The Gerrit Code Review Open-Source project has transitioned from using Google Cloud Platform’s Remote Build Execution (RBE) to BuildBuddy’s on-premises to address performance, stability, and latency issues. The migration process included setting up a new Jenkins controller and provisioning BuildBuddy executors on newly provisioned on-premises boxes, which showed significantly reduced build times and a more consistent and reliable performance. After thorough evaluation and community consensus, BuildBuddy was adopted as the new default for Gerrit’s CI/CD pipeline, enhancing overall efficiency and stability.
Historical Context
The Gerrit Code Review project has undergone significant evolution in its build processes to enhance efficiency and performance. This evolution reflects the increasing complexity and demands of modern CI/CD pipelines.
Overview of Gerrit Code Review
Gerrit is a powerful code review tool with a powerful web and command-line interface, all built on top of the Git open-source project. Gerrit codebase is significant and multifaceted, using Python tooling, TypeScript front-end and a Java-based backend. To appreciate the challenges and the need for robust build tools, consider the scope of Gerrit’s codebase and build activity:
- Plugins: Gerrit comprises 14 core plugins maintained as git submodules, plus a universe of over 300 community-based plugins developed in multiple languages, from Java to Scala and Groovy.
- Java Codebase: The project includes 6011 Java files, with 4765 dedicated to production code, amassing ca. 411,768 lines of code (LoC). Additionally, there are 1246 test files (924 unit tests and 322 integration tests) contributing another ca. 276,632 LoC.
- Frontend Codebase: The frontend is built with 110 JavaScript files (ca. 2345 LoC), 733 TypeScript files (ca. 175,765 LoC), 293 HTML files, and 9 CSS files.
- Dependencies: Gerrit relies on 135 Java dependencies managed through Maven and 25 NPM dependencies (5 runtime and 20 development).
Gerrit has been founded in 2008 and has over 15 years of code-history, which reflects the evolution of the build tools, Java VMs and front-end technologies used for over a decade. The pre-requisites that you would have to manage in order to build Gerrit are diverse and quite challenging.
Build and Verification Activity
The Gerrit project is highly active, with rigorous commit-level verification processes to ensure code quality and stability. For example, from June 9 to June 23, 2024, Gerrit handled:
Total of changes:
| Branch | Number of changes |
| master | 65 |
| stable-3.10 | 18 |
| stable-3.9 | 16 |
| stable-3.8 | 15 |
| stable-3.7 | 2 |
| stable-3.6 | 0 |
| stable-3.5 | 1 |
| stable-3.4 | 1 |
| Total | 118 |
Total of revisions (patch sets):
| Branch | Number of revisions |
| master | 230 |
| stable-3.10 | 86 |
| stable-3.9 | 21 |
| stable-3.8 | 22 |
| stable-3.7 | 4 |
| stable-3.6 | 0 |
| stable-3.5 | 4 |
| stable-3.4 | 1 |
| Total | 368 |
Total of Gerrit verifications:
| Type of verification | number of verifications |
| Build/Tests | 277 |
| Code Style | 320 |
| PolyGerrit UI Tests | 124 |
| RBE BB Build/Tests | 271 |
| Total | 992 |
Evolution of Build Tools
The journey of Gerrit’s build tools reflects its growth and the increasing complexity of its CI/CD requirements:
- Apache Maven: Up until version 2.7, Gerrit used Apache Maven as its build tool. Maven, known for its comprehensive project management capabilities, was sufficient during Gerrit’s early stages.
- Buck: From version 2.8 to 2.13, Gerrit transitioned to Buck, a build tool designed for faster builds. Buck’s incremental build capabilities helped manage the growing codebase more efficiently than Maven.
- Bazel: Since version 2.14, Bazel has been the default build tool for Gerrit. Bazel’s advanced features, including its support for remote caching and execution, provided significant improvements in build performance and scalability.
Transition to Bazel with Remote Execution and Caching
In December 2020, Gerrit Code Review made a significant shift by adopting Bazel with remote execution and caching to address the challenges of long build times. This strategic move aimed to leverage Bazel’s advanced capabilities to enhance the efficiency of the CI processes.
Reasons for the Shift
The primary driver for this transition was the increasing build times due to the growing complexity and size of the Gerrit codebase. The conventional local build processes were becoming a bottleneck, slowing down the development and integration cycles.
Implementation with GCP Remote Build Execution (RBE)
Gerrit integrated Google Cloud Platform’s Remote Build Execution (GCP RBE) as the remote server to support this transition. The integration provided several key benefits:
- Reduced Build Times: By offloading build and test tasks to powerful remote servers, build times were significantly reduced.
- Efficient Resource Utilization: Local machines were freed from heavy build tasks, allowing developers to continue working without interruptions.
- Scalability and Parallelisation: Remote execution and the parallelisation of Gerrit’s Bazel tasks allowed to leverage the scalable cloud resources.
This implementation marked a crucial enhancement in Gerrit’s CI/CD pipeline, setting the stage for further optimisations and improvements in the build process.
Motivation to find RBE alternatives
The RBE implementation on Google Cloud has served the Gerrit Code Review project successfully for many years; however, the needs of the project grew over time and the CI/CD infrastructure had to satisfy additional requirements.
- Stability: Google Cloud is SaaS solution which could be flaky at times, whilst the project needed a stable deployment with full control on its stability not influenced by external factors.
- Latency between the controller and the executors: the latency between the main CI/CD controller (Jenkins) and the RBE executors paid a significant price for shorter builds like the Code-Style checks, whilst a localised data processing resulted in faster build times and quicker feedback cycles.
- Predictability: Consistent and reliable performance is crucial for efficient CI/CD workflows.
Moving to BuildBuddy RBE
BuildBuddy is an open-core Bazel build event viewer, result store, remote cache, and remote build execution platform that provided many new benefits to the Gerrit Code Review builds:
- Integration and Customisation: the integration with the existing CI/CD pipelines was straightforward.
- Open Source Community: BuildBuddy, being open-core, benefits from community-driven innovation and collaborative support.
- Enterprise Features: BuildBuddy Enterprise offers advanced features for companies that need robust capabilities:
- OpenID Connect Auth Support: Integrates with Google OAuth.
- Remote Build Execution: Supports custom Docker images.
- Configurable Bazel Caches TTL: Allows setting TTL for build results and cache with support for persistent build artifact storage.
- High Availability: Configurations for high availability also on-premises
- Control and Stability: On-premise deployment offers full control and enhanced stability by minimizing reliance on external factors.
- Very Low Latency: Localized data processing results in faster build times and quicker feedback cycles: we could locate the executors and the Jenkins controller in the same data-centre with micro-seconds network latency.
- Predictable Performance: Consistent and reliable performance is crucial for efficient CI/CD workflows, thanks to the dedicated always-on executors.
BuildBuddy RBE allowed more development efficiency and reliability for the Gerrit Code Review project, making it a compelling choice for optimizing CI/CD processes while leveraging the benefits of open-source software and robust enterprise features.
What was the migration plan ?
To clarify a few points for a better understanding of the this section:
- Scope of Bazel RBE Execution: Bazel RBE is executed only in the Gerrit project and its core plugins (git submodules). It is not executed in non-core plugins, such as pull-replication, high-availability, multi-site, etc.
- Branch Support: From a CI/CD perspective, only the master branch and the last three stable branches are supported for Gerrit project, core and non-core plugins. At the time of the migration, these branches were master, stable-3.7, stable-3.8, and stable-3.9.
The initial phase of the migration aimed to assess the reliability and stability of BuildBuddy RBE. A priority in this phase was to maintain the current CI/CD process while simultaneously evaluating BuildBuddy RBE without any disruptions.
To achieve this phase, several updates and new services were implemented:
Adding BuildBuddy Bazel remote configuration in Gerrit master branch.
Provisioning BuildBuddy Executors: A cloud host was provisioned with the following specifications: 128 CPUs, Intel(R) Xeon(R) Gold 6438Y+, 128GB RAM, and SSD. This host runs 3 BuildBuddy executors (as docker containers).
Setting up a new Gerrit CI Server: A new Jenkins server was set up to run build jobs against BuildBuddy RBE on the Gerrit master branch. This server is not accessible from outside.
Registering a new Gerrit verification: A new verification named RBE BB Build/Tests was added to gerrit-review.googlesource.com to trigger builds on the new Gerrit CI server whenever a new revision was created on the Gerrit master branch.
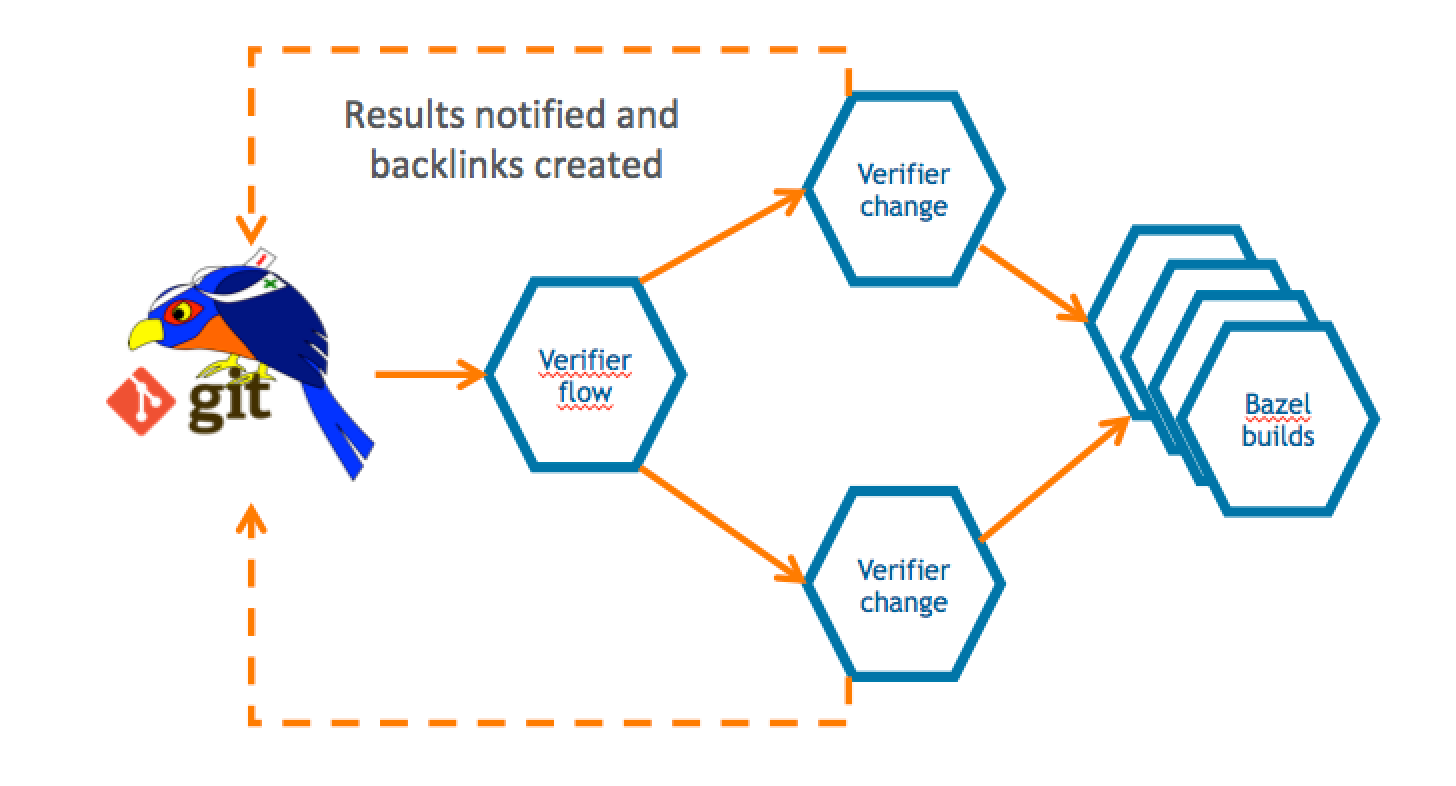
Figure 1: Architecture Migration diagram with default CI flow and new BuildBuddy CI flow:
How is the new CI/CD flow?
In the default CI flow, when a user creates a new revision (patch set) in Gerrit master, or stable-3.7 or stable-3.8 or stable-3.9 branches, a set of verification jobs trigger Jenkins jobs. These verification jobs include:
- RBE GCP Build/Tests: Builds the codebase and executes all the unit/integration tests on GCP RBE.
- Code Style: Checks Java and Bazel formatting, and JavaScript lint.
- Build/Tests: Builds the codebase and executes one single no-op test.
- PolyGerrit UI Tests: Executes unit/integration tests for PolyGerrit UI.
If any of the verification jobs fail, the verification status of the revision is marked with a -1.
As mentioned earlier, the intention when testing the reliability and stability of BuildBuddy RBE was to avoid interfering with the default CI/CD flow. To achieve this, a new verification job called RBE BB Build/Tests was added. This verification triggers a Jenkins job on the new Gerrit CI, which builds the codebase and executes unit/integration tests on BuildBuddy RBE. This setup allowed the default flow and the BuildBuddy RBE flow to coexist without affecting each other.
It is important to note two things:
- Only revisions in the master branch of Gerrit project triggered this new verification job. The data collected from the master branch is sufficient to draw conclusions.
- The status of this new verification job does not affect the overall verification status of the revision.
Figure 2: Verification jobs, default ones and the BuildBuddy RBE, triggered in a Gerrit master branch revision:

Once the first phase concluded, it was important to analyze the data to determine if BuildBuddy RBE was reliable and stable enough to proceed to the next phase. In the second phase, the plan was to evaluate the performance of BuildBuddy RBE against GCP RBE. Architecturally, the CI/CD process remained the same as in the first phase, with one key difference: the verification job RBE BB Build/Tests would be triggered when revisions were created for the Gerrit repo on the master, stable-3.7, stable-3.8, and stable-3.9 branches. This was necessary to ensure that BuildBuddy RBE handled the same number of jobs as GCP RBE, allowing for a fair performance comparison.
Data Collection
Before analysing the data, it’s imperative to elucidate our data collection methodology. To procure the build data (build number, execution time in GCP RBE and BB RBE and status), we developed a script in python that employed two APIs:
- Gerrit Code Review – Rest API Query changes to list all the changes.
For example: https://gerrit-review.googlesource.com/changes/?q=project:gerrit+AND+not+dir:polygerrit-ui+AND+(branch:master)&o=CURRENT_REVISION
- Checks plugin – Rest API List of checks to list al the checks for a specific change number and revision number.
For example: https://gerrit-review.googlesource.com/changes/400398/revisions/1/checks
Notes:
- Build number is a unique number represented by the tuple: (change number, revision number).
- All the graphs show builds in chronological order.
- The build numbers are not shown in the graphs for readable purposes.
- Builds labelled as “RUNNING” or those lacking specification according to the API have been excluded from the calculations.
Key Performance Indicators
- Average Build Time: Calculate the average build time for each platform (GCP RBE and BuildBuddy RBE) to understand the typical time it takes to complete a build on each platform.
- Percentage of Builds Faster: Determine the percentage of builds that are completed faster on BuildBuddy RBE compared to GCP RBE. This helps assess which platform is more efficient in terms of build time.
- Overall Success Rate / Failure Rate: Calculate the overall success and failing rate of builds on BuildBuddy RBE. This considers both successful and failed builds to provide a comprehensive view of platform reliability.
- Outliers (>60 minutes): Identify the percentage of builds that exceed a certain threshold, such as 60 minutes in BuildBuddy RBE. This helps pinpoint builds that take exceptionally long and may require investigation or optimization.
- Average Build Time Reduction: Determine the average reduction in build time when using BuildBuddy RBE compared to GCP RBE. This quantifies the efficiency improvement gained by using the BuildBuddy platform.
PHASES
As we mentioned above, the migration has been segmented into two distinct phases:
Phase 1: Spanning from December 28th, 2023, to February 9th, 2024, during which RBE BuildBuddy operated against the Gerrit master branch.
Phase 2: Commencing from February 10th, 2024, to February 26th, during which RBE BuildBuddy operated against the Gerrit master, stable-3.7, stable-3.8, and stable-3.9 branches.
Phase 1: Evaluate if BuildBuddy RBE offers stability and low latency
To make the data more readable and understandable, I have split the data into 2 graphs:
Figure 3: RBE Successful Build time for Gerrit master between 28th December 2023 to 18th January 2024:

Figure 4: RBE Successful Build time for Gerrit master between 19th January 2024 to 9th February 2024:

Total number of builds:
| master | |
| GCP Builds | 489 |
| BB Builds | 489 |
Build status:
| BB Successful | BB failed | |
| GCP Successful | 390 | 17 |
| GCP Failed | 0 | 82 |
Initially, 3.47% of BuildBuddy RBE builds failed due to CPU exhaustion caused by running 100 BuildBuddy executors simultaneously. This problem was addressed by reducing the number of executors to 3. BuildBuddy engineers advise running only one executor container per host/node, with each executor capable of handling multiple RBE Actions concurrently. For each action, an executor initiates an isolated runner to execute it. We plan to reassess our configuration in due course.
Average build time when GCP and BuildBuddy builds were successful:
| Minutes | |
| GCP Average | 18.69 |
| BB Average | 10.2 |
Where the average build time reduction is 8.49 minutes and 96.4% (376 out of 390 builds) of BuildBuddy builds are faster than GCP builds.
We discovered that 1.5% of BuildBuddy successful builds were outliers. This was due to the need for a restart of the new Gerrit CI server, which caused temporary disruptions.
| change_number | REVISION_NUMBER | GCP RBE MINUTES | BB RBE MINUTES |
|---|---|---|---|
| 400398 | 1 | 6.7 | 868.68 |
| 399657 | 11 | 13.7 | 1293.55 |
| 399657 | 14 | 21.45 | 137.47 |
| 400958 | 2 | 14.52 | 154.3 |
| 247812 | 7 | 26.62 | 67.17 |
| 406597 | 1 | 14.18 | 79.55 |
Average time when GCP and BB Failed:
| Minutes | |
| GCP Average | 17.68 |
| BB Average | 23.29 |
Conclusions:
Assessing performance and stability, the results were promising, with the BuildBuddy platform showcasing superior performance, as highlighted in the table “Average build time when GCP and BB Successful”. Additionally, issues with BuildBuddy failing builds during successful GCP builds were addressed, primarily stemming from resolved configuration problems. Although outliers represented a mere 1.5%, their significance was negligible. However, despite these favourable outcomes, caution was warranted due to the higher volume of builds in GCP compared to BuildBuddy, attributed to GCP’s operation across stable branches.
Phase 2: Compare BuildBuddy RBE with GCP RBE based on performance
To make the data more readable and understandable, The data has been splitted into 4 graphs:
Figure 5: RBE Successful Build time for Gerrit master:

Figure 6: RBE Successful Build time for Gerrit stable-3.9:

Figure 7: RBE Successful Build time for Gerrit stable-3.8:

Figure 8: RBE Successful Build time for Gerrit stable-3.7:
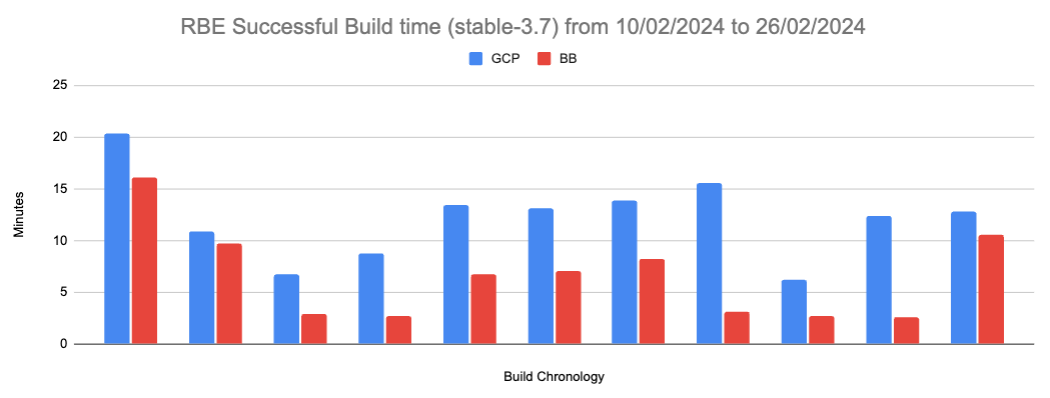
Successful BB Build status / Successful GCP Build status:
| master | stable-3.9 | stable-3.8 | stable-3.7 | Total | |
| Builds | 119 | 26 | 6 | 11 | 162 |
Average time when GCP and BB Successful:
| Minutes | |
| GCP Average | 13.91 |
| BB Average | 8.45 |
Where the average build time reduction is 5.46 minutes and 90.74% (147 out of 162 builds) of BuildBuddy builds are faster than GCP builds.
Failed BB Build states / Failed GCP Build status:
| master | stable-3.9 | stable-3.8 | stable-3.7 | Total | |
| Builds | 30 | 12 | 1 | 1 | 44 |
Failed BB Build status / Successful GCP Build status:
| master | stable-3.9 | stable-3.8 | stable-3.7 | Total | |
| Builds | 1 | 2 | 0 | 0 | 3 |
It is worth noting that 1.14% of BuildBuddy builds failed.
Average time when GCP and BB builds failed
| Minutes | |
| GCP Average | 10.96 |
| BB Average | 9.43 |
Conclusions:
The findings indicated that the BuildBuddy scenario demonstrated a more consistent performance, due to the on-premises allocated resources, as emphasised in the table “Average build time when GCP and BB Successful,” with comparable volumes of builds. Moreover, the stability remained highly consistent, evident from the table “Failed BB Build status / Successful GCP Build status,” alongside the absence of outliers.
Gerrit code review community decision
On February 27, 2024, the collected data was shared with the Gerrit code review open-source community. After careful consideration and thorough analysis, BuildBuddy was found to demonstrate remarkable stability. While it cannot be definitively stated that BuildBuddy surpasses GCP in all aspects, it notably outperforms GCP in terms of latency. Given its superior latency performance and strong stability, the decision was made to adopt BuildBuddy to replace GCP in the CI/CD pipeline.
Final migration phase
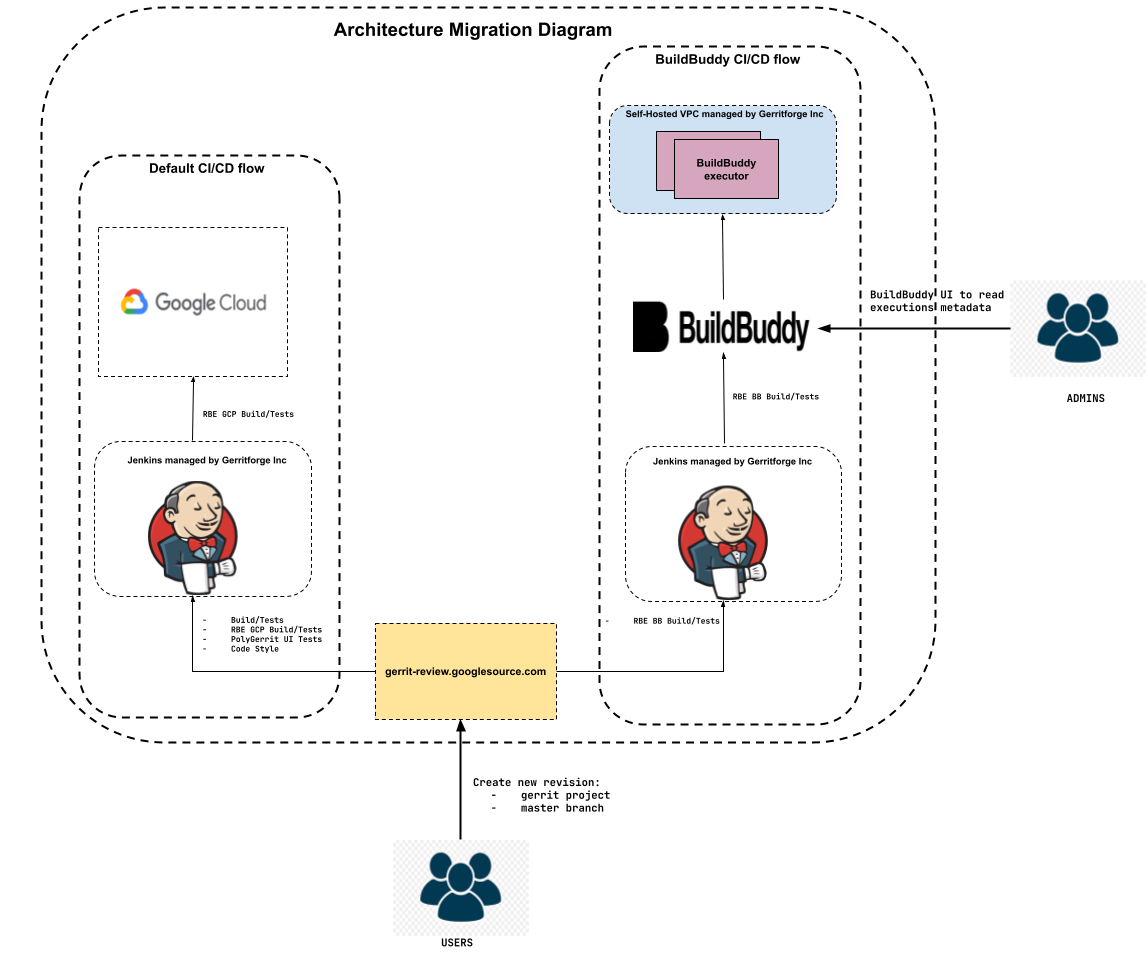
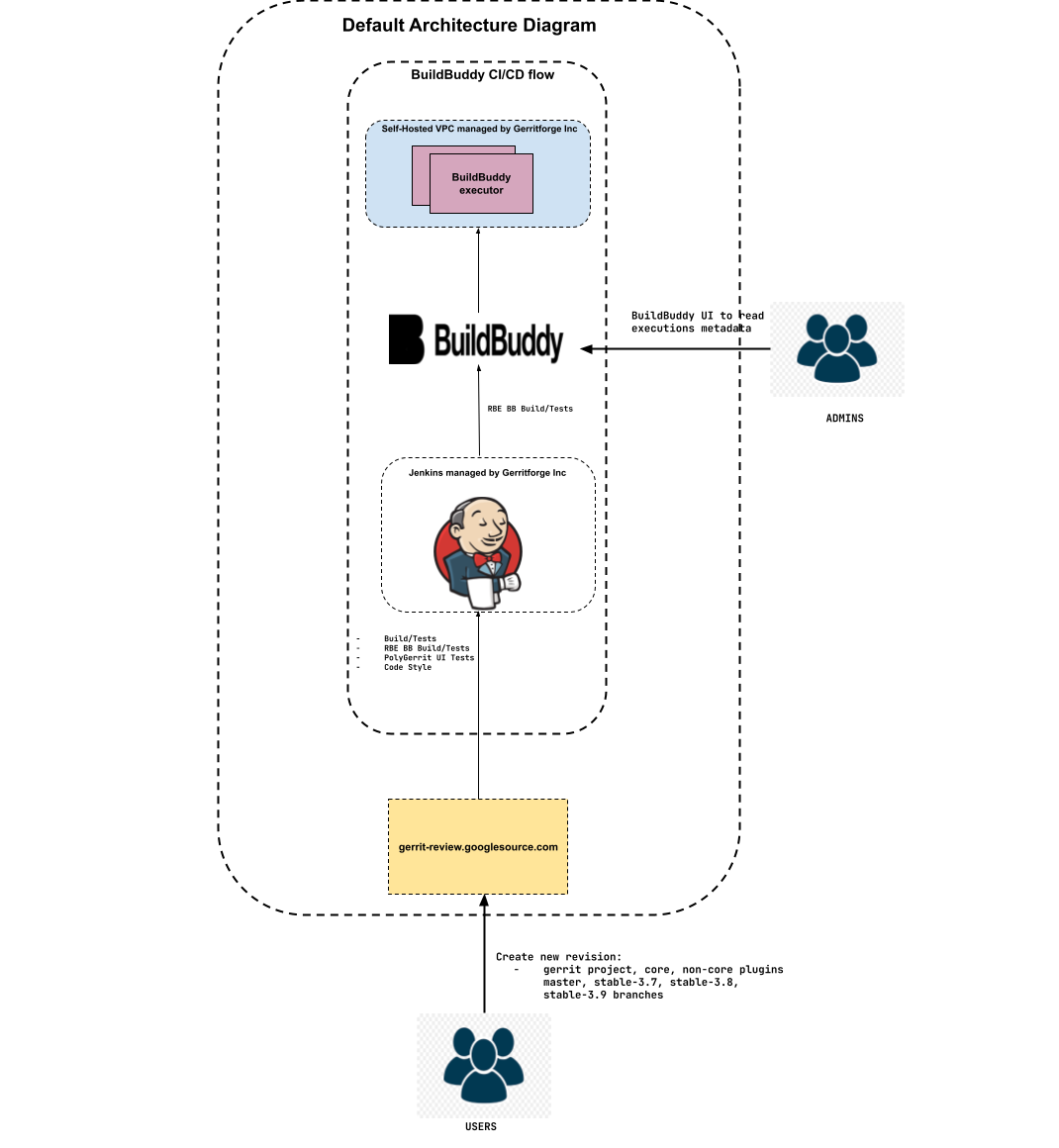
On March 29, 2024, the new Gerrit CI was established as the default CI using BuildBuddy RBE, and the following actions were taken:
- Decommissioned the old Gerrit CI server.
- Configured Gerrit CI to support both core and non-core plugin jobs, ensuring external visibility.
- Unregistered the Gerrit verification RBE GCP Build/Tests on gerrit-review.googlesource.com.
Figure 9: Default Architecture diagram with BuildBuddy CI/CD flow as default CI/CD flow:
Final Conclusions
Following the completion of the migration, data on BuildBuddy RBE was collected from May 1, 2024, to June 24, 2024, to validate all assumptions. Subsequent statistical analysis yielded the following results:
Figure 10: Successful Builds:
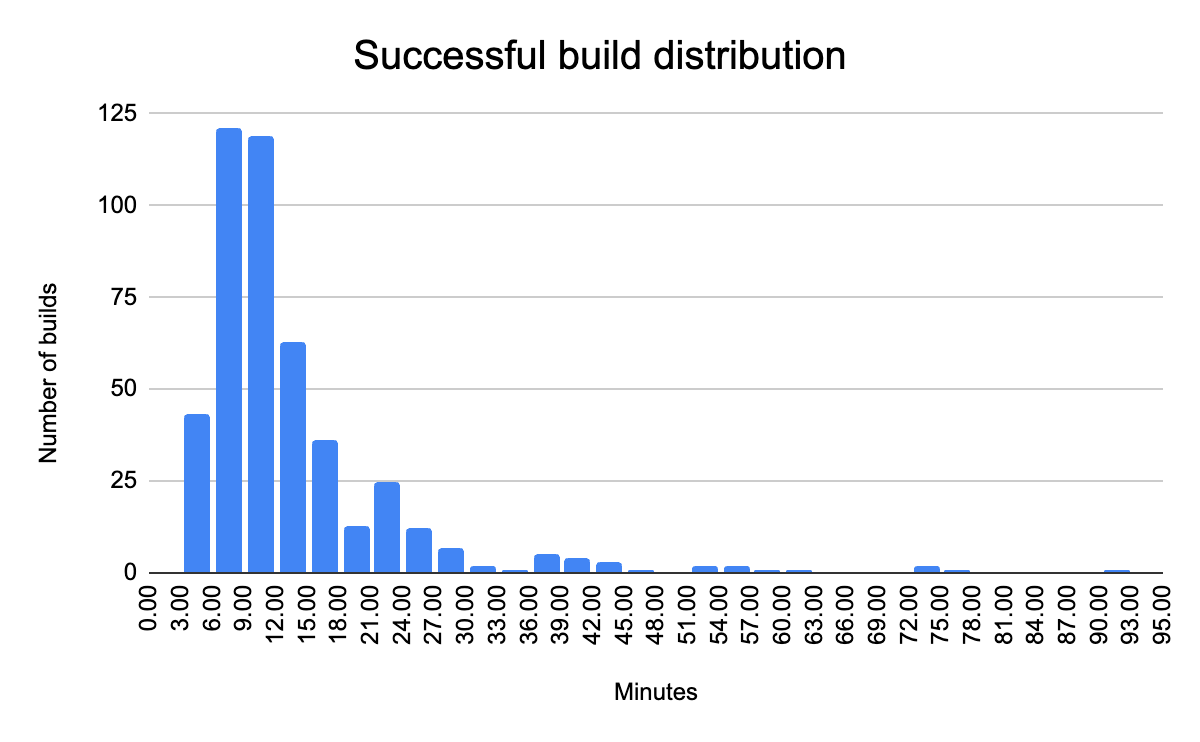
| Builds | 465 | |
| Mean | 13.62 min | |
| Median | 10.47 min | |
| Standard dev | 10.79 min | A higher standard deviation indicates that the build times are spread out over a wide range, meaning there is a lot of variability in the times |
| Q3 | 15.23 min | 75% of builds are completed in less than 15.23 minutes. |
Figure 11: Failed Builds:

| Builds | 105 | |
| Mean | 7.72 min | |
| Median | 6.22 min | |
| Standard dev | 7.56 min | |
| Q3 | 7.7 min | 75% of builds are completed in less than 7.7 minutes. |
While we are satisfied with our current results, we recognize the need for improvements in our successful builds. Our next step will be to analyze all the build data provided by the BuildBuddy dashboard, including target-level metrics, timing, artifacts, cache, and executions. This analysis will help us enhance the Bazel configuration and improve build performance.
Figure 12: BuildBuddy dashboard

Alvaro Vilaplana-Garcia – Gerrit Code Review Contributor
Luca Milanesio – Gerrit Code Review Maintainer and Release Manager