This week we are honored to publish the amazing talk of Gerrit Ver. 2.15 presented by Dave Borowitz, the “father” of NoteDb review format. It is the very first time that a full roadmap of the migration from the traditional ReviewDb (a relational DBMS) to NoteDb (a pure Git notes-based review store) is drawn and explained in all details.
First steps with Gerrit Ver. 2.15 using Docker
For all of those who want to experiment what Dave has presented at the Gerrit User Summit, there is a Gerrit Ver. 2.15 RC2 Docker image already published on DockerHub on https://hub.docker.com/r/gerritcodereview/gerrit.
See below the simple instruction on how to start a Gerrit 2.15 locally and playing with it.
Step 1 – Run Gerrit Docker image
$ docker run -h localhost -ti -p 8080:8080 -p 29418:29418 gerritcodereview/gerrit:2.15.rc2 ... [2017-11-14 23:12:08,016] [main] INFO com.google.gerrit.pgm.Daemon : Gerrit Code Review 2.15-rc2 ready
Step 2 – Open Gerrit UX
Open your web-browser at http://localhost:8080 and you will automatically get into the plugin manager selection. At the moment only the core plugins are available, so you can just click on to top right “Go To Gerrit” link.

As soon as Gerrit 2.15 will be officially available, you would be able to discover and install many more plugins on top of your installation.
Step 3 – Create a new Repository
Click on the new top “BROWSE” menu and select “CREATE NEW”

Then insert the repository name (e.g. “gerrit-playground”), select “Create initial empty commit” to True and click on “CREATE“.

Step 4 – Clone the repository
From the repository page select the “HTTP” protocol and click on the “COPY” link next of the “Clone with commit-msg hook” section.

And paste the command on your terminal.
$ git clone http://admin@localhost:8080/a/gerrit-playground && (cd gerrit-playground && curl -Lo `git rev-parse --git-dir`/hooks/commit-msg http://admin@localhost:8080/tools/hooks/commit-msg; chmod +x `git rev-parse --git-dir`/hooks/commit-msg) Cloning into 'gerrit-playground'... remote: Counting objects: 2, done remote: Finding sources: 100% (2/2) remote: Total 2 (delta 0), reused 0 (delta 0) Unpacking objects: 100% (2/2), done. Checking connectivity... done. % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 4695 100 4695 0 0 448k 0 --:--:-- --:--:-- --:--:-- 458k
Step 5 – Create a new commit for review
Enter into the new Git cloned repository “gerrit-playground”, add a README.md file.
$ cd gerrit-playground && echo "Hello Gerrit" > README.md && git add .
Then identify yourself as admin@example.com, which is the default Admin e-mail for the Gerrit 2.15 Docker image.
$ git config user.email admin@example.com
And finally create a new commit and push it to Gerrit using “secret” as password
$ git commit -m "Say hello to Gerrit" && git push origin HEAD:refs/for/master Password: secret [master b4de540] Say hello to Gerrit 1 file changed, 1 insertion(+) create mode 100644 README.md Counting objects: 3, done. Writing objects: 100% (3/3), 303 bytes | 0 bytes/s, done. Total 3 (delta 0), reused 0 (delta 0) remote: Processing changes: new: 1, done remote: remote: New Changes: remote: Say hello to Gerrit remote: To http://admin@localhost:8080/a/gerrit-playground * [new branch] HEAD -> refs/for/master
Step 6 – Review your Change in Gerrit
Open the Gerrit Change URL mentioned in the Git output (http://localhost:8080/#/c/gerrit-playground/+/1001) in your Web Browser and you can review the code using PolyGerrit UX.
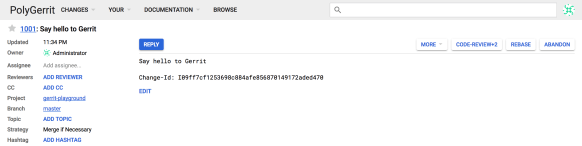
Step 7 – Approve and Submit your Change
Click on “CODE-REVIEW+2” button on the right toolbar to approve the change and then press “SUBMIT” to merge into the master branch.

What’s new in Gerrit Ver. 2.15
Hi, I’m Dave Borowitz, I work for Google, and I’m going to talk about what is new in Gerrit 2.15. We have a six months release cycle, and it has been around 158 days since Ver. 2.14.0 was released in April, and now, just last night at 10 PM, I have release 2.15-RC0.
Gerrit Ver. 2.15 in numbers
Gerrit Ver. 2.15 is aligned with other recent releases:
- 2,102 commits
- 53 contributors from all around the world and different companies
- seven new contributors who have never commit before
I don’t know if any of the new contributors are in this room and if they are, thank you, if not I will thank them remotely.
PolyGerrit frontend
There is a bunch of new stuff going on in Gerrit Ver. 2.15, I will talk only briefly about the frontend, because we had an excellent talk from Logan and Arnab and Justin this morning about what’s happened recently in PolyGerrit.
I want to give you my perspective as a developer that is doing mostly backend work. It’s fascinating to have in Gerrit a modern JavaScript environment to develop in because it has been historically difficult for us to attract frontend developers in the project. There are not just enough GWT developers in the world as there are JavaScript developers and I think that the Gerrit project has suffered from a lack of UI attention in the past because of that.
But now we have a whole team here at Google, we have a lot of external contributors, that are happy to work on modern JavaScript, and PolyGerrit has made some excellent strategies of improving the user experience.

PolyGerrit is also usable. Everyone that has been working in software development always has the attraction of starting from scratch and say “how would have done it differently, “: PolyGerrit follows a little bit that approach.
We understand that we have users that are used to a certain workflow and we have to preserve it. However, when you are writing new code, you have the opportunity to learn from your past mistakes and improve things and maybe make it easier to onboard new people.
There is a little bit of preview of what PolyGerrit looks like in Gerrit Ver. 2.15; I had to cut the screenshot last night to make sure that it would be entirely accurate.
You can see that there is a reasonable rate of improvements, even in the last 24h and I hope that we will keep this peace of development.
Backend
From Ver. 2.15 we support NoteDb, and we suggest that you should convert your existing ReviewDb to NoteDb.
What is the motivation for doing NoteDb? Until now the Gerrit administrators had to be DBMS Administrators as well which is a sort of weird feeling: you care about version control and software development workflow, and, for some reasons, you should take care about being a DB Admin?
The idea behind is that we carry on the data historically stored in ReviewDB and we move it directly into the Git repository.
When you create a new change with a patch-set, a topic and all its meta-data, including comments and reviewers then everything gets stored in the same Git repository with the rest of the committed change data. There are several advantages in storing data and meta-data in this way.
You don’t have to worry about two stores that somehow are going to get eventually inconsistent. If you have to make a backup of your Gerrit Server, you have to take a Database dump and then to have a backup of all of your repositories. If you want to have a consistent backup where everything that is stored in the Database exists in the Git repository and vice-versa, you have to do it while the server is down. There is no other way to do it because you may get new records in the database while you are backing up the Git repositories and you would not see that data reflected.
With NoteDb, it’s all in the Git repository, and it is even better because we changed JGit to be able to write to multiple Git repositories refs atomically atomically. This means you can submit a change and also submit the status of the meta-data at the same time. When you upload a patch-set, we update three refs, either all of them succeed, or all of them fail. There isn’t a state where the change was merged in the branch, but the ReviewDb wasn’t updated, that is just no longer possible. That enables us to have consistent backups.
NoteDb provides a very helpful audit log. We had a lot of data issues in the past where could not understand how a change got into a particular state because in ReviewDb you just update a field with ‘X’ and you forget completely that the field was previously with a value ‘Y.’ In Git the model you append commits to a history graph, so you actually store every operation that has ever happened on NoteDb, and that gives you an understanding on how a change ended in the current state.

We are thinking about giving extensibility for new features, and this is a kind of optimistic view about the future, plugins will be able to add new data to NoteDb while it wasn’t possible for a plugin to add a new column to an existing table of ReviewDb. I don’t think that we have any plugins that are currently able to leverage this capability and we do not have any extension for it yet, but the data layer supports it.
Whilst is automatically giving new features such as moving changes between Gerrit hosts without having to throw away code review meta-data.
NoteDb roadmap
We never actually pictured in the past a complete NoteDb timeline, which spreads across five long years.

- 2013
The very first commit on NoteDb was in December, that was a very long time ago. - 2014
We had an intern, and he wrote all the stuff on inline comments in NoteDb. - 2015
I wrote a thing that it was at the end a good idea in retrospective, but it was a considerable amount of work. It is called the batch update and allows to have a coordinated transaction across two different data-store with a consistent interface. This period is what I called “rewrite every single line of Gerrit”. - 2016
We started migrating googlesource.com; ReviewDb still existed, and it was always the single source of truth in case they got out of sync with NoteDb. Later this year, a few months ago, we moved everything to NoteDb and we don’t use the change table anymore. We have several hundreds of servers nowadays using NoteDb and generated several hundreds of changes to it. That is exciting, we have been running in production for months, and that’s why we believe it could work for other people to run in production. - 2017
Last night, we released Ver. 2.15, the first version of Gerrit where we officially say “we officially support NoteDb and we encourage you to migrate away from ReviewDb.” - 2018
We are going to release Gerrit Ver. 3.0 and Ver. 3.1. The reason for the name ‘3.0’ is because we will not have ReviewDb anymore. There will still be the code and the ability to migrate from ReviewDb to NoteDb, but you would not be able to run Gerrit on ReviewDb. The Ver. 3.1 is the one I am most excited about because in that version we do not have even to support a migration tool. We will then be able to throw away all the ReviewDb code, and that would make me very happy.
How to migrate from ReviewDb to NoteDb
I mentioned that migration for googlesource.com took us a very long time because we’ve found a ton of issues with our data. We discovered all these things while we were running our migration and we fixed them all.
We developed a system that was scanning all ReviewDb, performed an in-memory migration and then compared the result with the changes stored in NoteDb. One example of a bug was that some subjects were truncated in ReviewDb. The subject is supposed to come from the first line of the commit message. We were comparing the data in Git with the data in ReviewDb and they did not match because they were truncated. If we were to require that all the subjects in NoteDb were identical to the ones in ReviewDb we would have never passed because there was this truncation. We could have patched all the existing data but actually what we did is to consider that if the subject in NoteDb starts with the subject in ReviewDb it was then regarded as valid. There were many more bugs of that flavor.
There were also bugs in the NoteDb code that we fixed; it was not just like all related to not good data; my code was far from being bug-free. The reason why I am talking about how much effort we put in making it right is that I want you to feel confident and not think about that this is a so much scary operation on your data. We tested on ourselves, and we fixed a lot of these bugs, and we are still pretty confident that this is a safe operation.
In Ver. 2.15 there are two types of migration options: on-line and off-line. At Google, we are in an exceptional condition because we are always at zero downtime, but that was useful because it allowed us to write a tool for a live migration from ReviewDb to NoteDb while the server is running.
Migration to NoteDb is pretty much similar to the way you do reindex: there is an online reindex and an offline reindex. You can choose to do it offline, and it will be probably faster, but there will be a downtime. Or you can decide to do it online, and it will be slower, but there will be no downtime.
And then in Ver. 3.0 we only are going to support an off-line migration, following the same paradigm of all the other schema upgrades. If you skip between releases, we force you to do to an off-line update, but if you upgrade just one point release at a time, you don’t have to have any downtime for your schema migration. Similarly for NoteDb if you migrate from Ver. 2.14 to Ver. 2.15 and then Ver. 3.0, you won’t have any downtime.

Q: (Han-Wen) Is this process parallel?
A: It is parallel if you do it offline if you do it online it is using a single thread because we are assuming that your server is mostly busy doing other stuff and that’s why you may want to do an online migration in the first place.
Benefits of migrating to NoteDb
There are a lot of incentives to migration to NoteDb; one is that you have new features such as hashtags and others that we implemented only in NoteDb because they were a lot harder in ReviewDb such as the history of all reviewers on a change. NoteDb manages audit natively while on ReviewDb we would have needed to have a new table called reviewers_audit which would have been much harder to implement.
The robot comments introduced in Ver. 2.14, the ability to remove clutter in your dashboard to mark a change as reviewed, are all features that you only have in NoteDb.
What did we learn from migration to NoteDb?
Writing every single line of code just takes a long time, and Gerrit has hundreds of thousands of lines of code. Shawn Pearce, my manager, and the Gerrit project founder at Google, every time he needs to touch NoteDb related code just says “I don’t even recognize this, ” and he is still the contributor #1 in the project. We changed it almost beyond its recognition.
Everything I’ve said so far is about changes; there are also other data besides changes. Accounts have been unconditionally migrated to NoteDb in Ver. 2.15. Is more a git config file format for the accounts that we store in NoteDb, it is not even actually a Note-space format. The account is now a config file that has your name and your e-mail address and the status, which is a new feature in NoteDb. For instance, my account status says that “I having a talk in England”.
New Patch-set comparison
Hi, my name is Alice Kober-Sotzek, and I work at Google. In Ver. 2.15 we have changed the way we compared patch-sets. Let’s imagine we have just a small change with a patchset and two files on it. In the first file we have only the first line modified, and the file consists of one thousand lines. The second file has four lines changed.
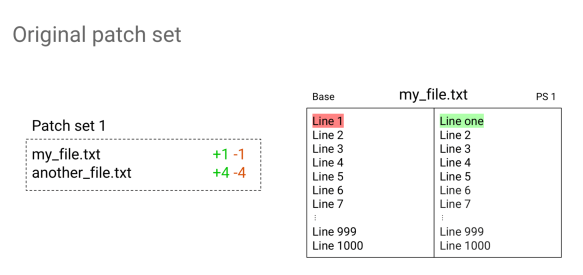
Let’s see what happens now when I rebased it to the latest version of master. If I had now to visualize what the patchset 1 consisted of and patchset 2 consisted of, what would I assume it would be? If I had been the author of the change, I would have expected that only one line would have been changed. Let’s just do it and ask Gerrit Ver. 2.14 what the result is.
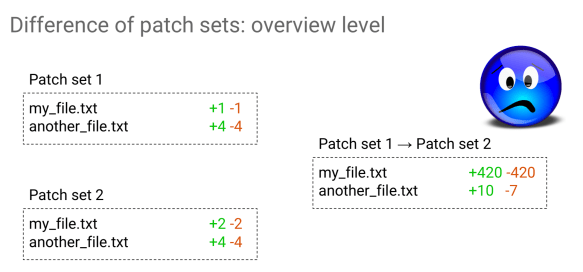
What’s happening? Why do I have 420 lines changed in my file and ten additions and seven removals on the other?
That was not even touched on. Let’s have a look at the content of my file and what is in there.
In Ver. 2.14 we were just hiding all the differences due to rebasing, and that was it. In Ver. 2.15 things look different though because we try to figure out what happened in between the rebase. All the hanks that we are sure are added by something else, are displayed in a different color. We have not only red and green but orange and blue as well; these are all the ones that were introduced by other changes that were in between rebase.
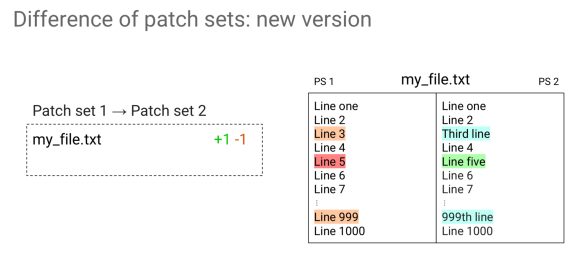
This feature only works in PolyGerrit, while in GWT was not shown at all.
Can I rely on that and trust what I see there?
The decision we made is that all the hunks marked with orange and blue are the ones we are sure of and you can safely avoid looking at them because they were the ones that happened because of other changes occurring in between rebase.
The ones marked with red and green, we give no guarantee. They could be introduced by other changes, because of conflicts or may be added by the patchset. With that coloring, it is much easier to look at the things that are important.

Killing Draft Changes.
Some of the people think that draft changes are very much a visibility thing so that only my reviewers can see them. Other people use it like a change is not yet ready for review so that I can leave it as draft change until it is ready for being reviewed. You may even just use the server as a store for your changes; rework the code through the Gerrit in-line edit feature until the code is ready and then come up with an absurd number of patchsets. Nobody wanted any of them, but those are the conditions that we ended up with patchset drafts.
Patchsets could have been even deleted so they would never exist. They could just be kept invisible so that you see a gap, but that could be the current patchset: the UI claims that the current patchset is three, but then I do some other operations that say that this patchset is not current anymore, just because the current one is a draft!

Drafts are a kind of mass fraud; the main reason is that they are colliding all these things into a single feature. In Gerrit Ver. 2.15 we killed drafts. Now you have little small features instead of drafts. You have now “Private Changes” which only you and your reviewers can see. There are Work-In-Progress (WIP) changes, that means that while the WIP flag is set nobody gets notifications about it: you can push 30 patchsets, and the reviewers would not get spammed with 30 emails. Last but not least, we introduced a long ago the Change Edit, which can be used as well in conjunction with WIP Changes.
Marking Changes as reviewed
Another thing that we introduced in Ver. 2.15 is the ability to mark changes as you reviewed it. For instance, the one below is a change screen from my dashboard this morning: some changes are highlighted in bold and those other changes are not. I feel like the bold changes are yelling at me and you have to give me your attention just like in e-mails where bolds means “you need to look at me now.” Gerrit Ver. 2.15 when you are using NoteDb allows you to unbold any of them by just clicking a button on the change screen. Or like in an email you wish to remove some changes from your dashboard entirely. There is a function that allows you remove a change unilaterally from your dashboard that the other cannot undo or ignore it, that just makes the change go away.
It was annoying that I could not mark them as reviewed manually and it was really irritating that patchsets disappeared. It is really irritating when I received a review with a bunch of comments, I had to say “done, done, done, done” on each one of them.
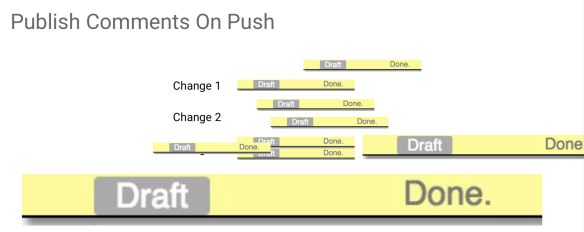
And then when I pushed a new patchset, I just forgot to submit all these drafts comments that say “done”. So I added just a push option that says “when you push, publish comments” and all the draft comments will be published automatically. So instead of clicking on all the patchset on that change and check if in any of the patchset I have any draft and if I do, click send on all of them one by one, I can instead just set an option.

It can be specified by the command line, but it is difficult to remember. So there is a user preference with a checkbox which I really encourage you to select in your user preferences screen and it is only available on PolyGerrit.
CCing a Change under review
When someone is getting a co-worker and they want him to be a reviewer for a change, you get an error saying that your co-worker is not a registered user. We have partially solved this problem by adding a CC with an e-mail address, also only available on NoteDb. There are technical and even product reasons why we don’t want to add them as a reviewer, some of them are related to the accountability related to everyone that is working on that change. So people needs to have an account to be a reviewer, but if people just want to look at it or a mailing list, it doesn’t have to be a real user, you can then just CC any e-mail to a code review if you turn the config option to allow this.

Better error messages.
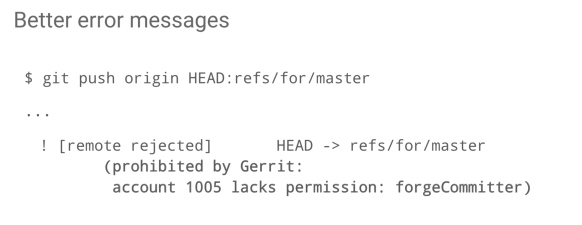
Another inch that Han-Wen scratched was the introduction of better error messages. Sometimes you do a push, and it fails with a very unhelpful error message that says “Prohibited by Gerrit.”
It turns out that it is not difficult to check if a user does not have a permission then gives permissions error, so we have included a message saying this user lacks this permission. It is not perfect, so it doesn’t say precisely where in the project hierarchy this permission was coming from but at least says “this is the problem”, it tells you not the solution but at least highlights where the problem is.
Robot comments and automatic fixes.
Robot comments are a feature that we believe it will start to rump up in adoption. With NoteDb, you can suggest fixes as well, and then you have a button that says “apply fixes” which creates a change that applies the fixes.
Many more improvements in the bag.
There is a lot of speed improvements in PolyGerrit, so the changes with a lot of diffs will run a lot faster. An admin can delete comments that really shouldn’t be there. We can explicitly keep track that a change reverts another change so that you can search if that change was reverted. It can even tell you if that was a pure revert at Git level only, or if other changes were sneaked in claiming that this was only a revert which happens way too often I think.
There are a better server consistency checks and a new plugin endpoint for dashboards; there is a new URL scheme as described by Patrick and we are now off the page for putting, even more, new features.