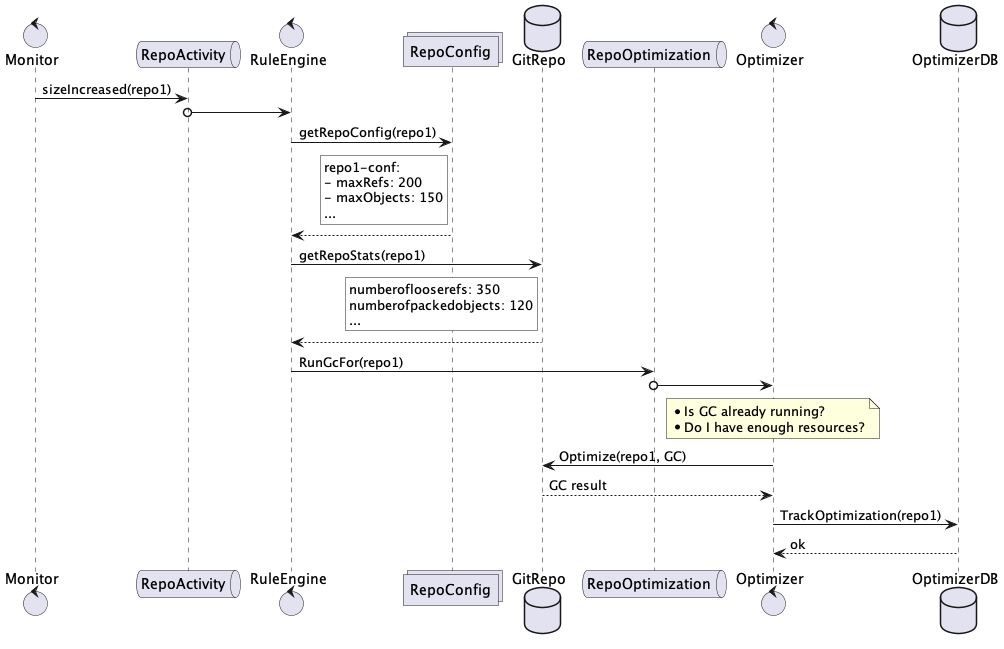
Gerrit Code Review is unstoppable: despite the recent COVID-19 pandemic and the cancellation of the Spring Hackathon 2020, the community has made an extraordinary effort to deliver remotely and on-time the Gerrit v3.2 release on the 1st of June.
GerritForge has already migrated GerritHub.io on the day-1 of the release and is happy to share with you the highlights of this new release. If you need help to assess your current setup and migrating, please get in touch with us at https://gerritforge.com/contact.
Get ready to migrate: get rid of zombie comments
The migration process performs the cleanup of the zombie draft comments in the All-Users.git repository that has been left behind since the introduction of NoteDb back in v2.16.
Every user commenting on any change was creating a series of commits on the All-Users.git repository, where the draft comments are stored. Once the comments were finalised and applied to the change, they were not fully removed from the All-Users.git. That created a backlog of zombie comments on All-Users.git that are now being completely removed during the Gerrit v3.2 migration process.
Since Gerrit v2.16.16, there is a standalone utility to remove the zombie draft comments. You may want to do that operation upfront to make sure that the migration to v3.2 does not have a lot of processing during the init step. Also, make sure that the All-Users.git resides on a fast access local filesystem for minimizing the migration time.
If you do nothing, the cleanup utility will be automatically executed when migrating to Gerrit v3.2, bearing in mind that it may take quite a long time to complete. In our tests, it took around 10 minutes for 10k zombie comments.
WARNING: the execution time is not linear and it may take up to 48h of processing time for a staggering number of 1M zombie comments.
Migrate with zero-downtime
If you have on Gerrit v3.1.x in a high-availability configuration, you can upgrade seamlessly to Gerrit v3.2, without having to suspend or degrading the service in any way. GerritForge has a record number of installations done in high-availability and multi-site: if you are running a single Gerrit master today, you should get in touch with the GerritForge Team to help moving to high-availability.
For the very first time, the whole Gerrit Community can benefit from the ability to perform a rolling upgrade without any downtime.
The zero-downtime upgrade consists of the following steps:
- Have Gerrit masters upgraded to v3.1.6 (or later) in a high-availability configuration, healthy and able to handle the incoming traffic properly.
- Set gerrit.experimentalRollingUpgrade to true in gerrit.config on both Gerrit masters.
- Set the first Gerrit master unhealthy.
- Shutdown the first Gerrit master and then upgrade to v3.2.
- Startup the first Gerrit master and wait for the on-line reindex to complete.
- Please verify that the first Gerrit master is working correctly and then make it healthy again.
- Wait for the first Gerrit master to start serving traffic regularly.
- Repeat steps 3. to 7. for the second Gerrit master.
- Remove gerrit.experimentalRollingUpgrade from gerrit.config on both Gerrit masters.
NOTE: Gerrit v3.1.6 has not been released yet. However, if you want to perform a rolling upgrade today, you can download the latest build on the stable-3.1 branch from the GerritForge’s CI at https://gerrit-ci.gerritforge.com/job/Gerrit-bazel-stable-3.1/
GerritHub.io has been successfully upgraded on the 1st of June without any interruption of any kind using the above procedure.
Java 11 official support
Gerrit is now officially supported on Java 11, in addition to Java 8. Running on Java 11 was already possible from v2.16.13, v3.0.4 and v3.1.0, but not officially supported because of the lack of a CI validation on Java 11 for stable-2.16, stable-3.0 and stable-3.1 branches.
Gerrit v3.2 has been validated with Java 11, with the following known issues:
- Issue 11567: Java 11 runtime & startTLS LDAP broken: ‘error code 8 – BindSimple: Transport encryption’.
- Issue 12639: WARNING: An illegal reflective access operation has occurred, when starting Gerrit.
After 24h of adoption of Gerrit v3.2 on GerritHub.io, we have seen two major benefits from the migration to Java 11: overall reduction of the “old generation” build up in the JVM heap and massive reduction of GC cycles times and full-GCs.

Before the 29th of May, all GerritHub.io nodes were on Gerrit v3.1 / Java8. The old-generation JVM heap keeps on building up constantly until it reaches the 60GB and triggers a full GC cycle. After the upgrade to Gerrit v3.2 / Java11, memory consumption is very much under control. There are still possibilities of peaks with associated full GCs (see the one on the 30th of May around 12:00 BST) but there isn’t build up of old-generation objects anymore.
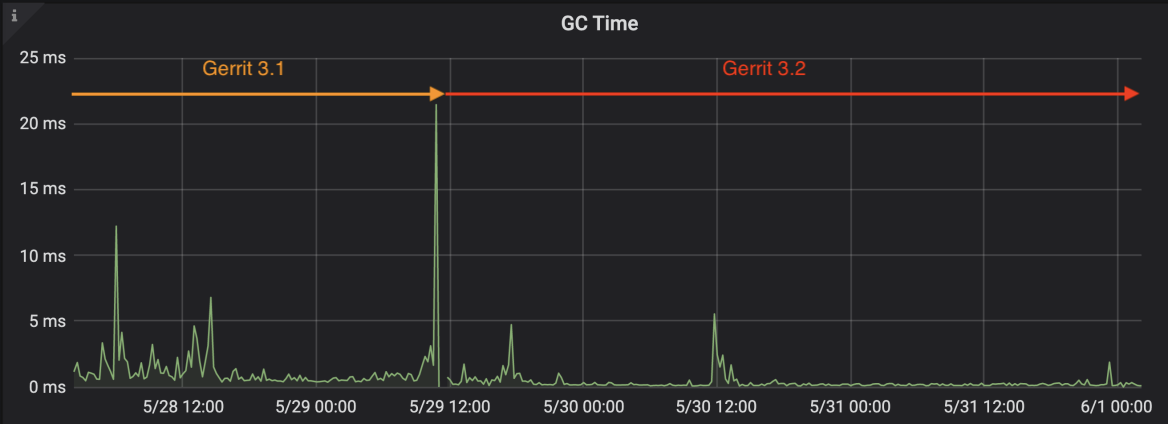
Java11 brings a lot of benefits also in reducing the latency of the individual GC cycles, showing much better performance with large heaps.
After the migration on the 29th of May, the GC graph is pretty much flat. The only full GC peak that is noticeable on the 30th of May lasted for just 5 msecs while the normal GC cycles are well below 1 msec, barely noticeable.
Performance is a feature
Shawn Pearce, the Gerrit Code Review project founder, used to say “performance is a feature”, which is very true. Any software nowadays can provide some basic out of the box features, thanks to the plethora of open-source components available out of the box. However, designing architecture and making it scale and perform to the levels that an Enterprise Code Review system needs, it is not easy.
Gerrit v3.2 is yet another significant milestone in the continued effort of the Gerrit maintainers and contributors in making Gerrit Code Review faster, more stable and available than ever before.
Performance tuning isn’t a “one-off task” but is a continuous improvement on thousands of little details ranging from the front-end javascript tuning down to the backend of the platform.
New accounts cache
From the data collected on googlesource.com Patrick Hiesel (Google) has identified the accounts loading from NoteDb as a significant cause of the delay of backend calls. That is true for all Gerrit installations, but especially for distributed setups or setups that restart often.
Gerrit v3.2 introduces a brand-new AccountCache decomposed into smaller chunks that can be cached individually:
- External IDs + user name (cached in ExternalIdCache)
- CachedAccountDetails (newly cached)
- Gerrit’s default settings CachedAccountDetails – a new class representing all information stored under the user’s ref (refs/users/<sharded-id>).
The new structure is cleverly designed to require a lot less I/O when an entry needs to be reloaded and lowering the ratio of cache-miss in case of user’s details updates.
The new structure has the following advantages:
- CachedAccountDetails contains only details from refs/users/<sharded-id>. By that, we can use the SHA1 of that ref as cache key and start serializing the cache to eliminate cold start penalty as well as router assignment change penalty (for distributed setups). It also means that we don’t have to do invalidation ourselves anymore.
- When the server’s default preferences change, we don’t have to invalidate all accounts anymore.
- The projected speed improvements that come from persisting the cache makes it so that we can remove the logic to load accounts in parallel.
Migration to Polymer 3
PolyGerrit UX roadmap continues with yet another important milestone: the migration to Polymer 3. The result is visible with an improved polishing of the GUI and significant speedup of rendering and reduction of page loading times.
There are a significant amount of small refinements to the GUI as well, coming from a meticulous work of fixes included in this release.
Not by surprise, the number of issues fixed in v3.2 on the PolyGerrit UX outnumbers by far the overall changes in the release notes.

PolyGerrit is giving special attention to the classification of the feedback coming from robots rather than humans.
Most of the efforts made in the past 12 months target the improvement the support for robot-comments and giving some extra dedicated space for them.
In Gerrit v3.2 there is a special place for them in a brand-new “Findings” tab. It is currently empty on GerritHub.io as people did not start using them much. However, I do see a lot of space of adoption of this new feature, giving the ability for more integration of linters and automatic validation feedback in this tab.
A flooding of fixes and small improvements
The list of fixes and improvements in Gerrit v3.2 is really huge. Please check the release notes on the Gerrit Code Review release page for all the details.
There are a lot of reasons to migrate to Gerrit v3.2, the fastest, more stable and scalable release of Gerrit Code Review ever.
Thanks a lot to the whole Gerrit Code Review Community of maintainers and contributors for making this release happen. Thanks to Patrick Hiesel for the technical description of the account cache improvements and the replication clustering.
Luca Milanesio (GerritForge)
Gerrit Code Review Maintainer, Release Manager, ESC Member