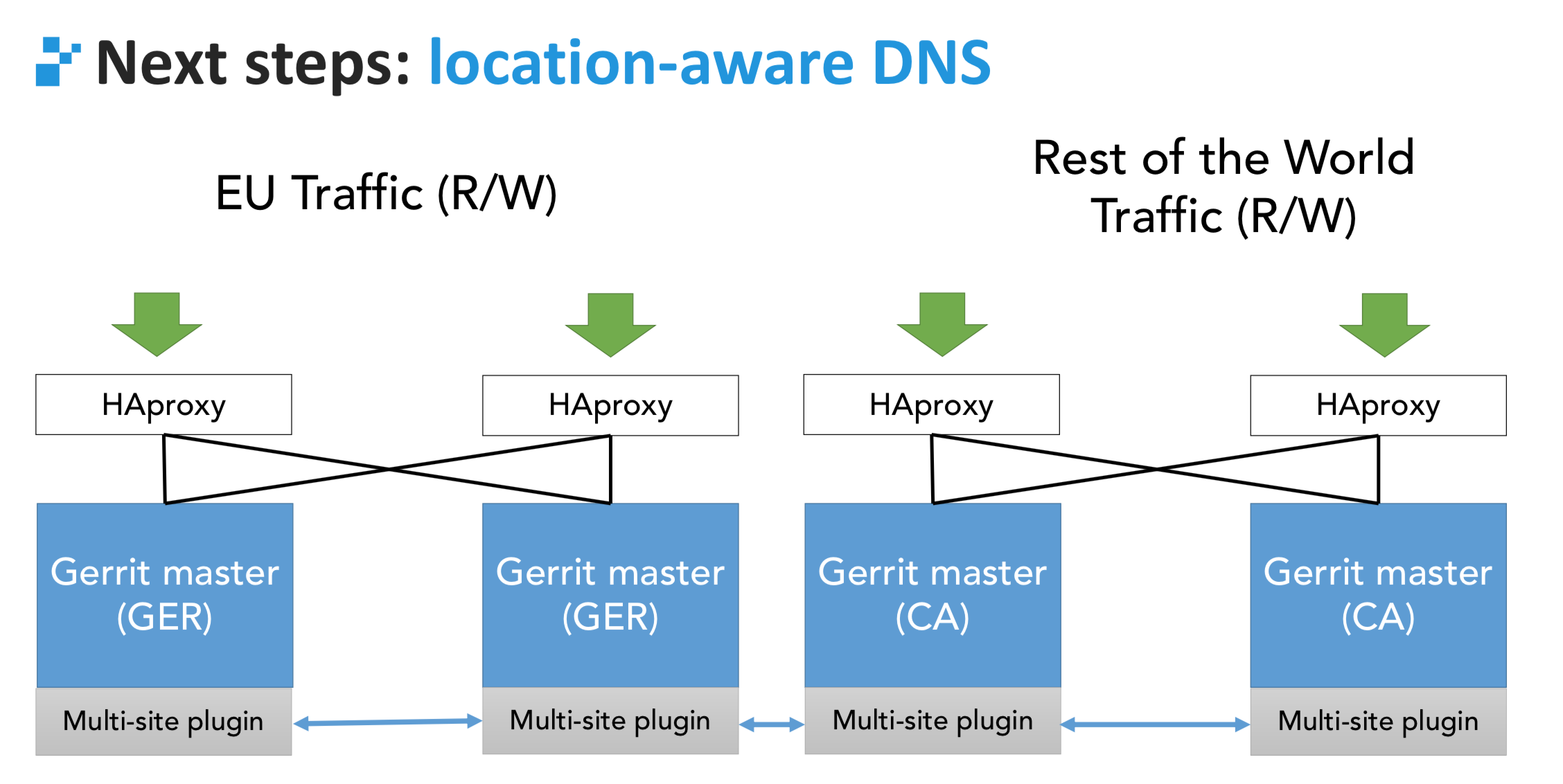
Gerrit multi-site and the enablement of smooth migration paths
Gerrit Code Review has been multi-site at Google for many years, but that deployment was limited to the forked version hosted in Google’s data centres.
GerritForge and the rest of the Open-Source community have invested a lot into publicly available multi-site support since 2018, and it is currently able to provide an equivalent solution on a standard infrastructure, leveraging a global-refdb and events-broker off-the-shelf.

Being multi-site means that the “logical domain” (e.g. eclipse.gerrithub.io), instead of being served by a set of hosts in a single data centre, it can point to different locations across the globe, all active at the same time and accept read/write operations, such as Git push, clone, fetch and code-reviews. The full design of the solution is available on the multi-site plugin repository
When two users are pushing code at the same time to two different sites, Gerrit will check the destination refs against the SHA1 stored in the global-refdb and will coordinate the transactions to avoid ending up in a split-brain situation. Synchronisation between sites is achieved using the pull-replication plugin.
Gerrit Code Review is designed to be future-proof, thanks to a clear separation and contract between the front end and the backend REST-API. That allows a smooth blue-green migration between releases because every release of Gerrit is forward and backwards compatible with its next release +1. For example, GerritHub.io is running two different versions of Gerrit Code Review on different sites as we speak: v3.8.2 in the US and Canada (https://review-am.gerrithub.io) and v3.9.0-rc5 in Europe (https://review-eu.gerrithub.io), without anyone noticing any disruption. Each site progresses towards newer releases bi-weekly whilst the overall service remains active.
Project-based migration from git.eclipse.org to eclipse.gerrithub.io
Gerrit projects include all the commits and meta-data in the same repository and, therefore, have the perfect design to allow an easy migration between servers. However, there are some gotchas:
- Every Gerrit server has a server-id associated with it, which is used to “tag” every change. That prevents Gerrit from parsing and indexing data that does not necessarily belong to the server.
- Every NoteDb meta-data record is strictly decoupled from any Personal Identifiable Information (aka PII), including the full name and e-mails of the authors, committers, owners and reviewers of the changes under review. The lookup between the anonymised identity (aka account-id) and the PII is contained in a centralised repository called ‘All-Users.git’, which isn’t accessible.
- Every change has a unique incremental number associated with it, the change number. The numbering sequence is unique per Gerrit server, but when moving projects between different servers, you may have numbering conflicts.
Luca Milanesio and Matthia Sohn, both maintainers of the Gerrit Code Review project, have cooperated to find solutions to all three problems and have included them in Gerrit v3.7 onwards.
GerritForge has configured the server ID of git.eclipse.org as an “external imported server ID” so that every project coming from the Eclipse Foundation can be parsed and indexed. Its review metadata is rendered on the UI.
The identities are mapped using the public REST-API https://git.eclipse.org/r/accounts/NN/detail, which allows the association of GerritHub users with the legacy Eclipse Foundation account IDs matched by e-mail address.
With regards to the change numbers, the legacy sequence numbers coming with https://git.eclipse.org/r are in conflict with the changes on GerritHub.io; see, for example, https://review.gerrithub.io/5819 and https://git.eclipse.org/r/5819, both valid change numbers but pointing to different projects on different servers.
GerritForge has developed a new ad-hoc plugin to allow existing URLs, previously pointing to https://git.eclipse.org/r, to continue to work as expected on the projects migrated to eclipse.gerrithub.io.
The plugin has a full list of the legacy URLs on https://git.eclipse.org/r and performs the correct redirect to the full equivalent project / change on eclipse.gerrithub.io.
For example, https://git.eclipse.org/r/5819 and https://eclipse.gerrithub.io/5819 are both referring to the same Change-Id:Iff84409c of the JGit project.
eclipse.gerrithub.io as a Gerrit Code Review multi-tenant domain
Gerrit Code Review has secretly supported multi-tenant domains for over a decade; however, that was implemented using a private fork implemented at Google and only in their data centres, as Patrick Hiesel presented at the Gerrit User Summit 2017 in London.
The Open-Source version does not have support for multi-tenancy in the Gerrit core. However, I developed a minimalistic solution six years ago that would give the “user experience” of virtual hosting on Gerrit.
The idea behind the solution is quite simple: hide unwanted projects based on the full domain name, pretty much like the virtual hosts work on the HTTP Servers world.
For example, you could define eclipse.gerrithub.io as follows:
[server "eclipse.gerrithub.io"] projects = eclipse-jgit/* projects = eclipse-egit/*
Shawn himself was stunned when he saw the source code of the virtual-host libmodule back in 2017, with the comment “how did I end up writing so much code, if you did everything in just 7 Java classes?”
To be fair, the solution Shawn implemented on review-*.googlesource.com was a lot more comprehensive than the virtual-host libmodule, because it also included the ability to have different gerrit.config per tenant, whilst the solution implemented on GerritHub.io is a simple extra permission filter applied based on the domain name.
That means that all the Eclipse repositories are effectively available on any of the GerritHub.io sites and also accessible with the main domain URL https://review.gerrithub.io; the filtering on the virtual-host is a pure visibility setting for avoiding the users coming from the Eclipse Foundation from being overwhelmed by the other 50k projects hosted on GerritHub.io.
The advantage is that all the current GerritHub.io sites replicate the Eclipse Foundations repositories, providing, therefore, additional redundancy to the overall setup. All commits pushed to any of the repositories on eclipse.gerrithub.io will also be replicated to all sites, including the ones NOT starting with eclipse.gerrithub.io. Thanks to this redundancy, all the projects hosted on GerritHub.io can benefit from an astonishing 99.997% availability, well above any other free Git hosting sites for Open-Source available right now.
What’s next for the other 1,300 repositories on git.eclipse.org?
The work done for migrating the JGit and EGit projects to https://eclipse.gerrithub.io is the ground needed for the reuse of the same path for many more repositories and projects that want to keep their review history before the legacy git.eclipse.org site is going to be shut down by the Eclipse Foundation.
The scope definition, the user accounts association, and the provision of the users and projects are going to be exactly the same for any other project that wants to move to keep its history.
Once all the projects are migrated, the Eclipse Foundation can define a redirection rule that serves all the incoming requests to https://git.eclipse.org/r and redirects them to https://eclipse.gerrithub.io.
Lessons learnt and takeaway for other migrations
Migrating projects between Gerrit instances was declared impossible just a few years ago; however, that was the end goal of the whole Gerrit NoteDb project. Shawn Pearce used to say that he “would like to make all his reviews locally on his laptops and just push code and reviews once they landed“, making the Code Review an integral part of the Git data format.
The success of this migration project is the demonstration that Shawn’s vision was really innovative and, thanks to the cooperation of the community, projects can last and persevere well beyond the boundaries and lifetime of the people who initially founded them.
Migrating projects and consolidating Gerrit Servers is not something that is only applicable to this example of the Eclipse Foundation server shutdown, but can be further applied to other domains and use cases.
Companies are constantly changing, splitting and merging; projects need to follow the organisation and also move between Gerrit Servers and domains.
All the innovations introduced in Gerrit v3.7 and beyond can serve as an example of the implementation of a different migration path compared to the traditional big-bang approach.
One important lesson from the Eclipse Foundation’s experience is that every migration comes with many little but important details: all of them need accurate evaluation, implementation and testing. Upfront planning is needed; however, many times, many more details are found along the migration path, making it difficult to estimate correctly all the efforts and costs associated. Migrating is like doing daily exercising, the first round sounds quite lengthy and challenging, however, the following rounds can reuse the tools and experience earned in the previous migrations.
Lastly, this exercise has shown how important it is to keep the project’s history for planning its future. It would have been unthinkable for the JGit/EGit projets to continue developing without being able to leverage the learnings, discussions and experience from the past.
“The Code Review history is our legacy; learning from our past gives us direction for our future.”
Luca Milanesio
GerritForge, Inc. – CEO and CTO
Gerrit Code Review Maintainer
Gerrit Release Manager
Member of the Gerrit Engineering Steering Committee