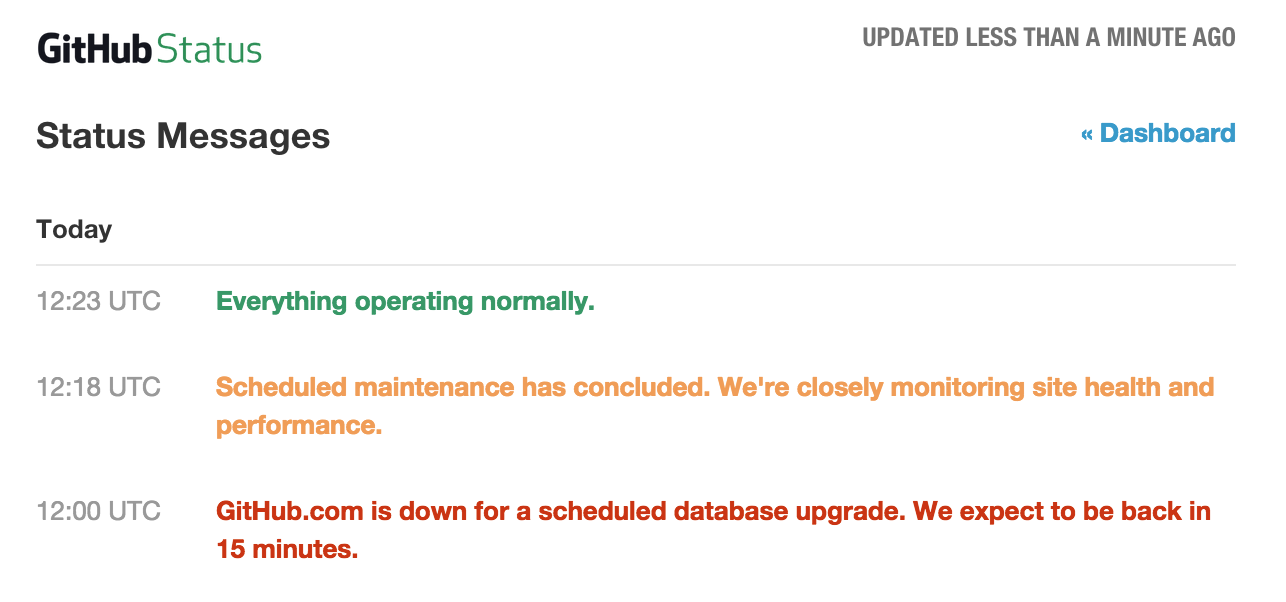
As a bitter surprise today, we are experiencing another GitHub outage. This time it seems a more serious problem than the average DDoS: GitHub’s Ops Team is perform an emergency maintenance on the whole site to recover the situation.
How much a FREE GitHub Service outage really costs me?
Everyone loves GitHub because it is nice, easy and most of all … it’s FREE ! Lots of projects started using it for much more than pure source code versioning:
- People write books and documentation with it (see gitbook.com)
- Teams started using it as free artifacts repository manager: projects wouldn’t build at all when GitHub is down
- Companies started hosting web-pages on GitHub (see the nicely rendered microsoft.github.io)
- GitHub Issue tracking and wikis are so simple that people are using for project collaboration
When everything works, it is amazing how your Team can be productive using GitHub on a daily basis. But when it fails, what can you do? And what if my Team cannot progress because they can’t see the tasks, wikis, requirement documents, web-pages … how much money am I really wasting when people is hanging around for hours?
Let’s consider a small Agile Team composed by a 1 x BA, 8 x Agile Devs, 1 x Scrum Master, 2 x DevOps and 2 x QA: a 30′ minutes outage like the one today would have an impact on 16 people of 1 man/day that means (for the US market) roughly $1,000 (as optimistic guess, it may cost even more). Even if GitHub goes down twice a year (gosh this happened more than twice I am afraid) your start-up will end up paying around $ 2,000 /year for GitHub. The overall amount doesn’t sound that expensive … but you wonder why GitHub “was supposed to be really FREE” if you end up spending money with it.
If we apply the same figures to a medium size company with at least 160 people working on development, your overall figure would jump to $20,000 /year. More importantly the time lost and delays caused on the project schedule may then have an avalanche effect on other teams and maybe causing additional pain and costs across your organisation and programme plan. Those extra costs can be sometimes difficult to quantify but for sure are much more relevant on your overall business.
Shall we give up using GitHub then? Or shall we move to GitHub:Enterprise instead?
The typical reaction to a GitHub outage is: “we cannot rely on the FREE version, we should buy GitHub:Enterprise which will run inside our company network” and use this argument with your manager to get a Purchase Order finalised NOW (I may be too malicious … but a outage may actually generate more money to GitHub than loss of reputation). When you look at the GitHub:Enterprise pricing it ends up that for your 160 people you would need to spend only $36,000 /year which seems on the same order of magnitude of your $20,000 wasted money without considering the extra hidden costs of project delays.
But are you really solving the problem? GitHub and GitHub:Enterprise are the same product, same code-base, just different pricing. What makes you wonder that your internal Ops Team can do a better job than GitHub? What makes you wonder that a GitHub bug would not appear on your GitHub:Enterprise set-up? Are you just an optimistic person?
Moving to GitHub:Enterprise is typicall needed when you have compliance / security requirements on data at-rest, but is not really addressing the problem of reliability and would potentially expose your Team to even further outages for software upgrade and management that typically you don’t have using GitHub alone. You are then spending $36,000 on top of your $20,000 (or even more) wasted previously without having real benefits.
Learning how to fly with GitHub
How to solve the problem then? Can we learn from somebody’s else experience?
Airplanes have exactly (if not even more demanding) requirements on their engines as we on a Version Control System. For an aircraft the cruising speed is everything, without that speed provided by its engines he cannot fly; we have similar requirements in our Development Team where GitHub is really what we need for progressing our development otherwise we are blocked.
The solution to the problem for an airplane to be reliable is not buying more expensive engines (which are not necessarily more reliable) but instead using two engines instead of one. Can we apply the same to GitHub? GitHub is in a nutshell a Git Server, why not relying on redundancy and replication? Can I set-up a replica of GitHub and use it for my reviews?
You can of course build your own replica using plain Git and GitHub WebHooks: it would require a bit of scripting but it can be done. During an outage you can use the replica and when GitHub is back all the pending changes can be pushed back to GitHub.
Can I have another FREE and automated replica of GitHub?
This is becoming challenging now: we want something that is completely FREE (no time spent in writing scripts, webhooks, no service provider to pay, no commercial product) but that allows us to use GitHub replicated, including Code Reviews.
It seems strange but what we are looking for actually exists and it is an OpenSource project called Gerrit Code Review. It is not only a Code Review and Git Server like GitHub but offers as well more advanced security and replication capabilities. It has been designed taking into account the needs of large distributed Teams and making their daily development lifecycle more reliable independently from local failures.
Cool, how can I get started with Gerrit and GitHub now with no hassles?
You read this quick introduction for getting started in setting up your private replica or, you are really in a hurry and you wanted a FREE hosted service, you can sign-up with 3 clicks to GerritHub.io.
I have only 5 mins of free time today: what can I read/watch to understand how it works?
Well, there are plenty of resources but if you are really in a hurry, you can watch the following YouTube Video:
If you have more time, you can read the Gerrit Code Review overview and tutorial at: https://review.gerrithub.io/Documentation/intro-quick.html
Get ready now to avoid wasting again money when the next GitHub outage … that nobody wishes … will (sadly) happen 😦